 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Control3D: Towards Controllable Text-to-3D Generation
Nov 09, 2023
Recent remarkable advances in large-scale text-to-image diffusion models have inspired a significant breakthrough in text-to-3D generation, pursuing 3D content creation solely from a given text prompt. However, existing text-to-3D techniques lack a crucial ability in the creative process: interactively control and shape the synthetic 3D contents according to users' desired specifications (e.g., sketch). To alleviate this issue, we present the first attempt for text-to-3D generation conditioning on the additional hand-drawn sketch, namely Control3D, which enhances controllability for users. In particular, a 2D conditioned diffusion model (ControlNet) is remoulded to guide the learning of 3D scene parameterized as NeRF, encouraging each view of 3D scene aligned with the given text prompt and hand-drawn sketch. Moreover, we exploit a pre-trained differentiable photo-to-sketch model to directly estimate the sketch of the rendered image over synthetic 3D scene. Such estimated sketch along with each sampled view is further enforced to be geometrically consistent with the given sketch, pursuing better controllable text-to-3D generation. Through extensive experiments, we demonstrate that our proposal can generate accurate and faithful 3D scenes that align closely with the input text prompts and sketches.
Efficient Retrieval of Images with Irregular Patterns using Morphological Image Analysis: Applications to Industrial and Healthcare datasets
Oct 10, 2023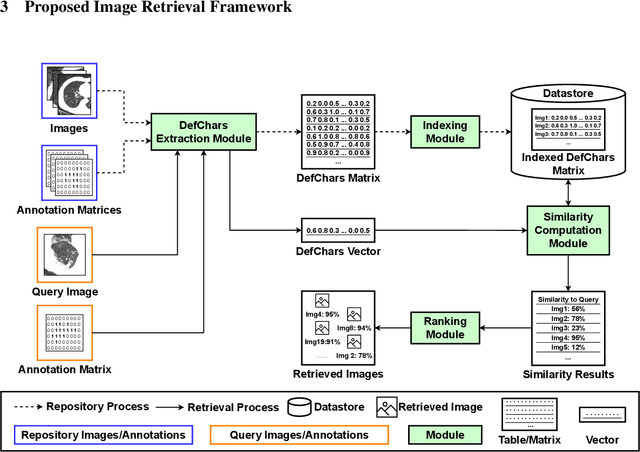

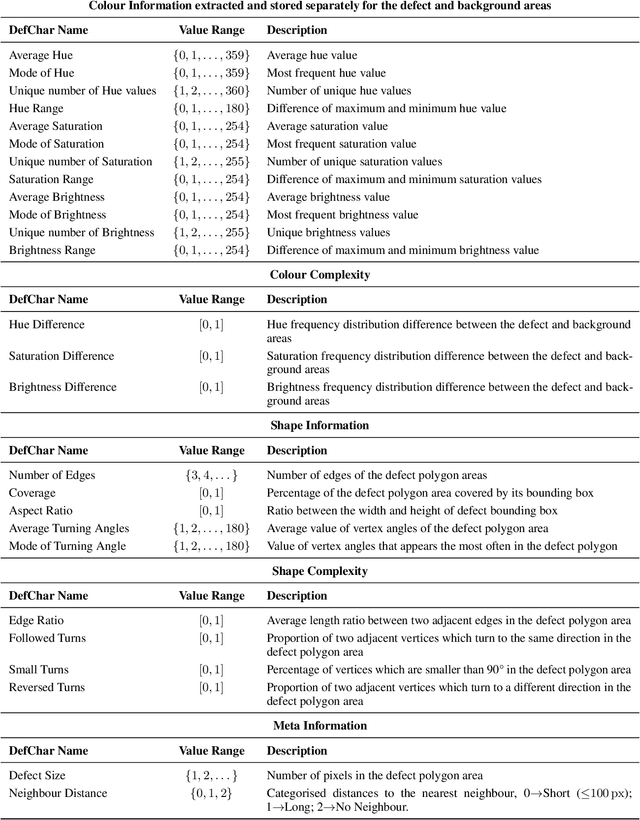
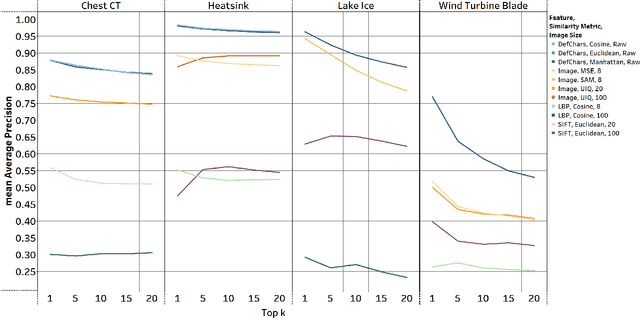
Image retrieval is the process of searching and retrieving images from a database based on their visual content and features. Recently, much attention has been directed towards the retrieval of irregular patterns within industrial or medical images by extracting features from the images, such as deep features, colour-based features, shape-based features and local features. This has applications across a spectrum of industries, including fault inspection, disease diagnosis, and maintenance prediction. This paper proposes an image retrieval framework to search for images containing similar irregular patterns by extracting a set of morphological features (DefChars) from images; the datasets employed in this paper contain wind turbine blade images with defects, chest computerised tomography scans with COVID-19 infection, heatsink images with defects, and lake ice images. The proposed framework was evaluated with different