 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023
The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
An Enhanced Low-Resolution Image Recognition Method for Traffic Environments
Sep 28, 2023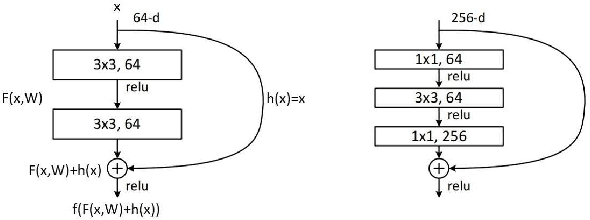
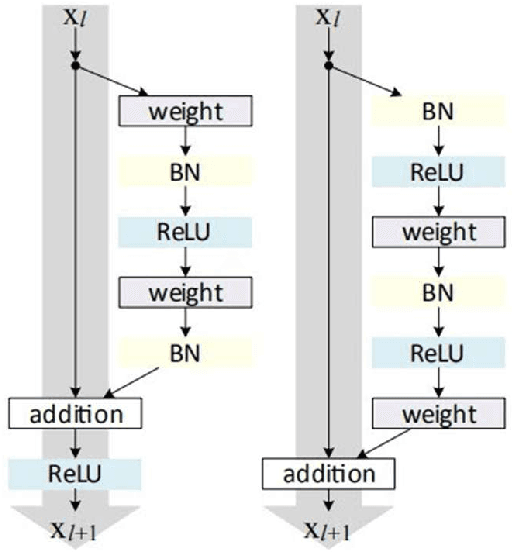
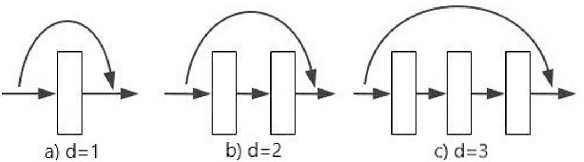
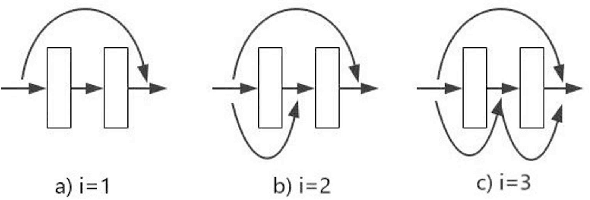
Currently, low-resolution image recognition is confronted with a significant challenge in the field of intelligent traffic perception. Compared to high-resolution images, low-resolution images suffer from small size, low quality, and lack of detail, leading to a notable decrease in the accuracy of traditional neural network recognition algorithms. The key to low-resolution image recognition lies in effective feature extraction. Therefore, this paper delves into the fundamental dimensions of residual modules and their impact on feature extraction and computational efficiency. Based on experiments, we introduce a dual-branch residual network structure that leverages the basic architecture of residual networks and a common feature subspace algorithm. Additionally, it incorporates the utilization of intermediate-layer features to enhance the accuracy of low-resolution image recognition. Furthermore, we employ knowledge distillation to reduce network parameters and computational overhead. Experimental results validate the effectiveness of this algorithm for low-resolution image recognition in traffic environments.
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023
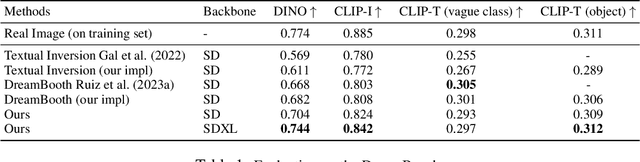

Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.
