 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023
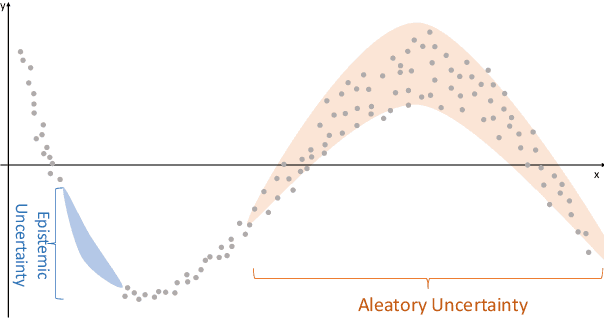
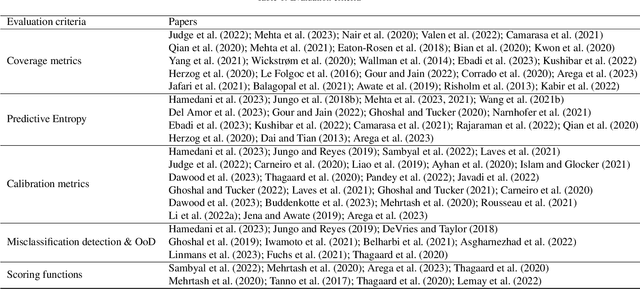
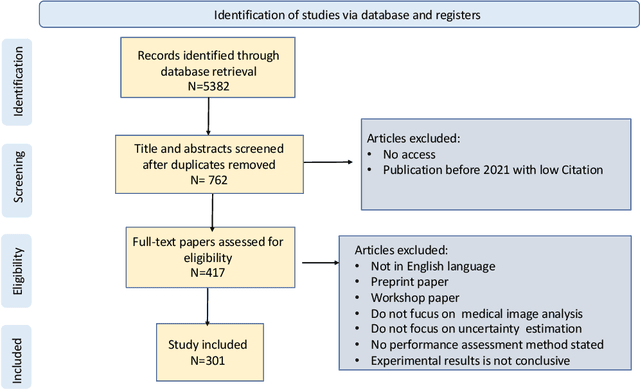
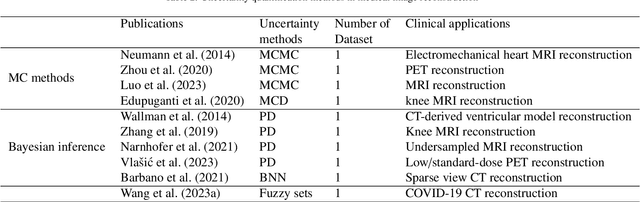
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.
Accuracy of a Vision-Language Model on Challenging Medical Cases
Nov 09, 2023Background: General-purpose large language models that utilize both text and images have not been evaluated on a diverse array of challenging medical cases. Methods: Using 934 cases from the NEJM Image Challenge published between 2005 and 2023, we evaluated the accuracy of the recently released Generative Pre-trained Transformer 4 with Vision model (GPT-4V) compared to human respondents overall and stratified by question difficulty, image type, and skin tone. We further conducted a physician evaluation of GPT-4V on 69 NEJM clinicopathological conferences (CPCs). Analyses were conducted for models utilizing text alone, images alone, and both text and images. Results: GPT-4V achieved an overall accuracy of 61% (95% CI, 58 to 64%) compared to 49% (95% CI, 49 to 50%) for humans. GPT-4V outperformed humans at all levels of difficulty and disagreement, skin tones, and image types; the exception was radiographic images, where performance was equivalent between GPT-4V and human respondents. Longer, more informative captions were associated with improved performance for GPT-4V but similar performance for human respondents. GPT-4V included the correct diagnosis in its differential for 80% (95% CI, 68 to 88%) of CPCs when using text alone, compared to 58% (95% CI, 45 to 70%) of CPCs when using both images and text. Conclusions: GPT-4V outperformed human respondents on challenging medical cases and was able to synthesize information from both images and text, but performance deteriorated when images were added to highly informative text. Overall, our results suggest that multimodal AI models may be useful in medical diagnostic reasoning but that their accuracy may depend heavily on context.
