 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diversified and Personalized Multi-rater Medical Image Segmentation
Mar 20, 2024
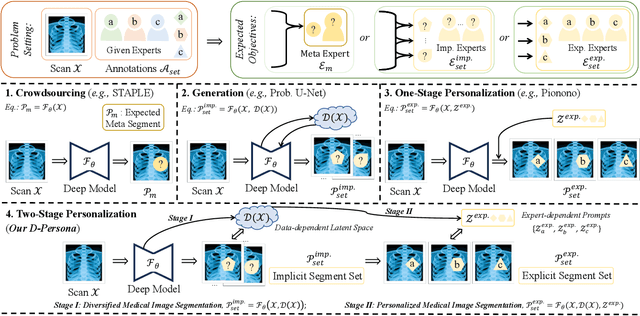
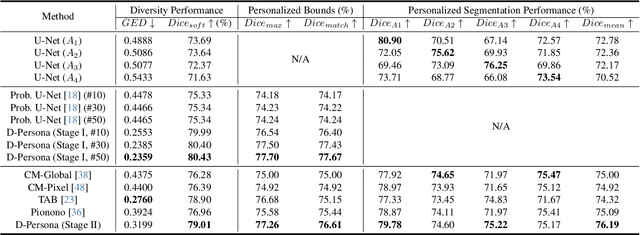
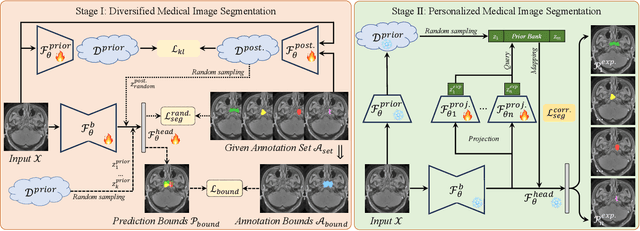
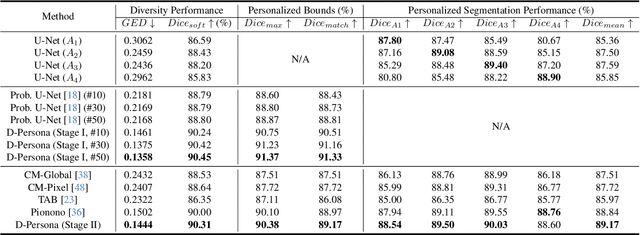
Annotation ambiguity due to inherent data uncertainties such as blurred boundaries in medical scans and different observer expertise and preferences has become a major obstacle for training deep-learning based medical image segmentation models. To address it, the common practice is to gather multiple annotations from different experts, leading to the setting of multi-rater medical image segmentation. Existing works aim to either merge different annotations into the "groundtruth" that is often unattainable in numerous medical contexts, or generate diverse results, or produce personalized results corresponding to individual expert raters. Here, we bring up a more ambitious goal for multi-rater medical image segmentation, i.e., obtaining both diversified and personalized results. Specifically, we propose a two-stage framework named D-Persona (first Diversification and then Personalization). In Stage I, we exploit multiple given annotations to train a Probabilistic U-Net model, with a bound-constrained loss to improve the prediction diversity. In this way, a common latent space is constructed in Stage I, where different latent codes denote diversified expert opinions. Then, in Stage II, we design multiple attention-based projection heads to adaptively query the corresponding expert prompts from the shared latent space, and then perform the personalized medical image segmentation. We evaluated the proposed model on our in-house Nasopharyngeal Carcinoma dataset and the public lung nodule dataset (i.e., LIDC-IDRI). Extensive experiments demonstrated our D-Persona can provide diversified and personalized results at the same time, achieving new SOTA performance for multi-rater medical image segmentation. Our code will be released at https://github.com/ycwu1997/D-Persona.
Multimodal-Conditioned Latent Diffusion Models for Fashion Image Editing
Mar 25, 2024Fashion illustration is a crucial medium for designers to convey their creative vision and transform design concepts into tangible representations that showcase the interplay between clothing and the human body. In the context of fashion design, computer vision techniques have the potential to enhance and streamline the design process. Departing from prior research primarily focused on virtual try-on, this paper tackles the task of multimodal-conditioned fashion image editing. Our approach aims to generate human-centric fashion images guided by multimodal prompts, including text, human body poses, garment sketches, and fabric textures. To address this problem, we propose extending latent diffusion models to incorporate these multiple modalities and modifying the structure of the denoising network, taking multimodal prompts as input. To condition the proposed architecture on fabric textures, we employ textual inversion techniques and let diverse cross-attention layers of the denoising network attend to textual and texture information, thus incorporating different granularity conditioning details. Given the lack of datasets for the task, we extend two existing fashion datasets, Dress Code and VITON-HD, with multimodal annotations. Experimental evaluations demonstrate the effectiveness of our proposed approach in terms of realism and coherence concerning the provided multimodal inputs.