Multiclass Segmentation using Teeth Attention Modules for Dental X-ray Images
Nov 07, 2023This paper proposed a cutting-edge multiclass teeth segmentation architecture that integrates an M-Net-like structure with Swin Transformers and a novel component named Teeth Attention Block (TAB). Existing teeth image segmentation methods have issues with less accurate and unreliable segmentation outcomes due to the complex and varying morphology of teeth, although teeth segmentation in dental panoramic images is essential for dental disease diagnosis. We propose a novel teeth segmentation model incorporating an M-Net-like structure with Swin Transformers and TAB. The proposed TAB utilizes a unique attention mechanism that focuses specifically on the complex structures of teeth. The attention mechanism in TAB precisely highlights key elements of teeth features in panoramic images, resulting in more accurate segmentation outcomes. The proposed architecture effectively captures local and global contextual information, accurately defining each tooth and its surrounding structures. Furthermore, we employ a multiscale supervision strategy, which leverages the left and right legs of the U-Net structure, boosting the performance of the segmentation with enhanced feature representation. The squared Dice loss is utilized to tackle the class imbalance issue, ensuring accurate segmentation across all classes. The proposed method was validated on a panoramic teeth X-ray dataset, which was taken in a real-world dental diagnosis. The experimental results demonstrate the efficacy of our proposed architecture for tooth segmentation on multiple benchmark dental image datasets, outperforming existing state-of-the-art methods in objective metrics and visual examinations. This study has the potential to significantly enhance dental image analysis and contribute to advances in dental applications.
Re-initialization-free Level Set Method via Molecular Beam Epitaxy Equation Regularization for Image Segmentation
Oct 13, 2023Variational level set method has become a powerful tool in image segmentation due to its ability to handle complex topological changes and maintain continuity and smoothness in the process of evolution. However its evolution process can be unstable, which results in over flatted or over sharpened contours and segmentation failure. To improve the accuracy and stability of evolution, we propose a high-order level set variational segmentation method integrated with molecular beam epitaxy (MBE) equation regularization. This method uses the crystal growth in the MBE process to limit the evolution of the level set function, and thus can avoid the re-initialization in the evolution process and regulate the smoothness of the segmented curve. It also works for noisy images with intensity inhomogeneity, which is a challenge in image segmentation. To solve the variational model, we derive the gradient flow and design scalar auxiliary variable (SAV) scheme coupled with fast Fourier transform (FFT), which can significantly improve the computational efficiency compared with the traditional semi-implicit and semi-explicit scheme. Numerical experiments show that the proposed method can generate smooth segmentation curves, retain fine segmentation targets and obtain robust segmentation results of small objects. Compared to existing level set methods, this model is state-of-the-art in both accuracy and efficiency.
Dynamic Neural Fields for Learning Atlases of 4D Fetal MRI Time-series
Nov 06, 2023We present a method for fast biomedical image atlas construction using neural fields. Atlases are key to biomedical image analysis tasks, yet conventional and deep network estimation methods remain time-intensive. In this preliminary work, we frame subject-specific atlas building as learning a neural field of deformable spatiotemporal observations. We apply our method to learning subject-specific atlases and motion stabilization of dynamic BOLD MRI time-series of fetuses in utero. Our method yields high-quality atlases of fetal BOLD time-series with $\sim$5-7$\times$ faster convergence compared to existing work. While our method slightly underperforms well-tuned baselines in terms of anatomical overlap, it estimates templates significantly faster, thus enabling rapid processing and stabilization of large databases of 4D dynamic MRI acquisitions. Code is available at https://github.com/Kidrauh/neural-atlasing
ScribblePolyp: Scribble-Supervised Polyp Segmentation through Dual Consistency Alignment
Nov 09, 2023Automatic polyp segmentation models play a pivotal role in the clinical diagnosis of gastrointestinal diseases. In previous studies, most methods relied on fully supervised approaches, necessitating pixel-level annotations for model training. However, the creation of pixel-level annotations is both expensive and time-consuming, impeding the development of model generalization. In response to this challenge, we introduce ScribblePolyp, a novel scribble-supervised polyp segmentation framework. Unlike fully-supervised models, ScribblePolyp only requires the annotation of two lines (scribble labels) for each image, significantly reducing the labeling cost. Despite the coarse nature of scribble labels, which leave a substantial portion of pixels unlabeled, we propose a two-branch consistency alignment approach to provide supervision for these unlabeled pixels. The first branch employs transformation consistency alignment to narrow the gap between predictions under different transformations of the same input image. The second branch leverages affinity propagation to refine predictions into a soft version, extending additional supervision to unlabeled pixels. In summary, ScribblePolyp is an efficient model that does not rely on teacher models or moving average pseudo labels during training. Extensive experiments on the SUN-SEG dataset underscore the effectiveness of ScribblePolyp, achieving a Dice score of 0.8155, with the potential for a 1.8% improvement in the Dice score through a straightforward self-training strategy.
