 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Counterfactual Image Generation for adversarially robust and interpretable Classifiers
Oct 01, 2023
Neural Image Classifiers are effective but inherently hard to interpret and susceptible to adversarial attacks. Solutions to both problems exist, among others, in the form of counterfactual examples generation to enhance explainability or adversarially augment training datasets for improved robustness. However, existing methods exclusively address only one of the issues. We propose a unified framework leveraging image-to-image translation Generative Adversarial Networks (GANs) to produce counterfactual samples that highlight salient regions for interpretability and act as adversarial samples to augment the dataset for more robustness. This is achieved by combining the classifier and discriminator into a single model that attributes real images to their respective classes and flags generated images as "fake". We assess the method's effectiveness by evaluating (i) the produced explainability masks on a semantic segmentation task for concrete cracks and (ii) the model's resilience against the Projected Gradient Descent (PGD) attack on a fruit defects detection problem. Our produced saliency maps are highly descriptive, achieving competitive IoU values compared to classical segmentation models despite being trained exclusively on classification labels. Furthermore, the model exhibits improved robustness to adversarial attacks, and we show how the discriminator's "fakeness" value serves as an uncertainty measure of the predictions.
Machine learning refinement of in situ images acquired by low electron dose LC-TEM
Oct 31, 2023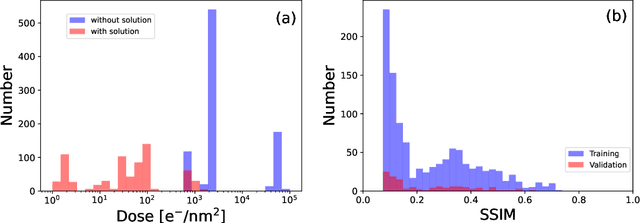
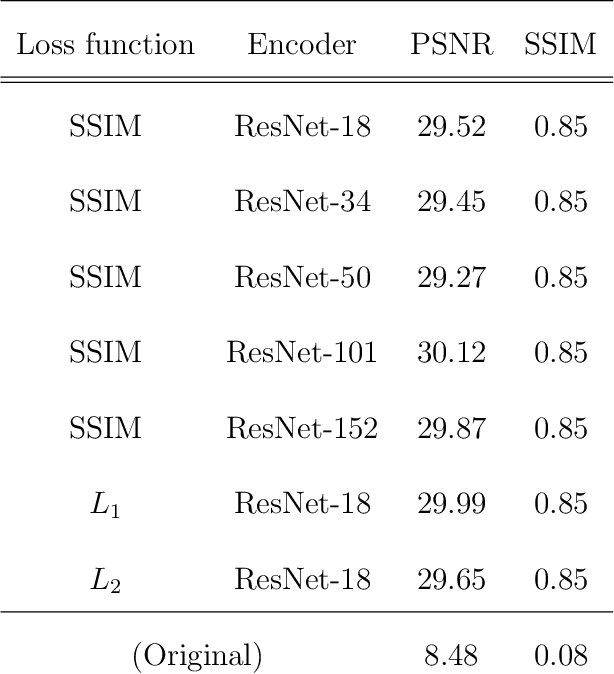
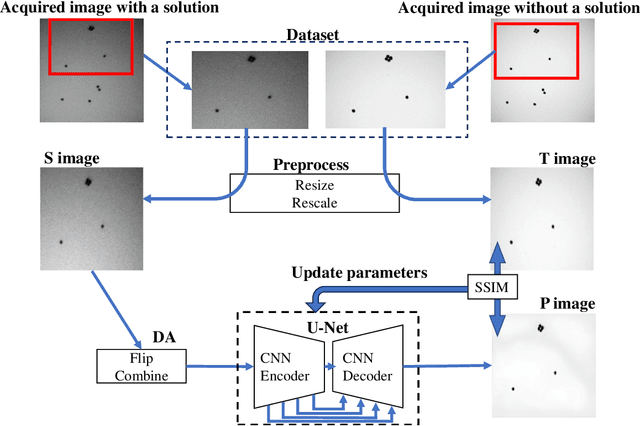
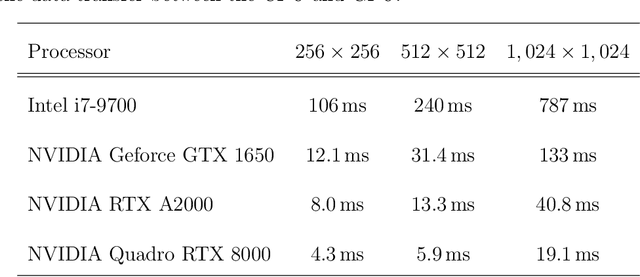
We study a machine learning (ML) technique for refining images acquired during in situ observation using liquid-cell transmission electron microscopy (LC-TEM). Our model is constructed using a U-Net architecture and a ResNet encoder. For training our ML model, we prepared an original image dataset that contained pairs of images of samples acquired with and without a solution present. The former images were used as noisy images and the