 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Oct 14, 2023
Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.
A Survey on Image-text Multimodal Models
Sep 23, 2023Amidst the evolving landscape of artificial intelligence, the convergence of visual and textual information has surfaced as a crucial frontier, leading to the advent of image-text multimodal models. This paper provides a comprehensive review of the evolution and current state of image-text multimodal models, exploring their application value, challenges, and potential research trajectories. Initially, we revisit the basic concepts and developmental milestones of these models, introducing a novel classification that segments their evolution into three distinct phases, based on their time of introduction and subsequent impact on the discipline. Furthermore, based on the tasks' significance and prevalence in the academic landscape, we propose a categorization of the tasks associated with image-text multimodal models into five major types, elucidating the recent progress and key technologies within each category. Despite the remarkable accomplishments of these models, numerous challenges and issues persist. This paper delves into the inherent challenges and limitations of image-text multimodal models, fostering the exploration of prospective research directions. Our objective is to offer an exhaustive overview of the present research landscape of image-text multimodal models and to serve as a valuable reference for future scholarly endeavors. We extend an invitation to the broader community to collaborate in enhancing the image-text multimodal model community, accessible at: \href{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}.
Leveraging Function Space Aggregation for Federated Learning at Scale
Nov 17, 2023The federated learning paradigm has motivated the development of methods for aggregating multiple client updates into a global server model, without sharing client data. Many federated learning algorithms, including the canonical Federated Averaging (FedAvg), take a direct (possibly weighted) average of the client parameter updates, motivated by results in distributed optimization. In this work, we adopt a function space perspective and propose a new algorithm, FedFish, that aggregates local approximations to the functions learned by clients, using an estimate based on their Fisher information. We evaluate FedFish on realistic, large-scale cross-device benchmarks. While the performance of FedAvg can suffer as client models drift further apart, we demonstrate that FedFish is more robust to longer local training. Our evaluation across several settings in image and language benchmarks shows that FedFish outperforms FedAvg as local training epochs increase. Further, FedFish results in global networks that are more amenable to efficient personalization via local fine-tuning on the same or shifted data distributions. For instance, federated pretraining on the C4 dataset, followed by few-shot personalization on Stack Overflow, results in a 7% improvement in next-token prediction by FedFish over FedAvg.
De-Diffusion Makes Text a Strong Cross-Modal Interface
Nov 01, 2023We demonstrate text as a strong cross-modal interface. Rather than relying on deep embeddings to connect image and language as the interface representation, our approach represents an image as text, from which we enjoy the interpretability and flexibility inherent to natural language. We employ an autoencoder that uses a pre-trained text-to-image diffusion model for decoding. The encoder is trained to transform an input image into text, which is then fed into the fixed text-to-image diffusion decoder to reconstruct the original input -- a process we term De-Diffusion. Experiments validate both the precision and comprehensiveness of De-Diffusion text representing images, such that it can be readily ingested by off-the-shelf text-to-image tools and LLMs for diverse multi-modal tasks. For example, a single De-Diffusion model can generalize to provide transferable prompts for different text-to-image tools, and also achieves a new state of the art on open-ended vision-language tasks by simply prompting large language models with few-shot examples.