feature extraction methods (DefChars, resized raw image, local binary pattern, and scale-invariant feature transforms) and distance metrics to determine the most efficient parameters in terms of retrieval performance across datasets. The retrieval results show that the proposed framework using the DefChars and the Manhattan distance metric achieves a mean average precision of 80% and a low standard deviation of 0.09 across classes of irregular patterns, outperforming alternative feature-metric combinations across all datasets. Furthermore, the low standard deviation between each class highlights DefChars' capability for a reliable image retrieval task, even in the presence of class imbalances or small-sized datasets.
FIRST: A Million-Entry Dataset for Text-Driven Fashion Synthesis and Design
Nov 13, 2023Text-driven fashion synthesis and design is an extremely valuable part of artificial intelligence generative content(AIGC), which has the potential to propel a tremendous revolution in the traditional fashion industry. To advance the research on text-driven fashion synthesis and design, we introduce a new dataset comprising a million high-resolution fashion images with rich structured textual(FIRST) descriptions. In the FIRST, there is a wide range of attire categories and each image-paired textual description is organized at multiple hierarchical levels. Experiments on prevalent generative models trained over FISRT show the necessity of FIRST. We invite the community to further develop more intelligent fashion synthesis and design systems that make fashion design more creative and imaginative based on our dataset. The dataset will be released soon.
LT-ViT: A Vision Transformer for multi-label Chest X-ray classification
Nov 13, 2023Vision Transformers (ViTs) are widely adopted in medical imaging tasks, and some existing efforts have been directed towards vision-language training for Chest X-rays (CXRs). However, we envision that there still exists a potential for improvement in vision-only training for CXRs using ViTs, by aggregating information from multiple scales, which has been proven beneficial for non-transformer networks. Hence, we have developed LT-ViT, a transformer that utilizes combined attention between image tokens and randomly initialized auxiliary tokens that represent labels. Our experiments demonstrate that LT-ViT (1) surpasses the state-of-the-art performance using pure ViTs on two publicly available CXR datasets, (2) is generalizable to other pre-training methods and therefore is agnostic to model initialization, and (3) enables model interpretability without grad-cam and its variants.