Multi-view Information Integration and Propagation for Occluded Person Re-identification
Nov 09, 2023Occluded person re-identification (re-ID) presents a challenging task due to occlusion perturbations. Although great efforts have been made to prevent the model from being disturbed by occlusion noise, most current solutions only capture information from a single image, disregarding the rich complementary information available in multiple images depicting the same pedestrian. In this paper, we propose a novel framework called Multi-view Information Integration and Propagation (MVI$^{2}$P). Specifically, realizing the potential of multi-view images in effectively characterizing the occluded target pedestrian, we integrate feature maps of which to create a comprehensive representation. During this process, to avoid introducing occlusion noise, we develop a CAMs-aware Localization module that selectively integrates information contributing to the identification. Additionally, considering the divergence in the discriminative nature of different images, we design a probability-aware Quantification module to emphatically integrate highly reliable information. Moreover, as multiple images with the same identity are not accessible in the testing stage, we devise an Information Propagation (IP) mechanism to distill knowledge from the comprehensive representation to that of a single occluded image. Extensive experiments and analyses have unequivocally demonstrated the effectiveness and superiority of the proposed MVI$^{2}$P. The code will be released at \url{https://github.com/nengdong96/MVIIP}.
Privacy Threats in Stable Diffusion Models
Nov 15, 2023This paper introduces a novel approach to membership inference attacks (MIA) targeting stable diffusion computer vision models, specifically focusing on the highly sophisticated Stable Diffusion V2 by StabilityAI. MIAs aim to extract sensitive information about a model's training data, posing significant privacy concerns. Despite its advancements in image synthesis, our research reveals privacy vulnerabilities in the stable diffusion models' outputs. Exploiting this information, we devise a black-box MIA that only needs to query the victim model repeatedly. Our methodology involves observing the output of a stable diffusion model at different generative epochs and training a classification model to distinguish when a series of intermediates originated from a training sample or not. We propose numerous ways to measure the membership features and discuss what works best. The attack's efficacy is assessed using the ROC AUC method, demonstrating a 60\% success rate in inferring membership information. This paper contributes to the growing body of research on privacy and security in machine learning, highlighting the need for robust defenses against MIAs. Our findings prompt a reevaluation of the privacy implications of stable diffusion models, urging practitioners and developers to implement enhanced security measures to safeguard against such attacks.
SparseSpikformer: A Co-Design Framework for Token and Weight Pruning in Spiking Transformer
Nov 15, 2023As the third-generation neural network, the Spiking Neural Network (SNN) has the advantages of low power consumption and high energy efficiency, making it suitable for implementation on edge devices. More recently, the most advanced SNN, Spikformer, combines the self-attention module from Transformer with SNN to achieve remarkable performance. However, it adopts larger channel dimensions in MLP layers, leading to an increased number of redundant model parameters. To effectively decrease the computational complexity and weight parameters of the model, we explore the Lottery Ticket Hypothesis (LTH) and discover a very sparse ($\ge$90%) subnetwork that achieves comparable performance to the original network. Furthermore, we also design a lightweight token selector module, which can remove unimportant background information from images based on the average spike firing rate of neurons, selecting only essential foreground image tokens to participate in attention calculation. Based on that, we present SparseSpikformer, a co-design framework aimed at achieving sparsity in Spikformer through token and weight pruning techniques. Experimental results demonstrate that our framework can significantly reduce 90% model parameters and cut down Giga Floating-Point Operations (GFLOPs) by 20% while maintaining the accuracy of the original model.