 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discrete approximations of Gaussian smoothing and Gaussian derivatives
Nov 19, 2023
This paper develops an in-depth treatment concerning the problem of approximating the Gaussian smoothing and Gaussian derivative computations in scale-space theory for application on discrete data. With close connections to previous axiomatic treatments of continuous and discrete scale-space theory, we consider three main ways discretizing these scale-space operations in terms of explicit discrete convolutions, based on either (i) sampling the Gaussian kernels and the Gaussian derivative kernels, (ii) locally integrating the Gaussian kernels and the Gaussian derivative kernels over each pixel support region and (iii) basing the scale-space analysis on the discrete analogue of the Gaussian kernel, and then computing derivative approximations by applying small-support central difference operators to the spatially smoothed image data. We study the properties of these three main discretization methods both theoretically and experimentally, and characterize their performance by quantitative measures, including the results they give rise to with respect to the task of scale selection, investigated for four different use cases, and with emphasis on the behaviour at fine scales. The results show that the sampled Gaussian kernels and derivatives as well as the integrated Gaussian kernels and derivatives perform very poorly at very fine scales. At very fine scales, the discrete analogue of the Gaussian kernel with its corresponding discrete derivative approximations performs substantially better. The sampled Gaussian kernel and the sampled Gaussian derivatives do, on the other hand, lead to numerically very good approximations of the corresponding continuous results, when the scale parameter is sufficiently large, in the experiments presented in the paper, when the scale parameter is greater than a value of about 1, in units of the grid spacing.
Physics-Enhanced Multi-fidelity Learning for Optical Surface Imprint
Nov 17, 2023Human fingerprints serve as one unique and powerful characteristic for each person, from which policemen can recognize the identity. Similar to humans, many natural bodies and intrinsic mechanical qualities can also be uniquely identified from surface characteristics. To measure the elasto-plastic properties of one material, one formally sharp indenter is pushed into the measured body under constant force and retracted, leaving a unique residual imprint of the minute size from several micrometers to nanometers. However, one great challenge is how to map the optical image of this residual imprint into the real wanted mechanical properties, i.e., the tensile force curve. In this paper, we propose a novel method to use multi-fidelity neural networks (MFNN) to solve this inverse problem. We first actively train the NN model via pure simulation data, and then bridge the sim-to-real gap via transfer learning. The most innovative part is that we use NN to dig out the unknown physics and also implant the known physics into the transfer learning framework, thus highly improving the model stability and decreasing the data requirement. This work serves as one great example of applying machine learning into the real experimental research, especially under the constraints of data limitation and fidelity variance.
* 8 pages, 4 figures, NeurIPS 2023 Workshop on Adaptive Experimental Design and Active Learning in the Real World
3D-TexSeg: Unsupervised Segmentation of 3D Texture using Mutual Transformer Learning
Nov 17, 2023Analysis of the 3D Texture is indispensable for various tasks, such as retrieval, segmentation, classification, and inspection of sculptures, knitted fabrics, and biological tissues. A 3D texture is a locally repeated surface variation independent of the surface's overall shape and can be determined using the local neighborhood and its characteristics. Existing techniques typically employ computer vision techniques that analyze a 3D mesh globally, derive features, and then utilize the obtained features for retrieval or classification. Several traditional and learning-based methods exist in the literature, however, only a few are on 3D texture, and nothing yet, to the best of our knowledge, on the unsupervised schemes. This paper presents an original framework for the unsupervised segmentation of the 3D texture on the mesh manifold. We approach this problem as binary surface segmentation, partitioning the mesh surface into textured and non-textured regions without prior annotation. We devise a mutual transformer-based system comprising a label generator and a cleaner. The two models take geometric image representations of the surface mesh facets and label them as texture or non-texture across an iterative mutual learning scheme. Extensive experiments on three publicly available datasets with diverse texture patterns demonstrate that the proposed framework outperforms standard and SOTA unsupervised techniques and competes reasonably with supervised methods.