Dual-modal Prior Semantic Guided Infrared and Visible Image Fusion for Intelligent Transportation System
Mar 24, 2024Infrared and visible image fusion (IVF) plays an important role in intelligent transportation system (ITS). The early works predominantly focus on boosting the visual appeal of the fused result, and only several recent approaches have tried to combine the high-level vision task with IVF. However, they prioritize the design of cascaded structure to seek unified suitable features and fit different tasks. Thus, they tend to typically bias toward to reconstructing raw pixels without considering the significance of semantic features. Therefore, we propose a novel prior semantic guided image fusion method based on the dual-modality strategy, improving the performance of IVF in ITS. Specifically, to explore the independent significant semantic of each modality, we first design two parallel semantic segmentation branches with a refined feature adaptive-modulation (RFaM) mechanism. RFaM can perceive the features that are semantically distinct enough in each semantic segmentation branch. Then, two pilot experiments based on the two branches are conducted to capture the significant prior semantic of two images, which then is applied to guide the fusion task in the integration of semantic segmentation branches and fusion branches. In addition, to aggregate both high-level semantics and impressive visual effects, we further investigate the frequency response of the prior semantics, and propose a multi-level representation-adaptive fusion (MRaF) module to explicitly integrate the low-frequent prior semantic with the high-frequent details. Extensive experiments on two public datasets demonstrate the superiority of our method over the state-of-the-art image fusion approaches, in terms of either the visual appeal or the high-level semantics.
Integrative Graph-Transformer Framework for Histopathology Whole Slide Image Representation and Classification
Mar 26, 2024In digital pathology, the multiple instance learning (MIL) strategy is widely used in the weakly supervised histopathology whole slide image (WSI) classification task where giga-pixel WSIs are only labeled at the slide level. However, existing attention-based MIL approaches often overlook contextual information and intrinsic spatial relationships between neighboring tissue tiles, while graph-based MIL frameworks have limited power to recognize the long-range dependencies. In this paper, we introduce the integrative graph-transformer framework that simultaneously captures the context-aware relational features and global WSI representations through a novel Graph Transformer Integration (GTI) block. Specifically, each GTI block consists of a Graph Convolutional Network (GCN) layer modeling neighboring relations at the local instance level and an efficient global attention model capturing comprehensive global information from extensive feature embeddings. Extensive experiments on three publicly available WSI datasets: TCGA-NSCLC, TCGA-RCC and BRIGHT, demonstrate the superiority of our approach over current state-of-the-art MIL methods, achieving an improvement of 1.0% to 2.6% in accuracy and 0.7%-1.6% in AUROC.
