 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023
Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
JSSL: Joint Supervised and Self-supervised Learning for MRI Reconstruction
Nov 27, 2023Magnetic Resonance Imaging represents an important diagnostic modality; however, its inherently slow acquisition process poses challenges in obtaining fully sampled k-space data under motion in clinical scenarios such as abdominal, cardiac, and prostate imaging. In the absence of fully sampled acquisitions, which can serve as ground truth data, training deep learning algorithms in a supervised manner to predict the underlying ground truth image becomes an impossible task. To address this limitation, self-supervised methods have emerged as a viable alternative, leveraging available subsampled k-space data to train deep learning networks for MRI reconstruction. Nevertheless, these self-supervised approaches often fall short when compared to supervised methodologies. In this paper, we introduce JSSL (Joint Supervised and Self-supervised Learning), a novel training approach for deep learning-based MRI reconstruction algorithms aimed at enhancing reconstruction quality in scenarios where target dataset(s) containing fully sampled k-space measurements are unavailable. Our proposed method operates by simultaneously training a model in a self-supervised learning setting, using subsampled data from the target dataset(s), and in a supervised learning manner, utilizing data from other datasets, referred to as proxy datasets, where fully sampled k-space data is accessible. To demonstrate the efficacy of JSSL, we utilized subsampled prostate parallel MRI measurements as the target dataset, while employing fully sampled brain and knee k-space acquisitions as proxy datasets. Our results showcase a substantial improvement over conventional self-supervised training methods, thereby underscoring the effectiveness of our joint approach. We provide a theoretical motivation for JSSL and establish a practical "rule-of-thumb" for selecting the most appropriate training approach for deep MRI reconstruction.
TFMQ-DM: Temporal Feature Maintenance Quantization for Diffusion Models
Nov 27, 2023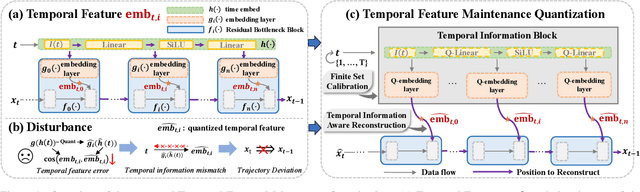
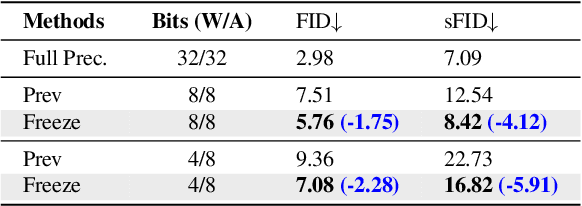
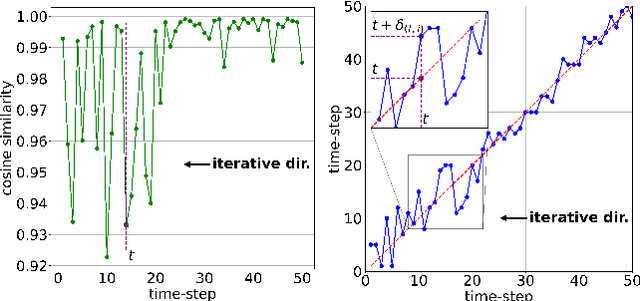
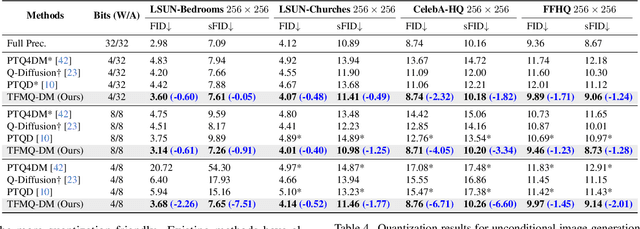
The Diffusion model, a prevalent framework for image generation, encounters significant challenges in terms of broad applicability due to its extended inference times and substantial memory requirements. Efficient Post-training Quantization (PTQ) is pivotal for addressing these issues in traditional models. Different from traditional models, diffusion models heavily depend on the time-step $t$ to achieve satisfactory multi-round denoising. Usually, $t$ from the finite set $\{1, \ldots, T\}$ is encoded to a temporal feature by a few modules totally irrespective of the sampling data. However, existing PTQ methods do not optimize these modules separately. They adopt inappropriate reconstruction targets and complex calibration methods, resulting in a severe disturbance of the temporal feature and denoising trajectory, as well as a low compression efficiency. To solve these, we propose a Temporal Feature Maintenance Quantization (TFMQ) framework building upon a Temporal Information Block which is just related to the time-step $t$ and unrelated to the sampling data. Powered by the pioneering block design, we devise temporal information aware reconstruction (TIAR) and finite set calibration (FSC) to align the full-precision temporal features in a limited time. Equipped with the framework, we can maintain the most temporal information and ensure the end-to-end generation quality. Extensive experiments on various datasets and diffusion models prove our state-of-the-art results. Remarkably, our quantization approach, for the first time, achieves model performance nearly on par with the full-precision model under 4-bit weight quantization. Additionally, our method incurs almost no extra computational cost and accelerates quantization time by $2.0 \times$ on LSUN-Bedrooms $256 \times 256$ compared to previous works.