Leveraging Optimization for Adaptive Attacks on Image Watermarks
Sep 29, 2023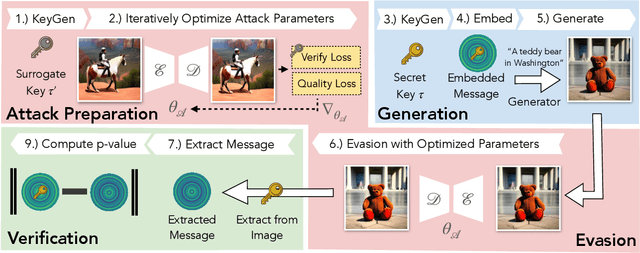
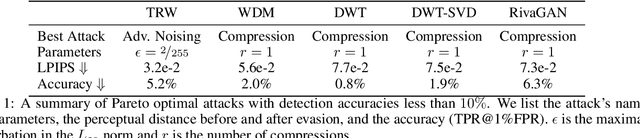
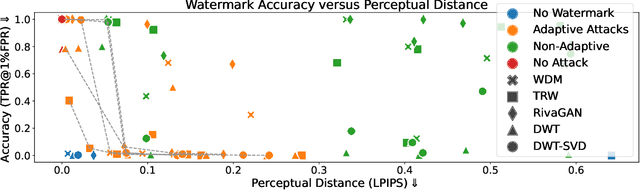
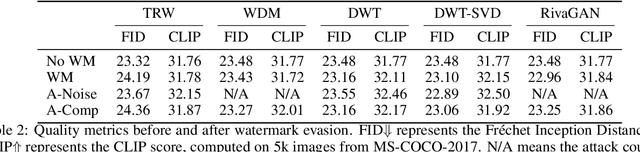
Untrustworthy users can misuse image generators to synthesize high-quality deepfakes and engage in online spam or disinformation campaigns. Watermarking deters misuse by marking generated content with a hidden message, enabling its detection using a secret watermarking key. A core security property of watermarking is robustness, which states that an attacker can only evade detection by substantially degrading image quality. Assessing robustness requires designing an adaptive attack for the specific watermarking algorithm. A challenge when evaluating watermarking algorithms and their (adaptive) attacks is to determine whether an adaptive attack is optimal, i.e., it is the best possible attack. We solve this problem by defining an objective function and then approach adaptive attacks as an optimization problem. The core idea of our adaptive attacks is to replicate secret watermarking keys locally by creating surrogate keys that are differentiable and can be used to optimize the attack's parameters. We demonstrate for Stable Diffusion models that such an attacker can break all five surveyed watermarking methods at negligible degradation in image quality. These findings emphasize the need for more rigorous robustness testing against adaptive, learnable attackers.
Enhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining
Nov 07, 2023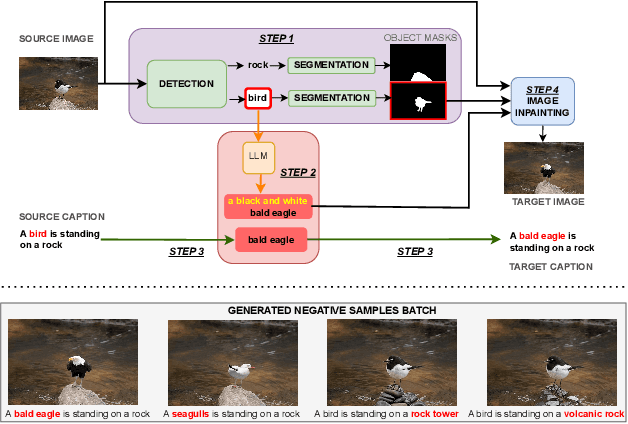
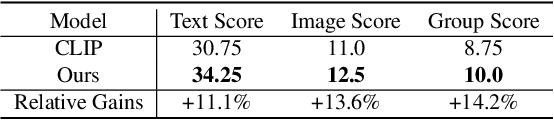
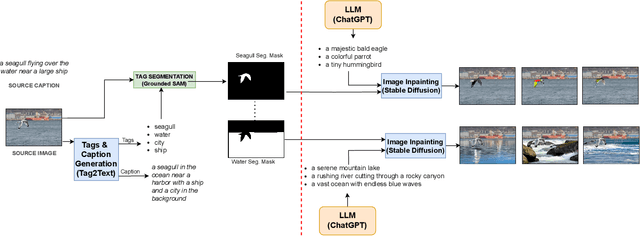
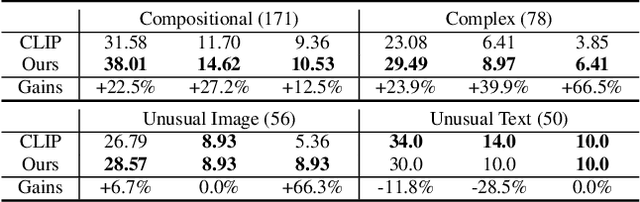
Contemporary large-scale visual language models (VLMs) exhibit strong representation capacities, making them ubiquitous for enhancing image and text understanding tasks. They are often trained in a contrastive manner on a large and diverse corpus of images and corresponding text captions scraped from the internet. Despite this, VLMs often struggle with compositional reasoning tasks which require a fine-grained understanding of the complex interactions of objects and their attributes. This failure can be attributed to two main factors: 1) Contrastive approaches have traditionally focused on mining negative examples from existing datasets. However, the mined negative examples might not be difficult for the model to discriminate from the positive. An alternative to mining would be negative sample generation 2) But existing generative approaches primarily focus on generating hard negative texts associated with a given image. Mining in the other direction, i.e., generating negative image samples associated with a given text has been ignored. To overcome both these limitations, we propose a framework that not only mines in both directions but also generates challenging negative samples in both modalities, i.e., images and texts. Leveraging these generative hard negative samples, we significantly enhance VLMs' performance in tasks involving multimodal compositional reasoning. Our code and dataset are released at https://ugorsahin.github.io/enhancing-multimodal-compositional-reasoning-of-vlm.html.
Auto-ICell: An Accessible and Cost-Effective Integrative Droplet Microfluidic System for Real-Time Single-Cell Morphological and Apoptotic Analysis
Nov 06, 2023The Auto-ICell system, a novel, and cost-effective integrated droplet microfluidic system, is introduced for real-time analysis of single-cell morphology and apoptosis. This system integrates a 3D-printed microfluidic chip with image analysis algorithms, enabling the generation of uniform droplet reactors and immediate image analysis. The system employs a color-based image analysis algorithm in the bright field for droplet content analysis. Meanwhile, in the fluorescence field, cell apoptosis is quantitatively measured through a combination of deep-learning-enabled multiple fluorescent channel analysis and a live/dead cell stain kit. Breast cancer cells are encapsulated within uniform droplets, with diameters ranging from 70 {\mu}m to 240 {\mu}m, generated at a high throughput of 1,500 droplets per minute. Real-time image analysis results are displayed within 2 seconds on a custom graphical user interface (GUI). The system provides an automatic calculation of the distribution and ratio of encapsulated dyes in the bright field, and in the fluorescent field, cell blebbing and cell circularity are observed and quantified respectively. The Auto-ICell system is non-invasive and provides online detection, offering a robust, time-efficient, user-friendly, and cost-effective solution for single-cell analysis. It significantly enhances the detection throughput of droplet single-cell analysis by reducing setup costs and improving operational performance. This study highlights the potential of the Auto-ICell system in advancing biological research and personalized disease treatment, with promising applications in cell culture, biochemical microreactors, drug carriers, cell-based assays, synthetic biology, and point-of-care diagnostics.