latter images were used as corresponding ground truth images. The number of pairs of image sets was $1,204$ and the image sets included images acquired at several different magnifications and electron doses. The trained model converted a noisy image into a clear image. The time necessary for the conversion was on the order of 10ms, and we applied the model to in situ observations using the software Gatan DigitalMicrograph (DM). Even if a nanoparticle was not visible in a view window in the DM software because of the low electron dose, it was visible in a successive refined image generated by our ML model.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
On Manipulating Scene Text in the Wild with Diffusion Models
Nov 03, 2023
Diffusion models have gained attention for image editing yielding impressive results in text-to-image tasks. On the downside, one might notice that generated images of stable diffusion models suffer from deteriorated details. This pitfall impacts image editing tasks that require information preservation e.g., scene text editing. As a desired result, the model must show the capability to replace the text on the source image to the target text while preserving the details e.g., color, font size, and background. To leverage the potential of diffusion models, in this work, we introduce Diffusion-BasEd Scene Text manipulation Network so-called DBEST. Specifically, we design two adaptation strategies, namely one-shot style adaptation and text-recognition guidance. In experiments, we thoroughly assess and compare our proposed method against state-of-the-arts on various scene text datasets, then provide extensive ablation studies for each granularity to analyze our performance gain. Also, we demonstrate the effectiveness of our proposed method to synthesize scene text indicated by competitive Optical Character Recognition (OCR) accuracy. Our method achieves 94.15% and 98.12% on COCO-text and ICDAR2013 datasets for character-level evaluation.
GPT-4V(ision) as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
Zero-shot audio captioning with audio-language model guidance and audio context keywords
Nov 14, 2023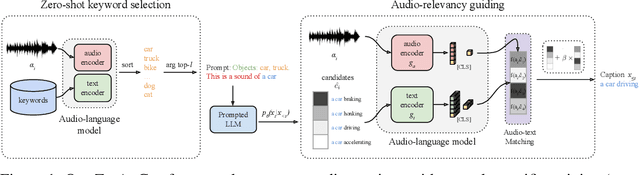
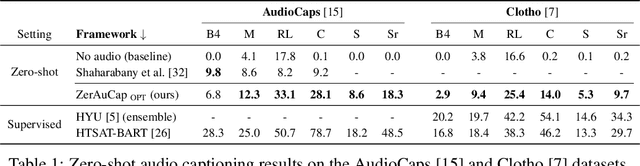

Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.
