 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Deepfake
Apr 02, 2024
Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
DesignEdit: Multi-Layered Latent Decomposition and Fusion for Unified & Accurate Image Editing
Mar 21, 2024
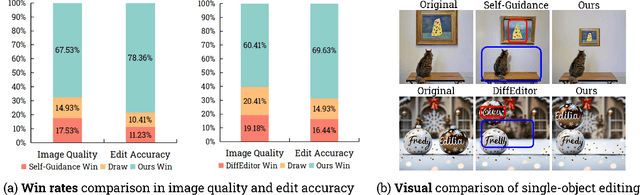

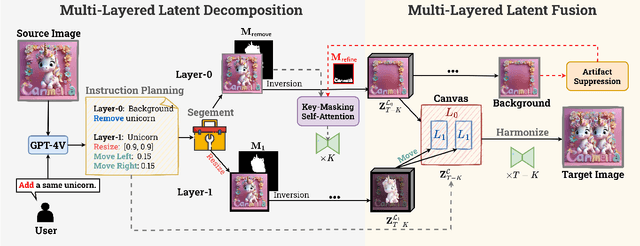
Recently, how to achieve precise image editing has attracted increasing attention, especially given the remarkable success of text-to-image generation models. To unify various spatial-aware image editing abilities into one framework, we adopt the concept of layers from the design domain to manipulate objects flexibly with various operations. The key insight is to transform the spatial-aware image editing task into a combination of two sub-tasks: multi-layered latent decomposition and multi-layered latent fusion. First, we segment the latent representations of the source images into multiple layers, which include several object layers and one incomplete background layer that necessitates reliable inpainting. To avoid extra tuning, we further explore the inner inpainting ability within the self-attention mechanism. We introduce a key-masking self-attention scheme that can propagate the surrounding context information into the masked region while mitigating its impact on the regions outside the mask. Second, we propose an instruction-guided latent fusion that pastes the multi-layered latent representations onto a canvas latent. We also introduce an artifact suppression scheme in the latent space to enhance the inpainting quality. Due to the inherent modular advantages of such multi-layered representations, we can achieve accurate image editing, and we demonstrate that our approach consistently surpasses the latest spatial editing methods, including Self-Guidance and DiffEditor. Last, we show that our approach is a unified framework that supports various accurate image editing tasks on more than six different editing tasks.
ReNoise: Real Image Inversion Through Iterative Noising
Mar 21, 2024
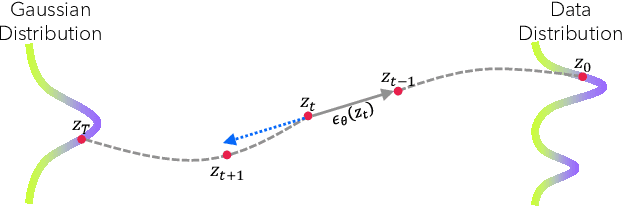
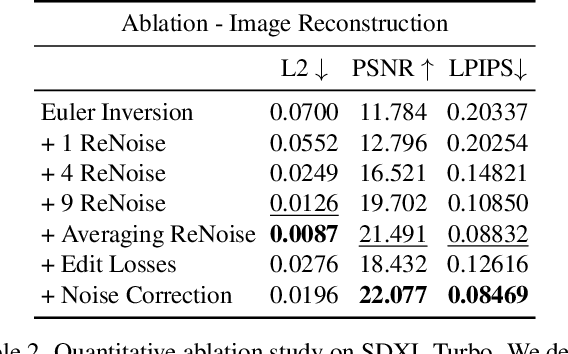

Recent advancements in text-guided diffusion models have unlocked powerful image manipulation capabilities. However, applying these methods to real images necessitates the inversion of the images into the domain of the pretrained diffusion model. Achieving faithful inversion remains a challenge, particularly for more recent models trained to generate images with a small number of denoising steps. In this work, we introduce an inversion method with a high quality-to-operation ratio, enhancing reconstruction accuracy without increasing the number of operations. Building on reversing the diffusion sampling process, our method employs an iterative renoising mechanism at each inversion sampling step. This mechanism refines the approximation of a predicted point along the forward diffusion trajectory, by iteratively applying the pretrained diffusion model, and averaging these predictions. We evaluate the performance of our ReNoise technique using various sampling algorithms and models, including recent accelerated diffusion models. Through comprehensive evaluations and comparisons, we show its effectiveness in terms of both accuracy and speed. Furthermore, we confirm that our method preserves editability by demonstrating text-driven image editing on real images.
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
Atom-Level Optical Chemical Structure Recognition with Limited Supervision
Apr 02, 2024Identifying the chemical structure from a graphical representation, or image, of a molecule is a challenging pattern recognition task that would greatly benefit drug development. Yet, existing methods for chemical structure recognition do not typically generalize well, and show diminished effectiveness when confronted with domains where data is sparse, or costly to generate, such as hand-drawn molecule images. To address this limitation, we propose a new chemical structure recognition tool that delivers state-of-the-art performance and can adapt to new domains with a limited number of data samples and supervision. Unlike previous approaches, our method provides atom-level localization, and can therefore segment the image into the different atoms and bonds. Our model is the first model to perform OCSR with atom-level entity detection with only SMILES supervision. Through rigorous and extensive benchmarking, we demonstrate the preeminence of our chemical structure recognition approach in terms of data efficiency, accuracy, and atom-level entity prediction.
Noisy Label Processing for Classification: A Survey
Apr 05, 2024In recent years, deep neural networks (DNNs) have gained remarkable achievement in computer vision tasks, and the success of DNNs often depends greatly on the richness of data. However, the acquisition process of data and high-quality ground truth requires a lot of manpower and money. In the long, tedious process of data annotation, annotators are prone to make mistakes, resulting in incorrect labels of images, i.e., noisy labels. The emergence of noisy labels is inevitable. Moreover, since research shows that DNNs can easily fit noisy labels, the existence of noisy labels will cause significant damage to the model training process. Therefore, it is crucial to combat noisy labels for computer vision tasks, especially for classification tasks. In this survey, we first comprehensively review the evolution of different deep learning approaches for noisy label combating in the image classification task. In addition, we also review different noise patterns that have been proposed to design robust algorithms. Furthermore, we explore the inner pattern of real-world label noise and propose an algorithm to generate a synthetic label noise pattern guided by real-world data. We test the algorithm on the well-known real-world dataset CIFAR-10N to form a new real-world data-guided synthetic benchmark and evaluate some typical noise-robust methods on the benchmark.
AdaIR: Adaptive All-in-One Image Restoration via Frequency Mining and Modulation
Mar 21, 2024
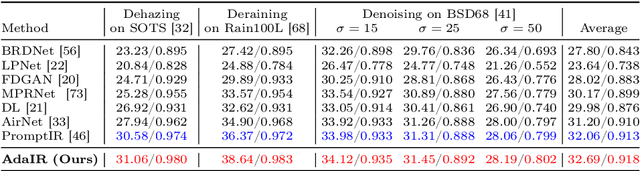
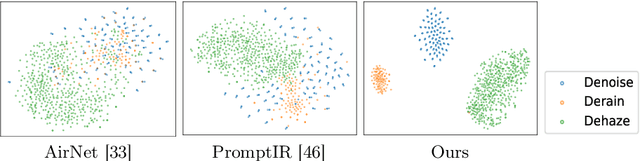

