 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Back to Basics: Fast Denoising Iterative Algorithm
Nov 11, 2023
We introduce Back to Basics (BTB), a fast iterative algorithm for noise reduction. Our method is computationally efficient, does not require training or ground truth data, and can be applied in the presence of independent noise, as well as correlated (coherent) noise, where the noise level is unknown. We examine three study cases: natural image denoising in the presence of additive white Gaussian noise, Poisson-distributed image denoising, and speckle suppression in optical coherence tomography (OCT). Experimental results demonstrate that the proposed approach can effectively improve image quality, in challenging noise settings. Theoretical guarantees are provided for convergence stability.
DiffSCI: Zero-Shot Snapshot Compressive Imaging via Iterative Spectral Diffusion Model
Nov 19, 2023
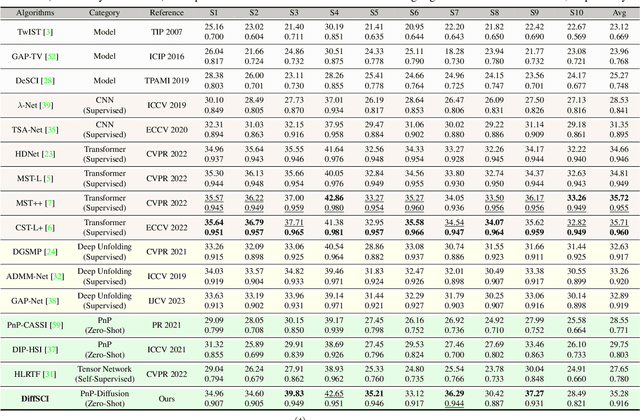
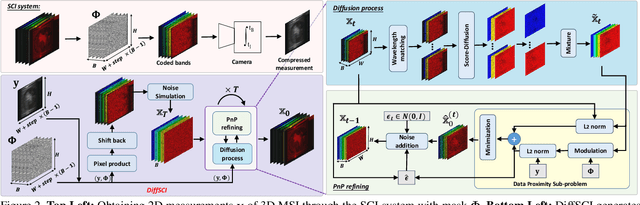
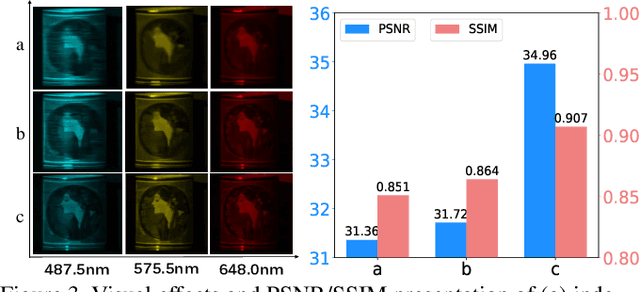
This paper endeavors to advance the precision of snapshot compressive imaging (SCI) reconstruction for multispectral image (MSI). To achieve this, we integrate the advantageous attributes of established SCI techniques and an image generative model, propose a novel structured zero-shot diffusion model, dubbed DiffSCI. DiffSCI leverages the structural insights from the deep prior and optimization-based methodologies, complemented by the generative capabilities offered by the contemporary denoising diffusion model. Specifically, firstly, we employ a pre-trained diffusion model, which has been trained on a substantial corpus of RGB images, as the generative denoiser within the Plug-and-Play framework for the first time. This integration allows for the successful completion of SCI reconstruction, especially in the case that current methods struggle to address effectively. Secondly, we systematically account for spectral band correlations and introduce a robust methodology to mitigate wavelength mismatch, thus enabling seamless adaptation of the RGB diffusion model to MSIs. Thirdly, an accelerated algorithm is implemented to expedite the resolution of the data subproblem. This augmentation not only accelerates the convergence rate but also elevates the quality of the reconstruction process. We present extensive testing to show that DiffSCI exhibits discernible performance enhancements over prevailing self-supervised and zero-shot approaches, surpassing even supervised transformer counterparts across both simulated and real datasets. Our code will be available.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 19, 2023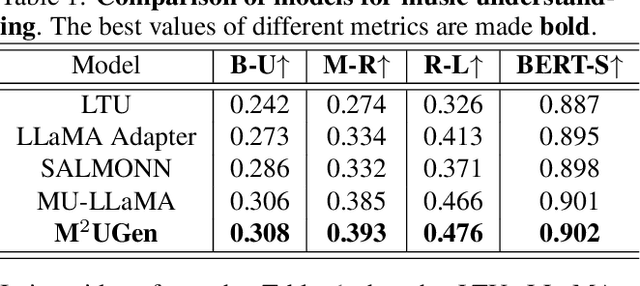
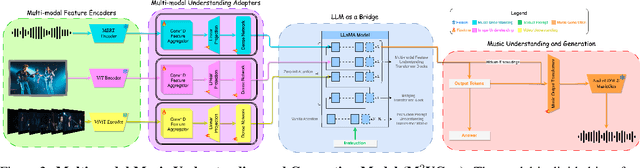
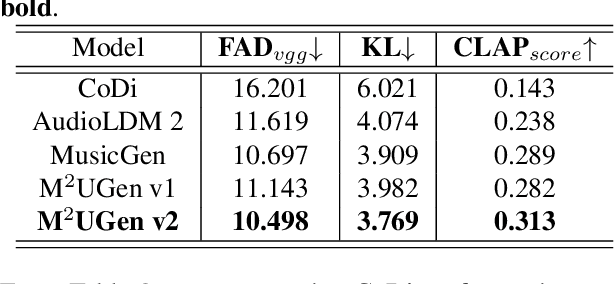
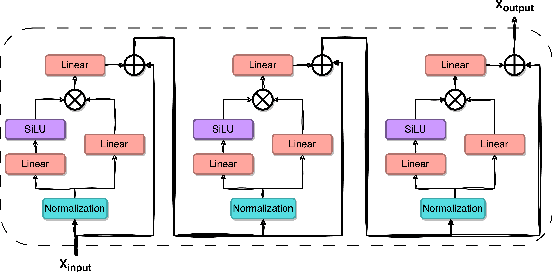
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
Revisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Oct 26, 2023Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.