Leveraging Optimization for Adaptive Attacks on Image Watermarks
Sep 29, 2023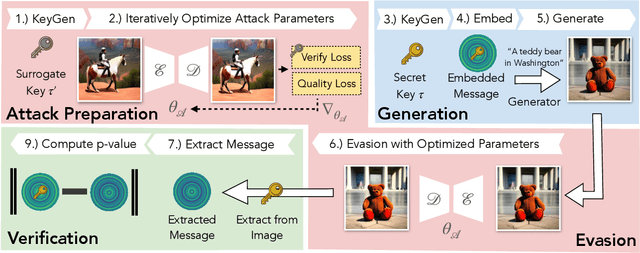
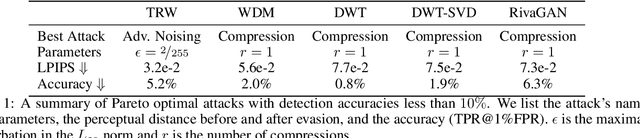
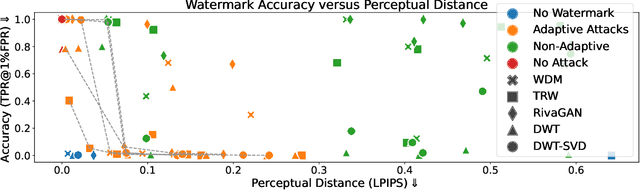
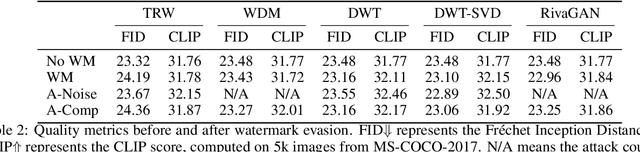
Untrustworthy users can misuse image generators to synthesize high-quality deepfakes and engage in online spam or disinformation campaigns. Watermarking deters misuse by marking generated content with a hidden message, enabling its detection using a secret watermarking key. A core security property of watermarking is robustness, which states that an attacker can only evade detection by substantially degrading image quality. Assessing robustness requires designing an adaptive attack for the specific watermarking algorithm. A challenge when evaluating watermarking algorithms and their (adaptive) attacks is to determine whether an adaptive attack is optimal, i.e., it is the best possible attack. We solve this problem by defining an objective function and then approach adaptive attacks as an optimization problem. The core idea of our adaptive attacks is to replicate secret watermarking keys locally by creating surrogate keys that are differentiable and can be used to optimize the attack's parameters. We demonstrate for Stable Diffusion models that such an attacker can break all five surveyed watermarking methods at negligible degradation in image quality. These findings emphasize the need for more rigorous robustness testing against adaptive, learnable attackers.
PRIS: Practical robust invertible network for image steganography
Sep 24, 2023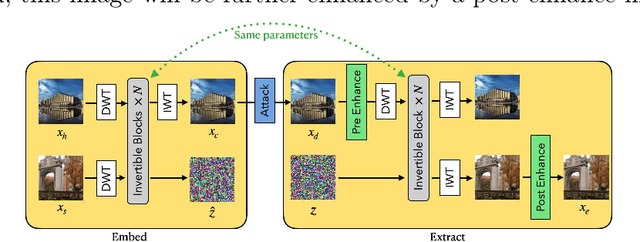