Robustness Enhancement in Neural Networks with Alpha-Stable Training Noise
Nov 17, 2023With the increasing use of deep learning on data collected by non-perfect sensors and in non-perfect environments, the robustness of deep learning systems has become an important issue. A common approach for obtaining robustness to noise has been to train deep learning systems with data augmented with Gaussian noise. In this work, we challenge the common choice of Gaussian noise and explore the possibility of stronger robustness for non-Gaussian impulsive noise, specifically alpha-stable noise. Justified by the Generalized Central Limit Theorem and evidenced by observations in various application areas, alpha-stable noise is widely present in nature. By comparing the testing accuracy of models trained with Gaussian noise and alpha-stable noise on data corrupted by different noise, we find that training with alpha-stable noise is more effective than Gaussian noise, especially when the dataset is corrupted by impulsive noise, thus improving the robustness of the model. The generality of this conclusion is validated through experiments conducted on various deep learning models with image and time series datasets, and other benchmark corrupted datasets. Consequently, we propose a novel data augmentation method that replaces Gaussian noise, which is typically added to the training data, with alpha-stable noise.
Fast Detection of Phase Transitions with Multi-Task Learning-by-Confusion
Nov 15, 2023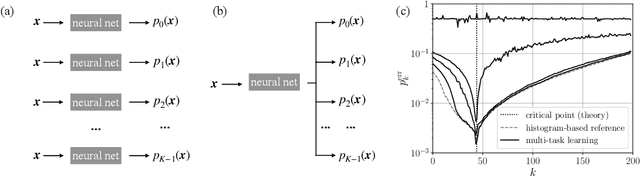

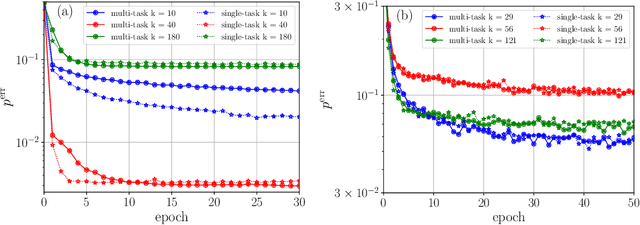
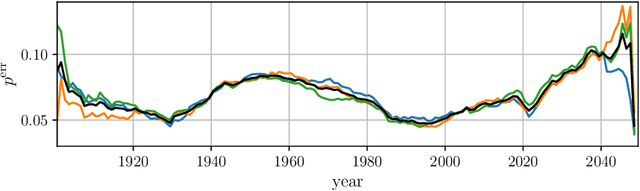
Machine learning has been successfully used to study phase transitions. One of the most popular approaches to identifying critical points from data without prior knowledge of the underlying phases is the learning-by-confusion scheme. As input, it requires system samples drawn from a grid of the parameter whose change is associated with potential phase transitions. Up to now, the scheme required training a distinct binary classifier for each possible splitting of the grid into two sides, resulting in a computational cost that scales linearly with the number of grid points. In this work, we propose and showcase an alternative implementation that only requires the training of a single multi-class classifier. Ideally, such multi-task learning eliminates the scaling with respect to the number of grid points. In applications to the Ising model and an image dataset generated with Stable Diffusion, we find significant speedups that closely correspond to the ideal case, with only minor deviations.
AdapterShadow: Adapting Segment Anything Model for Shadow Detection
Nov 15, 2023Segment anything model (SAM) has shown its spectacular performance in segmenting universal objects, especially when elaborate prompts are provided. However, the drawback of SAM is twofold. On the first hand, it fails to segment specific targets, e.g., shadow images or lesions in medical images. On the other hand, manually specifying prompts is extremely time-consuming. To overcome the problems, we propose AdapterShadow, which adapts SAM model for shadow detection. To adapt SAM for shadow images, trainable adapters are inserted into the frozen image encoder of SAM, since the training of the full SAM model is both time and memory consuming. Moreover, we introduce a novel grid sampling method to generate dense point prompts, which helps to automatically segment shadows without any manual interventions. Extensive experiments are conducted on four widely used benchmark datasets to demonstrate the superior performance of our proposed method. Codes will are publicly available at https://github.com/LeipingJie/AdapterShadow.
Correlation-aware active learning for surgery video segmentation
Nov 15, 2023Semantic segmentation is a complex task that relies heavily on large amounts of annotated image data. However, annotating such data can be time-consuming and resource-intensive, especially in the medical domain. Active Learning (AL) is a popular approach that can help to reduce this burden by iteratively selecting images for annotation to improve the model performance. In the case of video data, it is important to consider the model uncertainty and the temporal nature of the sequences when selecting images for annotation. This work proposes a novel AL strategy for surgery video segmentation, \COALSamp{}, COrrelation-aWare Active Learning. Our approach involves projecting images into a latent space that has been fine-tuned using contrastive learning and then selecting a fixed number of representative images from local clusters of video frames. We demonstrate the effectiveness of this approach on two video datasets of surgical instruments and three real-world video datasets. The datasets and code will be made publicly available upon receiving necessary approvals.