Leveraging Classic Deconvolution and Feature Extraction in Zero-Shot Image Restoration
Oct 03, 2023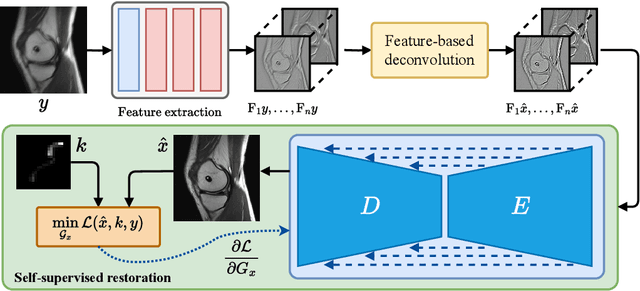
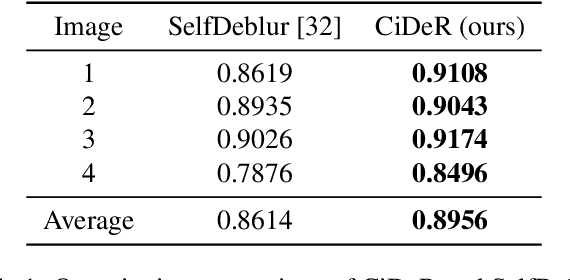
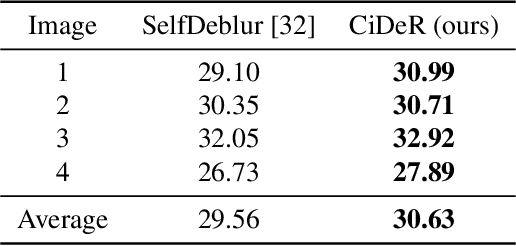
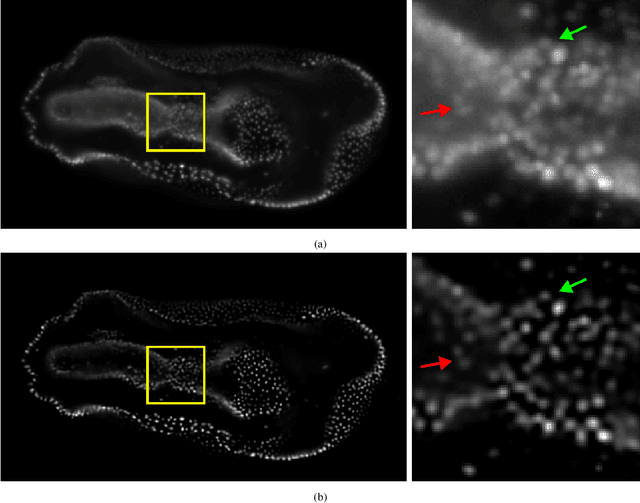
Non-blind deconvolution aims to restore a sharp image from its blurred counterpart given an obtained kernel. Existing deep neural architectures are often built based on large datasets of sharp ground truth images and trained with supervision. Sharp, high quality ground truth images, however, are not always available, especially for biomedical applications. This severely hampers the applicability of current approaches in practice. In this paper, we propose a novel non-blind deconvolution method that leverages the power of deep learning and classic iterative deconvolution algorithms. Our approach combines a pre-trained network to extract deep features from the input image with iterative Richardson-Lucy deconvolution steps. Subsequently, a zero-shot optimisation process is employed to integrate the deconvolved features, resulting in a high-quality reconstructed image. By performing the preliminary reconstruction with the classic iterative deconvolution method, we can effectively utilise a smaller network to produce the final image, thus accelerating the reconstruction whilst reducing the demand for valuable computational resources. Our method demonstrates significant improvements in various real-world applications non-blind deconvolution tasks.
3DStyle-Diffusion: Pursuing Fine-grained Text-driven 3D Stylization with 2D Diffusion Models
Nov 09, 20233D content creation via text-driven stylization has played a fundamental challenge to multimedia and graphics community. Recent advances of cross-modal foundation models (e.g., CLIP) have made this problem feasible. Those approaches commonly leverage CLIP to align the holistic semantics of stylized mesh with the given text prompt. Nevertheless, it is not trivial to enable more controllable stylization of fine-grained details in 3D meshes solely based on such semantic-level cross-modal supervision. In this work, we propose a new 3DStyle-Diffusion model that triggers fine-grained stylization of 3D meshes with additional controllable appearance and geometric guidance from 2D Diffusion models. Technically, 3DStyle-Diffusion first parameterizes the texture of 3D mesh into reflectance properties and scene lighting using implicit MLP networks. Meanwhile, an accurate depth map of each sampled view is achieved conditioned on 3D mesh. Then, 3DStyle-Diffusion leverages a pre-trained controllable 2D Diffusion model to guide the learning of rendered images, encouraging the synthesized image of each view semantically aligned with text prompt and geometrically consistent with depth map. This way elegantly integrates both image rendering via implicit MLP networks and diffusion process of image synthesis in an end-to-end fashion, enabling a high-quality fine-grained stylization of 3D meshes. We also build a new dataset derived from Objaverse and the evaluation protocol for this task. Through both qualitative and quantitative experiments, we validate the capability of our 3DStyle-Diffusion. Source code and data are available at \url{https://github.com/yanghb22-fdu/3DStyle-Diffusion-Official}.