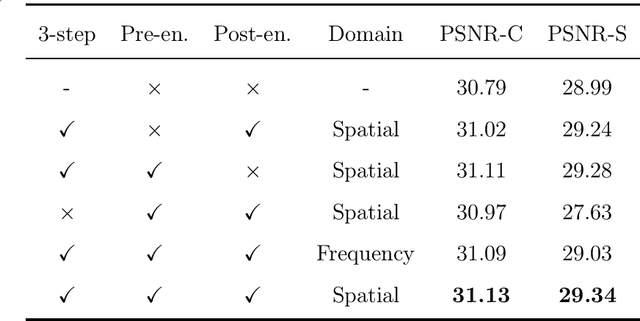
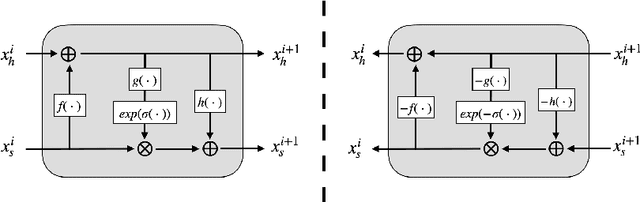
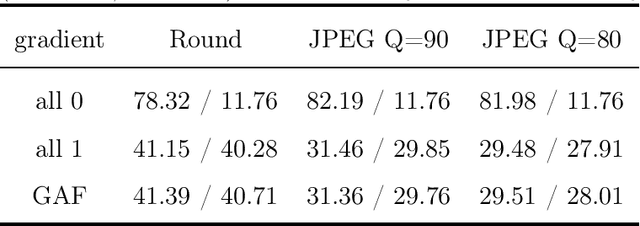
Image steganography is a technique of hiding secret information inside another image, so that the secret is not visible to human eyes and can be recovered when needed. Most of the existing image steganography methods have low hiding robustness when the container images affected by distortion. Such as Gaussian noise and lossy compression. This paper proposed PRIS to improve the robustness of image steganography, it based on invertible neural networks, and put two enhance modules before and after the extraction process with a 3-step training strategy. Moreover, rounding error is considered which is always ignored by existing methods, but actually it is unavoidable in practical. A gradient approximation function (GAF) is also proposed to overcome the undifferentiable issue of rounding distortion. Experimental results show that our PRIS outperforms the state-of-the-art robust image steganography method in both robustness and practicability. Codes are available at https://github.com/yanghangAI/PRIS, demonstration of our model in practical at http://yanghang.site/hide/.
Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
Nov 16, 2023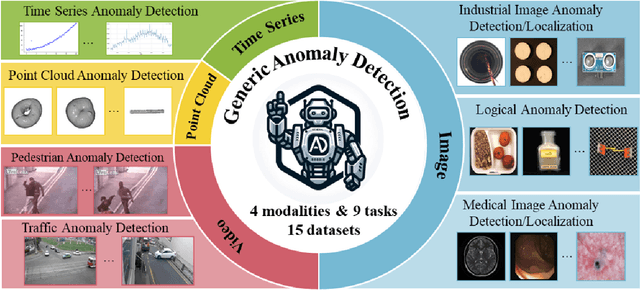
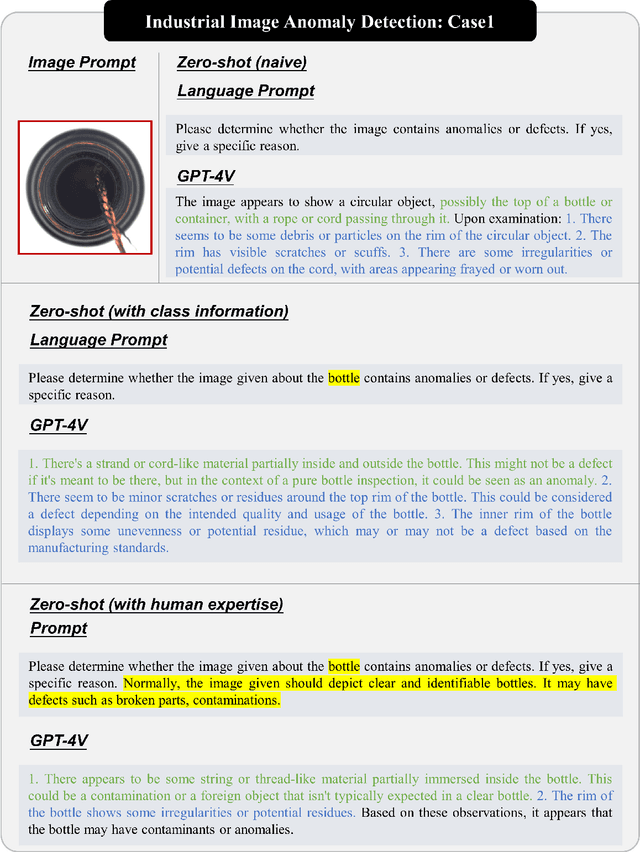

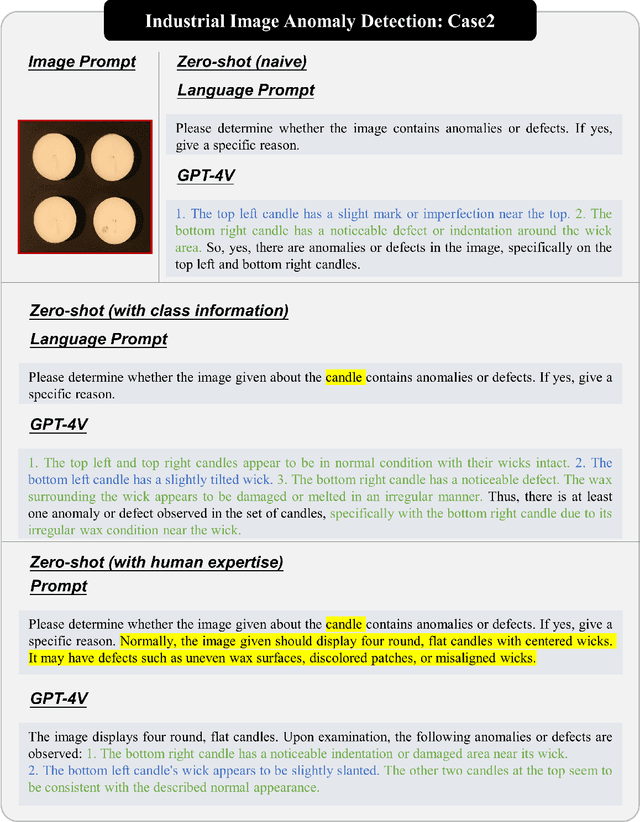
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Multi-entity Video Transformers for Fine-Grained Video Representation Learning