Bayesian Methods for Media Mix Modelling with shape and funnel effects
Nov 21, 2023In recent years, significant progress in generative AI has highlighted the important role of physics-inspired models that utilize advanced mathematical concepts based on fundamental physics principles to enhance artificial intelligence capabilities. Among these models, those based on diffusion equations have greatly improved image quality. This study aims to explore the potential uses of Maxwell-Boltzmann equation, which forms the basis of the kinetic theory of gases, and the Michaelis-Menten model in Marketing Mix Modelling (MMM) applications. We propose incorporating these equations into Hierarchical Bayesian models to analyse consumer behaviour in the context of advertising. These equation sets excel in accurately describing the random dynamics in complex systems like social interactions and consumer-advertising interactions.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 20, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
Energy efficiency in Edge TPU vs. embedded GPU for computer-aided medical imaging segmentation and classification
Nov 20, 2023In this work, we evaluate the energy usage of fully embedded medical diagnosis aids based on both segmentation and classification of medical images implemented on Edge TPU and embedded GPU processors. We use glaucoma diagnosis based on color fundus images as an example to show the possibility of performing segmentation and classification in real time on embedded boards and to highlight the different energy requirements of the studied implementations. Several other works develop the use of segmentation and feature extraction techniques to detect glaucoma, among many other pathologies, with deep neural networks. Memory limitations and low processing capabilities of embedded accelerated systems (EAS) limit their use for deep network-based system training. However, including specific acceleration hardware, such as NVIDIA's Maxwell GPU or Google's Edge TPU, enables them to perform inferences using complex pre-trained networks in very reasonable times. In this study, we evaluate the timing and energy performance of two EAS equipped with Machine Learning (ML) accelerators executing an example diagnostic tool developed in a previous work. For optic disc (OD) and cup (OC) segmentation, the obtained prediction times per image are under 29 and 43 ms using Edge TPUs and Maxwell GPUs, respectively. Prediction times for the classification subsystem are lower than 10 and 14 ms for Edge TPUs and Maxwell GPUs, respectively. Regarding energy usage, in approximate terms, for OD segmentation Edge TPUs and Maxwell GPUs use 38 and 190 mJ per image, respectively. For fundus classification, Edge TPUs and Maxwell GPUs use 45 and 70 mJ, respectively.
* 37 pages, 20 figures. Accepted manuscript. Published in "Engineering Applications of Artificial Intelligence" (Elsevier), ISSN 0952-1976
Detecting Spurious Correlations via Robust Visual Concepts in Real and AI-Generated Image Classification
Nov 16, 2023Often machine learning models tend to automatically learn associations present in the training data without questioning their validity or appropriateness. This undesirable property is the root cause of the manifestation of spurious correlations, which render models unreliable and prone to failure in the presence of distribution shifts. Research shows that most methods attempting to remedy spurious correlations are only effective for a model's known spurious associations. Current spurious correlation detection algorithms either rely on extensive human annotations or are too restrictive in their formulation. Moreover, they rely on strict definitions of visual artifacts that may not apply to data produced by generative models, as they are known to hallucinate contents that do not conform to standard specifications. In this work, we introduce a general-purpose method that efficiently detects potential spurious correlations, and requires significantly less human interference in comparison to the prior art. Additionally, the proposed method provides intuitive explanations while eliminating the need for pixel-level annotations. We demonstrate the proposed method's tolerance to the peculiarity of AI-generated images, which is a considerably challenging task, one where most of the existing methods fall short. Consequently, our method is also suitable for detecting spurious correlations that may propagate to downstream applications originating from generative models.
Dimma: Semi-supervised Low Light Image Enhancement with Adaptive Dimming
Oct 14, 2023Enhancing low-light images while maintaining natural colors is a challenging problem due to camera processing variations and limited access to photos with ground-truth lighting conditions. The latter is a crucial factor for supervised methods that achieve good results on paired datasets but do not handle out-of-domain data well. On the other hand, unsupervised methods, while able to generalize, often yield lower-quality enhancements. To fill this gap, we propose Dimma, a semi-supervised approach that aligns with any camera by utilizing a small set of image pairs to replicate scenes captured under extreme lighting conditions taken by that specific camera. We achieve that by introducing a convolutional mixture density network that generates distorted colors of the scene based on the illumination differences. Additionally, our approach enables accurate grading of the dimming factor, which provides a wide range of control and flexibility in adjusting the brightness levels during the low-light image enhancement process. To further improve the quality of our results, we introduce an architecture based on a conditional UNet. The lightness value provided by the user serves as the conditional input to generate images with the desired lightness. Our approach using only few image pairs achieves competitive results compared to fully supervised methods. Moreover, when trained on the full dataset, our model surpasses state-of-the-art methods in some metrics and closely approaches them in others.
Transformer-based Image Compression with Variable Image Quality Objectives
Sep 22, 2023This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.