MoCo-Transfer: Investigating out-of-distribution contrastive learning for limited-data domains
Nov 15, 2023Medical imaging data is often siloed within hospitals, limiting the amount of data available for specialized model development. With limited in-domain data, one might hope to leverage larger datasets from related domains. In this paper, we analyze the benefit of transferring self-supervised contrastive representations from moment contrast (MoCo) pretraining on out-of-distribution data to settings with limited data. We consider two X-ray datasets which image different parts of the body, and compare transferring from each other to transferring from ImageNet. We find that depending on quantity of labeled and unlabeled data, contrastive pretraining on larger out-of-distribution datasets can perform nearly as well or better than MoCo pretraining in-domain, and pretraining on related domains leads to higher performance than if one were to use the ImageNet pretrained weights. Finally, we provide a preliminary way of quantifying similarity between datasets.
Be Careful When Evaluating Explanations Regarding Ground Truth
Nov 08, 2023Evaluating explanations of image classifiers regarding ground truth, e.g. segmentation masks defined by human perception, primarily evaluates the quality of the models under consideration rather than the explanation methods themselves. Driven by this observation, we propose a framework for $\textit{jointly}$ evaluating the robustness of safety-critical systems that $\textit{combine}$ a deep neural network with an explanation method. These are increasingly used in real-world applications like medical image analysis or robotics. We introduce a fine-tuning procedure to (mis)align model$\unicode{x2013}$explanation pipelines with ground truth and use it to quantify the potential discrepancy between worst and best-case scenarios of human alignment. Experiments across various model architectures and post-hoc local interpretation methods provide insights into the robustness of vision transformers and the overall vulnerability of such AI systems to potential adversarial attacks.
See SIFT in a Rain
Nov 01, 2023Rain streaks bring complicated pixel intensity changes and additional gradients, greatly obstructing the extraction of image features from background. This causes serious performance degradation in feature-based applications. Thus, it is critical to remove rain streaks from a single rainy image to recover image features. Recently, many excellent image deraining methods have made remarkable progress. However, these human visual system-driven approaches mainly focus on improving image quality with pixel recovery as loss function, and neglect how to enhance image feature recovery ability. To address this issue, we propose a task-driven image deraining algorithm to strengthen image feature supply for subsequent feature-based applications. Due to the extensive use and strong practicability of Scale-Invariant Feature Transform (SIFT), we first propose two separate networks using distinct losses and modules to achieve two goals, respectively. One is difference of Gaussian (DoG) pyramid recovery network (DPRNet) for SIFT detection, and the other gradients of Gaussian images recovery network (GGIRNet) for SIFT description. Second, in the DPRNet we propose an alternative interest point loss that directly penalizes scale response extrema to recover the DoG pyramid. Third, we advance a gradient attention module in the GGIRNet to recover those gradients of Gaussian images. Finally, with the recovered DoG pyramid and gradients, we can regain SIFT key points. This divide-and-conquer scheme to set different objectives for SIFT detection and description leads to good robustness. Compared with state-of-the-art methods, experimental results demonstrate that our proposed algorithm achieves better performance in both the number of recovered SIFT key points and their accuracy.