Nov 17, 2023The area of temporally fine-grained video representation learning aims to generate frame-by-frame representations for temporally dense tasks. In this work, we advance the state-of-the-art for this area by re-examining the design of transformer architectures for video representation learning. A salient aspect of our self-supervised method is the improved integration of spatial information in the temporal pipeline by representing multiple entities per frame. Prior works use late fusion architectures that reduce frames to a single dimensional vector before any cross-frame information is shared, while our method represents each frame as a group of entities or tokens. Our Multi-entity Video Transformer (MV-Former) architecture achieves state-of-the-art results on multiple fine-grained video benchmarks. MV-Former leverages image features from self-supervised ViTs, and employs several strategies to maximize the utility of the extracted features while also avoiding the need to fine-tune the complex ViT backbone. This includes a Learnable Spatial Token Pooling strategy, which is used to identify and extract features for multiple salient regions per frame. Our experiments show that MV-Former not only outperforms previous self-supervised methods, but also surpasses some prior works that use additional supervision or training data. When combined with additional pre-training data from Kinetics-400, MV-Former achieves a further performance boost. The code for MV-Former is available at https://github.com/facebookresearch/video_rep_learning.
Zero-shot audio captioning with audio-language model guidance and audio context keywords
Nov 14, 2023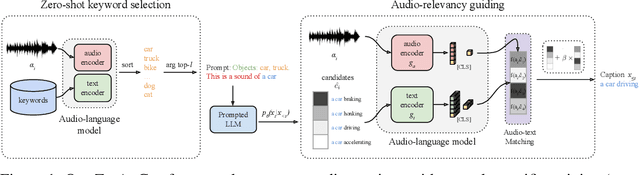
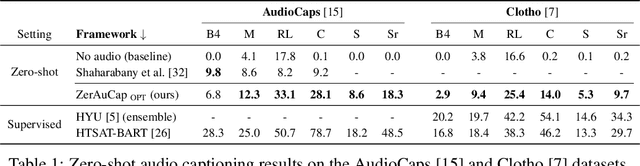

Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.