Inertial Guided Uncertainty Estimation of Feature Correspondence in Visual-Inertial Odometry/SLAM
Nov 07, 2023Visual odometry and Simultaneous Localization And Mapping (SLAM) has been studied as one of the most important tasks in the areas of computer vision and robotics, to contribute to autonomous navigation and augmented reality systems. In case of feature-based odometry/SLAM, a moving visual sensor observes a set of 3D points from different viewpoints, correspondences between the projected 2D points in each image are usually established by feature tracking and matching. However, since the corresponding point could be erroneous and noisy, reliable uncertainty estimation can improve the accuracy of odometry/SLAM methods. In addition, inertial measurement unit is utilized to aid the visual sensor in terms of Visual-Inertial fusion. In this paper, we propose a method to estimate the uncertainty of feature correspondence using an inertial guidance robust to image degradation caused by motion blur, illumination change and occlusion. Modeling a guidance distribution to sample possible correspondence, we fit the distribution to an energy function based on image error, yielding more robust uncertainty than conventional methods. We also demonstrate the feasibility of our approach by incorporating it into one of recent visual-inertial odometry/SLAM algorithms for public datasets.
Energy-based Calibrated VAE with Test Time Free Lunch
Nov 07, 2023In this paper, we propose a novel Energy-Calibrated Generative Model that utilizes a Conditional EBM for enhancing Variational Autoencoders (VAEs). VAEs are sampling efficient but often suffer from blurry generation results due to the lack of training in the generative direction. On the other hand, Energy-Based Models (EBMs) can generate high-quality samples but require expensive Markov Chain Monte Carlo (MCMC) sampling. To address these issues, we introduce a Conditional EBM for calibrating the generative direction during training, without requiring it for test time sampling. Our approach enables the generative model to be trained upon data and calibrated samples with adaptive weight, thereby enhancing efficiency and effectiveness without necessitating MCMC sampling in the inference phase. We also show that the proposed approach can be extended to calibrate normalizing flows and variational posterior. Moreover, we propose to apply the proposed method to zero-shot image restoration via neural transport prior and range-null theory. We demonstrate the effectiveness of the proposed method through extensive experiments in various applications, including image generation and zero-shot image restoration. Our method shows state-of-the-art performance over single-step non-adversarial generation.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023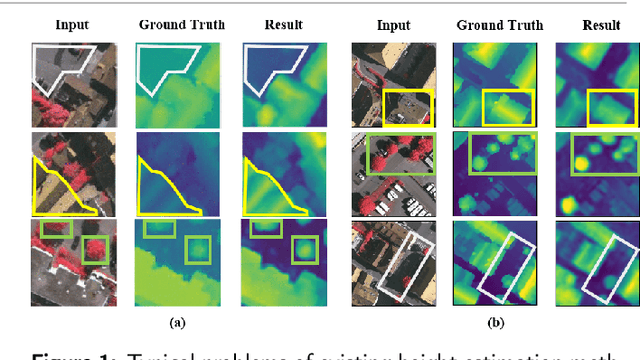
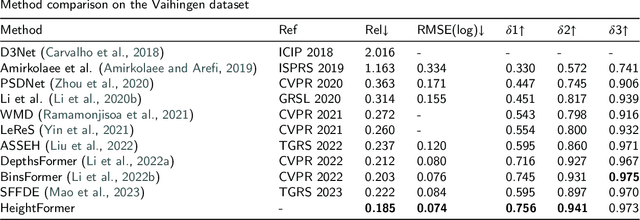
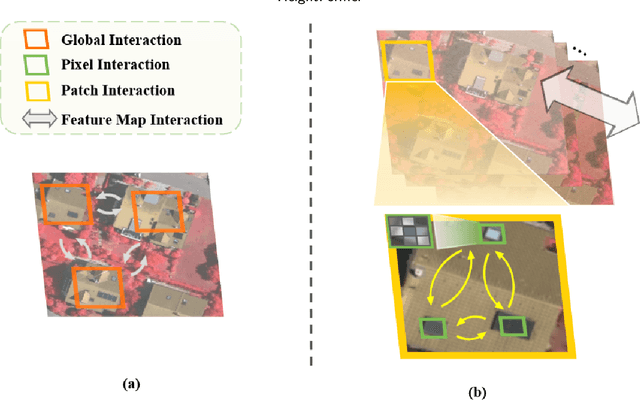

Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.