GT-Rain Single Image Deraining Challenge Report
Mar 18, 2024
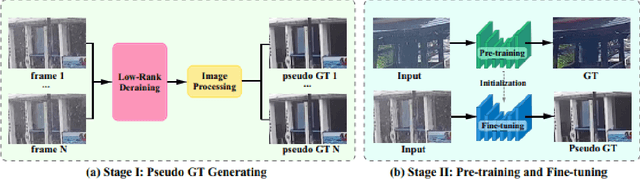
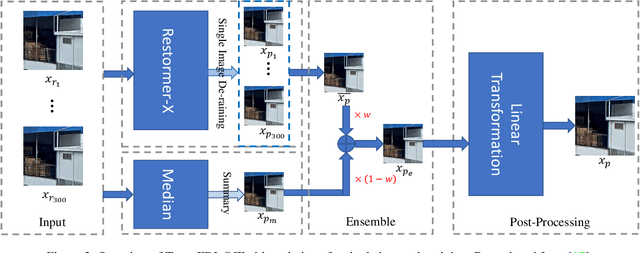
This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation
Mar 21, 2024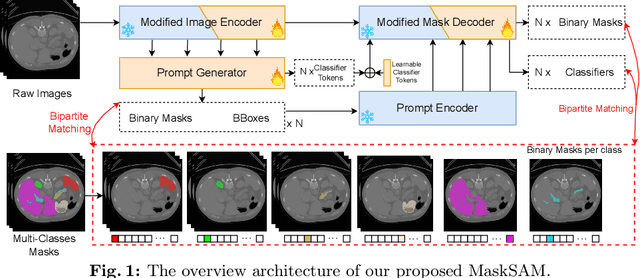
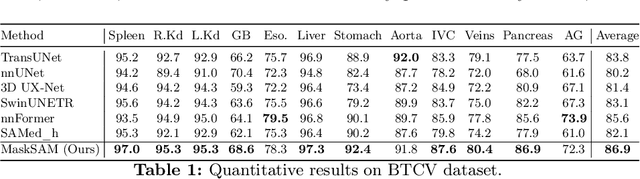
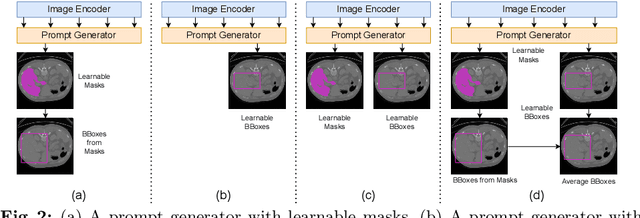
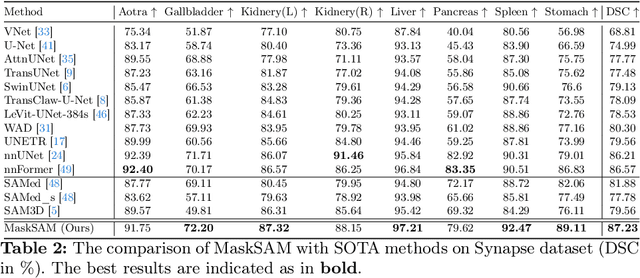
Segment Anything Model~(SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM does not work when directly applied to medical image segmentation tasks, since SAM lacks the functionality to predict semantic labels for predicted masks and needs to provide extra prompts, such as points or boxes, to segment target regions. Meanwhile, there is a huge gap between 2D natural images and 3D medical images, so the performance of SAM is imperfect for medical image segmentation tasks. Following the above issues, we propose MaskSAM, a novel mask classification prompt-free SAM adaptation framework for medical image segmentation. We design a prompt generator combined with the image encoder in SAM to generate a set of auxiliary classifier tokens, auxiliary binary masks, and auxiliary bounding boxes. Each pair of auxiliary mask and box prompts, which can solve the requirements of extra prompts, is associated with class label predictions by the sum of the auxiliary classifier token and the learnable global classifier tokens in the mask decoder of SAM to solve the predictions of semantic labels. Meanwhile, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings. We inject one of them into each transformer block in the image encoder and mask decoder to enable pre-trained 2D SAM models to extract 3D information and adapt to 3D medical images. Our method achieves state-of-the-art performance on AMOS2022, 90.52% Dice, which improved by 2.7% compared to nnUNet. Our method surpasses nnUNet by 1.7% on ACDC and 1.0% on Synapse datasets.
Diffusion Deepfake
Apr 02, 2024Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
Latent Diffusion Models for Attribute-Preserving Image Anonymization
Mar 21, 2024Generative techniques for image anonymization have great potential to generate datasets that protect the privacy of those depicted in the images, while achieving high data fidelity and utility. Existing methods have focused extensively on preserving facial attributes, but failed to embrace a more comprehensive perspective that considers the scene and background into the anonymization process. This paper presents, to the best of our knowledge, the first approach to image anonymization based on Latent Diffusion Models (LDMs). Every element of a scene is maintained to convey the same meaning, yet manipulated in a way that makes re-identification difficult. We propose two LDMs for this purpose: CAMOUFLaGE-Base exploits a combination of pre-trained ControlNets, and a new controlling mechanism designed to increase the distance between the real and anonymized images. CAMOFULaGE-Light is based on the Adapter technique, coupled with an encoding designed to efficiently represent the attributes of different persons in a scene. The former solution achieves superior performance on most metrics and benchmarks, while the latter cuts the inference time in half at the cost of fine-tuning a lightweight module. We show through extensive experimental comparison that the proposed method is competitive with the state-of-the-art concerning identity obfuscation whilst better preserving the original content of the image and tackling unresolved challenges that current solutions fail to address.