* A direct DoG feature pyramid recovery from rainy pixels solution for SIFT detection, accepted by T-CSVT, 2023
Complex Organ Mask Guided Radiology Report Generation
Nov 10, 2023The goal of automatic report generation is to generate a clinically accurate and coherent phrase from a single given X-ray image, which could alleviate the workload of traditional radiology reporting. However, in a real-world scenario, radiologists frequently face the challenge of producing extensive reports derived from numerous medical images, thereby medical report generation from multi-image perspective is needed. In this paper, we propose the Complex Organ Mask Guided (termed as COMG) report generation model, which incorporates masks from multiple organs (e.g., bones, lungs, heart, and mediastinum), to provide more detailed information and guide the model's attention to these crucial body regions. Specifically, we leverage prior knowledge of the disease corresponding to each organ in the fusion process to enhance the disease identification phase during the report generation process. Additionally, cosine similarity loss is introduced as target function to ensure the convergence of cross-modal consistency and facilitate model optimization.Experimental results on two public datasets show that COMG achieves a 11.4% and 9.7% improvement in terms of BLEU@4 scores over the SOTA model KiUT on IU-Xray and MIMIC, respectively. The code is publicly available at https://github.com/GaryGuTC/COMG_model.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023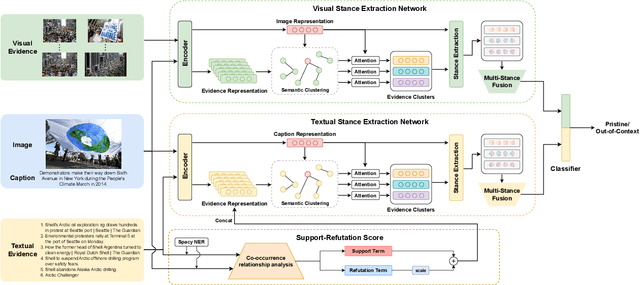
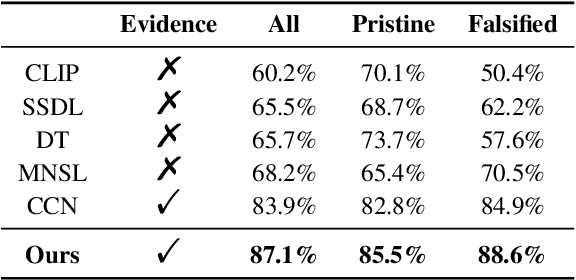
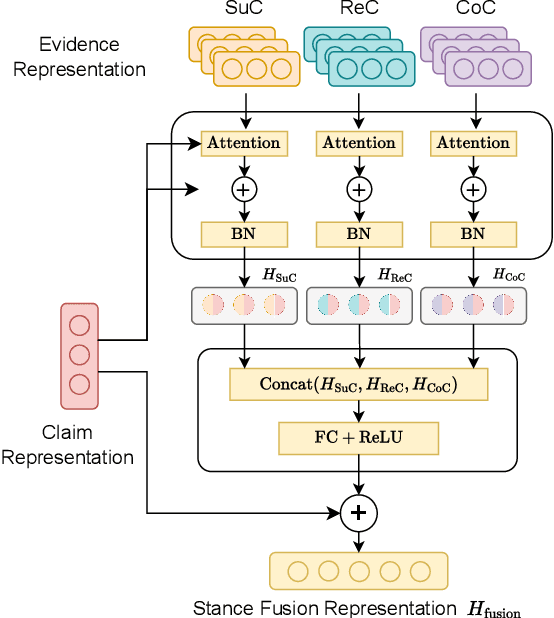
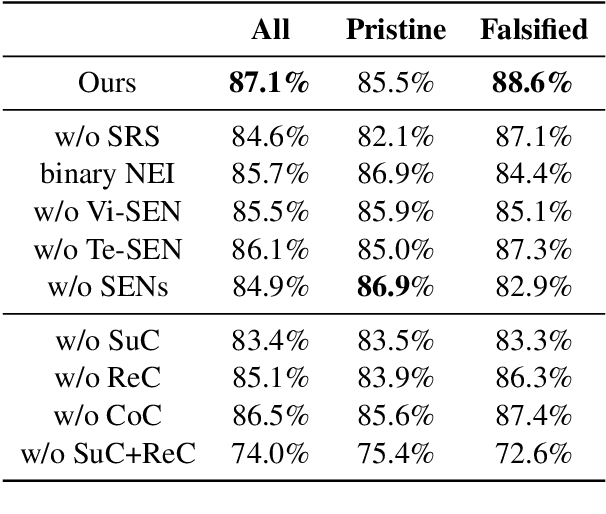
Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.