4K-Resolution Photo Exposure Correction at 125 FPS with ~8K Parameters
Nov 15, 2023The illumination of improperly exposed photographs has been widely corrected using deep convolutional neural networks or Transformers. Despite with promising performance, these methods usually suffer from large parameter amounts and heavy computational FLOPs on high-resolution photographs. In this paper, we propose extremely light-weight (with only ~8K parameters) Multi-Scale Linear Transformation (MSLT) networks under the multi-layer perception architecture, which can process 4K-resolution sRGB images at 125 Frame-Per-Second (FPS) by a Titan RTX GPU. Specifically, the proposed MSLT networks first decompose an input image into high and low frequency layers by Laplacian pyramid techniques, and then sequentially correct different layers by pixel-adaptive linear transformation, which is implemented by efficient bilateral grid learning or 1x1 convolutions. Experiments on two benchmark datasets demonstrate the efficiency of our MSLTs against the state-of-the-arts on photo exposure correction. Extensive ablation studies validate the effectiveness of our contributions. The code is available at https://github.com/Zhou-Yijie/MSLTNet.
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023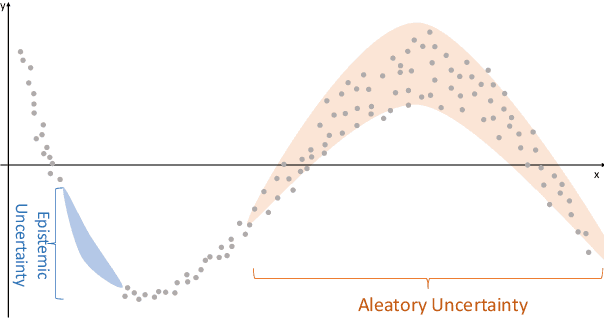
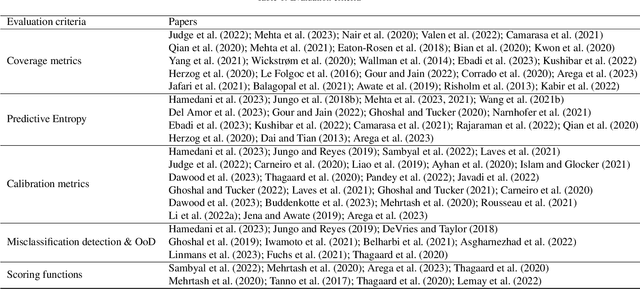
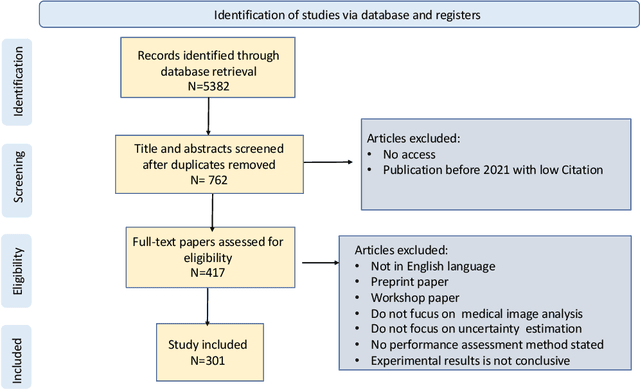
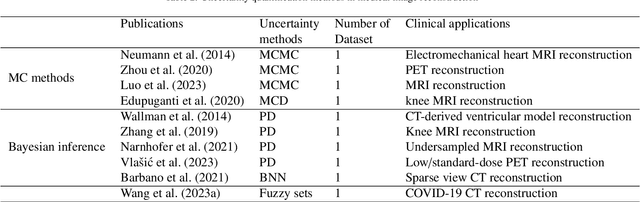
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.
DreamCom: Finetuning Text-guided Inpainting Model for Image Composition
Sep 27, 2023The goal of image composition is merging a foreground object into a background image to obtain a realistic composite image. Recently, generative composition methods are built on large pretrained diffusion models, due to their unprecedented image generation ability. They train a model on abundant pairs of foregrounds and backgrounds, so that it can be directly applied to a new pair of foreground and background at test time. However, the generated results often lose the foreground details and exhibit noticeable artifacts. In this work, we propose an embarrassingly simple approach named DreamCom inspired by DreamBooth. Specifically, given a few reference images for a subject, we finetune text-guided inpainting diffusion model to associate this subject with a special token and inpaint this subject in the specified bounding box. We also construct a new dataset named MureCom well-tailored for this task.