CogVLM: Visual Expert for Pretrained Language Models
Nov 06, 2023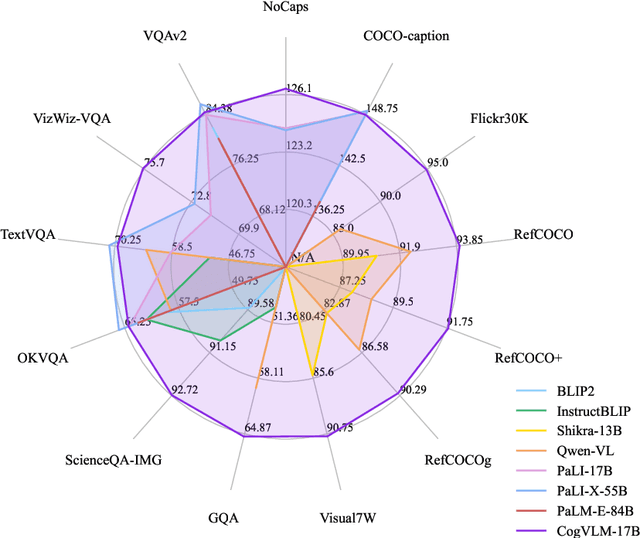
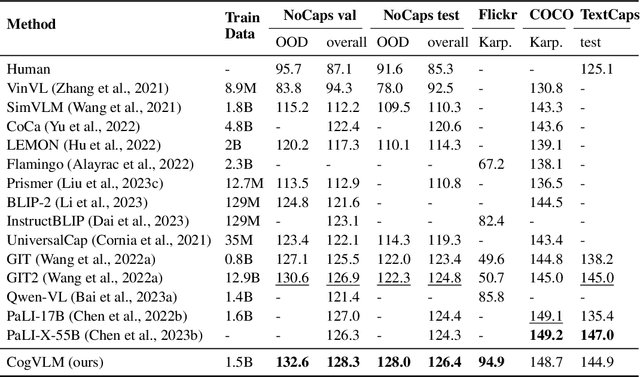

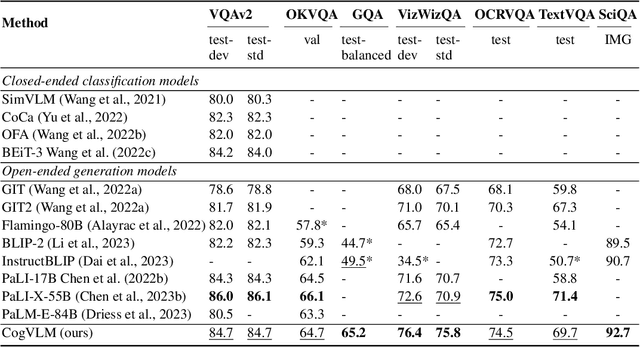
We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B. Codes and checkpoints are available at https://github.com/THUDM/CogVLM.
VcT: Visual change Transformer for Remote Sensing Image Change Detection
Oct 17, 2023Existing visual change detectors usually adopt CNNs or Transformers for feature representation learning and focus on learning effective representation for the changed regions between images. Although good performance can be obtained by enhancing the features of the change regions, however, these works are still limited mainly due to the ignorance of mining the unchanged background context information. It is known that one main challenge for change detection is how to obtain the consistent representations for two images involving different variations, such as spatial variation, sunlight intensity, etc. In this work, we demonstrate that carefully mining the common background information provides an important cue to learn the consistent representations for the two images which thus obviously facilitates the visual change detection problem. Based on this observation, we propose a novel Visual change Transformer (VcT) model for visual change detection problem. To be specific, a shared backbone network is first used to extract the feature maps for the given image pair. Then, each pixel of feature map is regarded as a graph node and the graph neural network is proposed to model the structured information for coarse change map prediction. Top-K reliable tokens can be mined from the map and refined by using the clustering algorithm. Then, these reliable tokens are enhanced by first utilizing self/cross-attention schemes and then interacting with original features via an anchor-primary attention learning module. Finally, the prediction head is proposed to get a more accurate change map. Extensive experiments on multiple benchmark datasets validated the effectiveness of our proposed VcT model.
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023
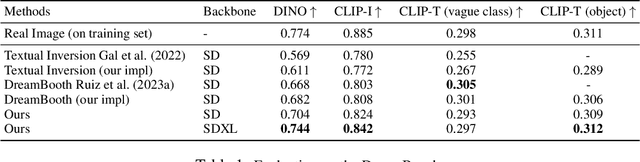

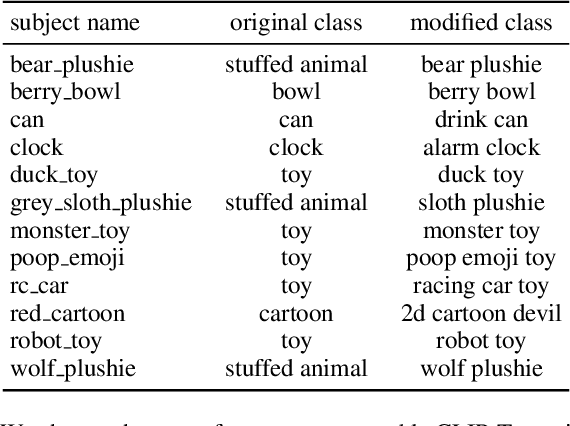
Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.