In the image acquisition process, various forms of degradation, including noise, haze, and rain, are frequently introduced. These degradations typically arise from the inherent limitations of cameras or unfavorable ambient conditions. To recover clean images from degraded versions, numerous specialized restoration methods have been developed, each targeting a specific type of degradation. Recently, all-in-one algorithms have garnered significant attention by addressing different types of degradations within a single model without requiring prior information of the input degradation type. However, these methods purely operate in the spatial domain and do not delve into the distinct frequency variations inherent to different degradation types. To address this gap, we propose an adaptive all-in-one image restoration network based on frequency mining and modulation. Our approach is motivated by the observation that different degradation types impact the image content on different frequency subbands, thereby requiring different treatments for each restoration task. Specifically, we first mine low- and high-frequency information from the input features, guided by the adaptively decoupled spectra of the degraded image. The extracted features are then modulated by a bidirectional operator to facilitate interactions between different frequency components. Finally, the modulated features are merged into the original input for a progressively guided restoration. With this approach, the model achieves adaptive reconstruction by accentuating the informative frequency subbands according to different input degradations. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on different image restoration tasks, including denoising, dehazing, deraining, motion deblurring, and low-light image enhancement. Our code is available at https://github.com/c-yn/AdaIR.
Overfitted image coding at reduced complexity
Mar 18, 2024Overfitted image codecs offer compelling compression performance and low decoder complexity, through the overfitting of a lightweight decoder for each image. Such codecs include Cool-chic, which presents image coding performance on par with VVC while requiring around 2000 multiplications per decoded pixel. This paper proposes to decrease Cool-chic encoding and decoding complexity. The encoding complexity is reduced by shortening Cool-chic training, up to the point where no overfitting is performed at all. It is also shown that a tiny neural decoder with 300 multiplications per pixel still outperforms HEVC. A near real-time CPU implementation of this decoder is made available at https://orange-opensource.github.io/Cool-Chic/.
Denoising Low-dose Images Using Deep Learning of Time Series Images
Mar 31, 2024Digital image devices have been widely applied in many fields, including scientific imaging, recognition of individuals, and remote sensing. As the application of these imaging technologies to autonomous driving and measurement, image noise generated when observation cannot be performed with a sufficient dose has become a major problem. Machine learning denoise technology is expected to be the solver of this problem, but there are the following problems. Here we report, artifacts generated by machine learning denoise in ultra-low dose observation using an in-situ observation video of an electron microscope as an example. And as a method to solve this problem, we propose a method to decompose a time series image into a 2D image of the spatial axis and time to perform machine learning denoise. Our method opens new avenues accurate and stable reconstruction of continuous high-resolution images from low-dose imaging in science, industry, and life.
Few-shot point cloud reconstruction and denoising via learned Guassian splats renderings and fine-tuned diffusion features
Apr 04, 2024Existing deep learning methods for the reconstruction and denoising of point clouds rely on small datasets of 3D shapes. We circumvent the problem by leveraging deep learning methods trained on billions of images. We propose a method to reconstruct point clouds from few images and to denoise point clouds from their rendering by exploiting prior knowledge distilled from image-based deep learning models. To improve reconstruction in constraint settings, we regularize the training of a differentiable renderer with hybrid surface and appearance by introducing semantic consistency supervision. In addition, we propose a pipeline to finetune Stable Diffusion to denoise renderings of noisy point clouds and we demonstrate how these learned filters can be used to remove point cloud noise coming without 3D supervision. We compare our method with DSS and PointRadiance and achieved higher quality 3D reconstruction on the Sketchfab Testset and SCUT Dataset.