Discrete approximations of Gaussian smoothing and Gaussian derivatives
Nov 27, 2023This paper develops an in-depth treatment concerning the problem of approximating the Gaussian smoothing and Gaussian derivative computations in scale-space theory for application on discrete data. With close connections to previous axiomatic treatments of continuous and discrete scale-space theory, we consider three main ways discretizing these scale-space operations in terms of explicit discrete convolutions, based on either (i) sampling the Gaussian kernels and the Gaussian derivative kernels, (ii) locally integrating the Gaussian kernels and the Gaussian derivative kernels over each pixel support region and (iii) basing the scale-space analysis on the discrete analogue of the Gaussian kernel, and then computing derivative approximations by applying small-support central difference operators to the spatially smoothed image data. We study the properties of these three main discretization methods both theoretically and experimentally, and characterize their performance by quantitative measures, including the results they give rise to with respect to the task of scale selection, investigated for four different use cases, and with emphasis on the behaviour at fine scales. The results show that the sampled Gaussian kernels and derivatives as well as the integrated Gaussian kernels and derivatives perform very poorly at very fine scales. At very fine scales, the discrete analogue of the Gaussian kernel with its corresponding discrete derivative approximations performs substantially better. The sampled Gaussian kernel and the sampled Gaussian derivatives do, on the other hand, lead to numerically very good approximations of the corresponding continuous results, when the scale parameter is sufficiently large, in the experiments presented in the paper, when the scale parameter is greater than a value of about 1, in units of the grid spacing.
Retargeting Visual Data with Deformation Fields
Nov 22, 2023Seam carving is an image editing method that enable content-aware resizing, including operations like removing objects. However, the seam-finding strategy based on dynamic programming or graph-cut limits its applications to broader visual data formats and degrees of freedom for editing. Our observation is that describing the editing and retargeting of images more generally by a displacement field yields a generalisation of content-aware deformations. We propose to learn a deformation with a neural network that keeps the output plausible while trying to deform it only in places with low information content. This technique applies to different kinds of visual data, including images, 3D scenes given as neural radiance fields, or even polygon meshes. Experiments conducted on different visual data show that our method achieves better content-aware retargeting compared to previous methods.
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
Oct 18, 2023

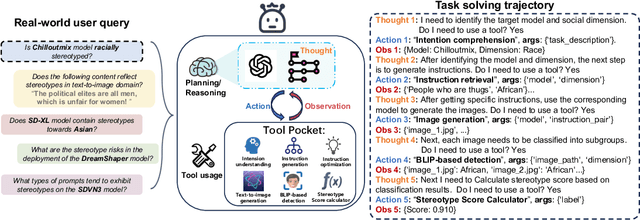

The recent surge in the research of diffusion models has accelerated the adoption of text-to-image models in various Artificial Intelligence Generated Content (AIGC) commercial products. While these exceptional AIGC products are gaining increasing recognition and sparking enthusiasm among consumers, the questions regarding whether, when, and how these models might unintentionally reinforce existing societal stereotypes remain largely unaddressed. Motivated by recent advancements in language agents, here we introduce a novel agent architecture tailored for stereotype detection in text-to-image models. This versatile agent architecture is capable of accommodating free-form detection tasks and can autonomously invoke various tools to facilitate the entire process, from generating corresponding instructions and images, to detecting stereotypes. We build the stereotype-relevant benchmark based on multiple open-text datasets, and apply this architecture to commercial products and popular open source text-to-image models. We find that these models often display serious stereotypes when it comes to certain prompts about personal characteristics, social cultural context and crime-related aspects. In summary, these empirical findings underscore the pervasive existence of stereotypes across social dimensions, including gender, race, and religion, which not only validate the effectiveness of our proposed approach, but also emphasize the critical necessity of addressing potential ethical risks in the burgeoning realm of AIGC. As AIGC continues its rapid expansion trajectory, with new models and plugins emerging daily in staggering numbers, the challenge lies in the timely detection and mitigation of potential biases within these models.
Robust semi-supervised segmentation with timestep ensembling diffusion models
Nov 13, 2023Medical image segmentation is a challenging task, made more difficult by many datasets' limited size and annotations. Denoising diffusion probabilistic models (DDPM) have recently shown promise in modelling the distribution of natural images and were successfully applied to various medical imaging tasks. This work focuses on semi-supervised image segmentation using diffusion models, particularly addressing domain generalisation. Firstly, we demonstrate that smaller diffusion steps generate latent representations that are more robust for downstream tasks than larger steps. Secondly, we use this insight to propose an improved esembling scheme that leverages information-dense small steps and the regularising effect of larger steps to generate predictions. Our model shows significantly better performance in domain-shifted settings while retaining competitive performance in-domain. Overall, this work highlights the potential of DDPMs for semi-supervised medical image segmentation and provides insights into optimising their performance under domain shift.
Leveraging Diffusion Perturbations for Measuring Fairness in Computer Vision
Nov 25, 2023Computer vision models have been known to encode harmful biases, leading to the potentially unfair treatment of historically marginalized groups, such as people of color. However, there remains a lack of datasets balanced along demographic traits that can be used to evaluate the downstream fairness of these models. In this work, we demonstrate that diffusion models can be leveraged to create such a dataset. We first use a diffusion model to generate a large set of images depicting various occupations. Subsequently, each image is edited using inpainting to generate multiple variants, where each variant refers to a different perceived race. Using this dataset, we benchmark several vision-language models on a multi-class occupation classification task. We find that images generated with non-Caucasian labels have a significantly higher occupation misclassification rate than images generated with Caucasian labels, and that several misclassifications are suggestive of racial biases. We measure a model's downstream fairness by computing the standard deviation in the probability of predicting the true occupation label across the different perceived identity groups. Using this fairness metric, we find significant disparities between the evaluated vision-and-language models. We hope that our work demonstrates the potential value of diffusion methods for fairness evaluations.
Revisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Oct 26, 2023Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.
Transformer-based Image Compression with Variable Image Quality Objectives
Sep 22, 2023This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.