Generalized Consistency Trajectory Models for Image Manipulation
Mar 19, 2024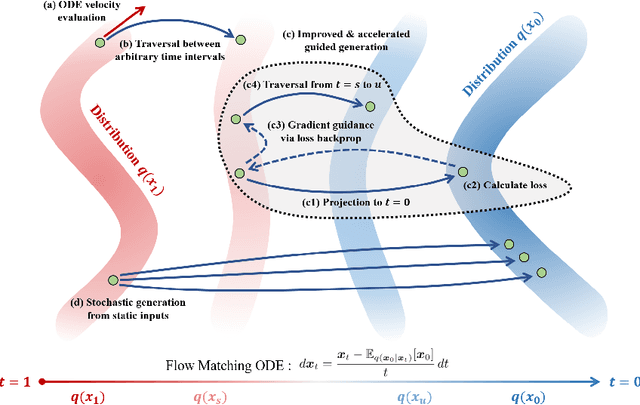

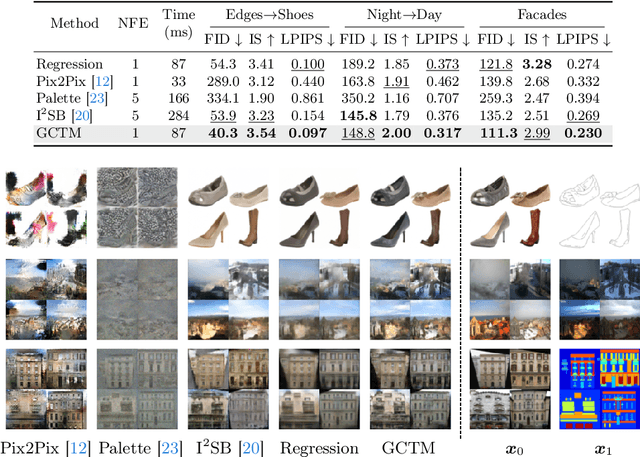
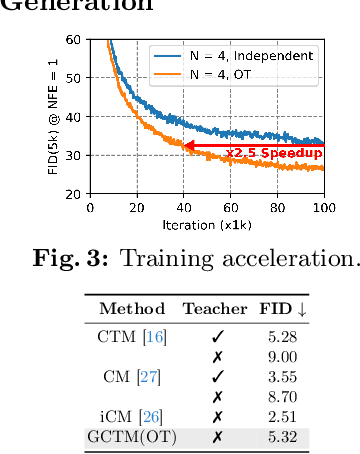
Diffusion-based generative models excel in unconditional generation, as well as on applied tasks such as image editing and restoration. The success of diffusion models lies in the iterative nature of diffusion: diffusion breaks down the complex process of mapping noise to data into a sequence of simple denoising tasks. Moreover, we are able to exert fine-grained control over the generation process by injecting guidance terms into each denoising step. However, the iterative process is also computationally intensive, often taking from tens up to thousands of function evaluations. Although consistency trajectory models (CTMs) enable traversal between any time points along the probability flow ODE (PFODE) and score inference with a single function evaluation, CTMs only allow translation from Gaussian noise to data. Thus, this work aims to unlock the full potential of CTMs by proposing generalized CTMs (GCTMs), which translate between arbitrary distributions via ODEs. We discuss the design space of GCTMs and demonstrate their efficacy in various image manipulation tasks such as image-to-image translation, restoration, and editing. Code: \url{https://github.com/1202kbs/GCTM}
CLIP-VQDiffusion : Langauge Free Training of Text To Image generation using CLIP and vector quantized diffusion model
Mar 22, 2024There has been a significant progress in text conditional image generation models. Recent advancements in this field depend not only on improvements in model structures, but also vast quantities of text-image paired datasets. However, creating these kinds of datasets is very costly and requires a substantial amount of labor. Famous face datasets don't have corresponding text captions, making it difficult to develop text conditional image generation models on these datasets. Some research has focused on developing text to image generation models using only images without text captions. Here, we propose CLIP-VQDiffusion, which leverage the pretrained CLIP model to provide multimodal text-image representations and strong image generation capabilities. On the FFHQ dataset, our model outperformed previous state-of-the-art methods by 4.4% in clipscore and generated very realistic images even when the text was both in and out of distribution. The pretrained models and codes will soon be available at https://github.com/INFINIQ-AI1/CLIPVQDiffusion