 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Residual CNN for Multi-Class Chest Infection Diagnosis
Nov 17, 2023
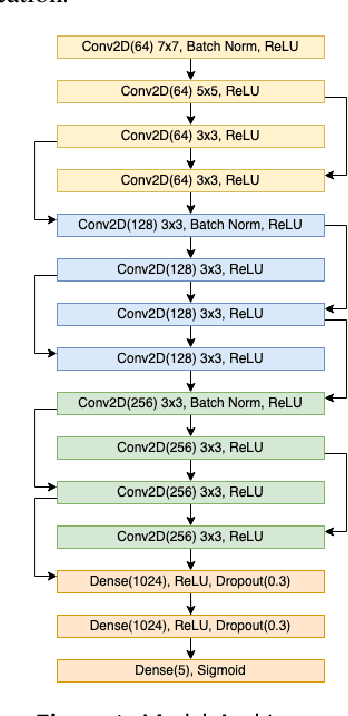
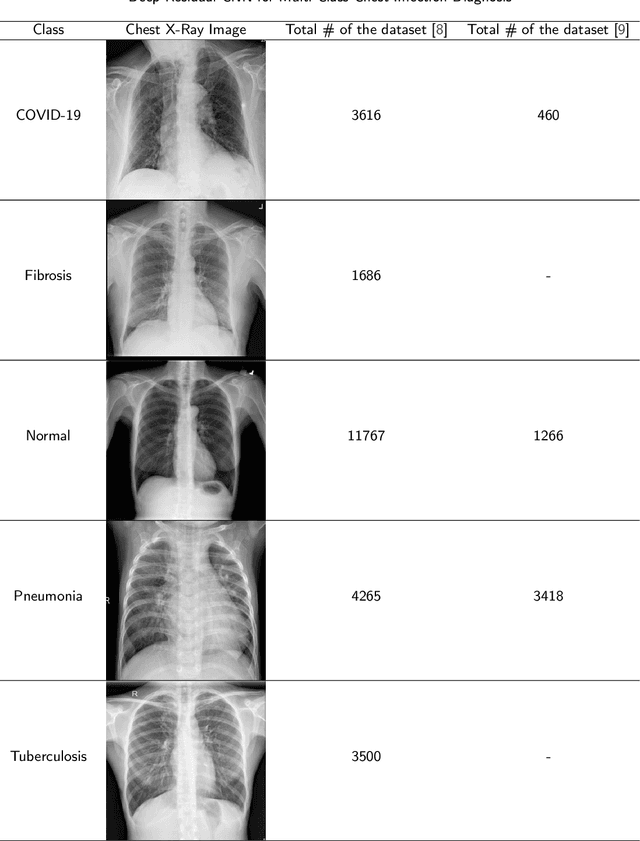
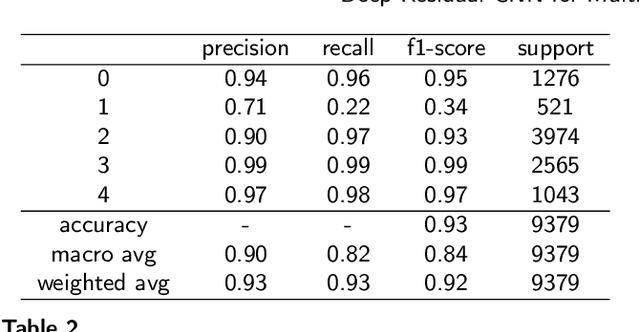
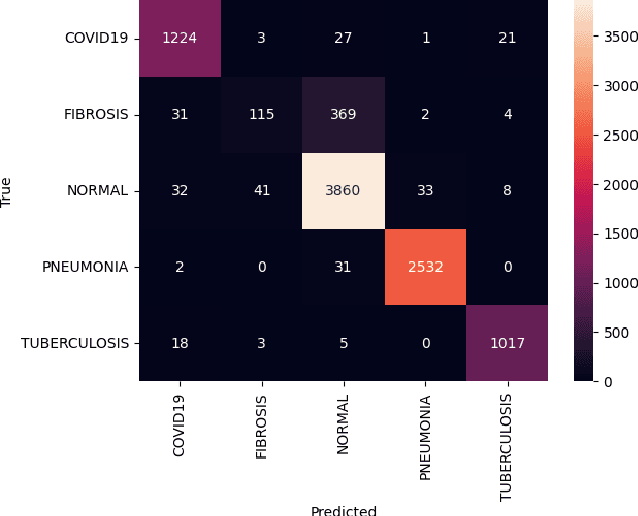
The advent of deep learning has significantly propelled the capabilities of automated medical image diagnosis, providing valuable tools and resources in the realm of healthcare and medical diagnostics. This research delves into the development and evaluation of a Deep Residual Convolutional Neural Network (CNN) for the multi-class diagnosis of chest infections, utilizing chest X-ray images. The implemented model, trained and validated on a dataset amalgamated from diverse sources, demonstrated a robust overall accuracy of 93%. However, nuanced disparities in performance across different classes, particularly Fibrosis, underscored the complexity and challenges inherent in automated medical image diagnosis. The insights derived pave the way for future research, focusing on enhancing the model's proficiency in classifying conditions that present more subtle and nuanced visual features in the images, as well as optimizing and refining the model architecture and training process. This paper provides a comprehensive exploration into the development, implementation, and evaluation of the model, offering insights and directions for future research and development in the field.
Deep Interactive Segmentation of Medical Images: A Systematic Review and Taxonomy
Nov 23, 2023Interactive segmentation is a crucial research area in medical image analysis aiming to boost the efficiency of costly annotations by incorporating human feedback. This feedback takes the form of clicks, scribbles, or masks and allows for iterative refinement of the model output so as to efficiently guide the system towards the desired behavior. In recent years, deep learning-based approaches have propelled results to a new level causing a rapid growth in the field with 121 methods proposed in the medical imaging domain alone. In this review, we provide a structured overview of this emerging field featuring a comprehensive taxonomy, a systematic review of existing methods, and an in-depth analysis of current practices. Based on these contributions, we discuss the challenges and opportunities in the field. For instance, we find that there is a severe lack of comparison across methods which needs to be tackled by standardized baselines and benchmarks.
Some Like It Small: Czech Semantic Embedding Models for Industry Applications
Nov 23, 2023This article focuses on the development and evaluation of Small-sized Czech sentence embedding models. Small models are important components for real-time industry applications in resource-constrained environments. Given the limited availability of labeled Czech data, alternative approaches, including pre-training, knowledge distillation, and unsupervised contrastive fine-tuning, are investigated. Comprehensive intrinsic and extrinsic analyses are conducted, showcasing the competitive performance of our models compared to significantly larger counterparts, with approximately 8 times smaller size and 5 times faster speed than conventional Base-sized models. To promote cooperation and reproducibility, both the models and the evaluation pipeline are made publicly accessible. Ultimately, this article presents practical applications of the developed sentence embedding models in Seznam.cz, the Czech search engine. These models have effectively replaced previous counterparts, enhancing the overall search experience for instance, in organic search, featured snippets, and image search. This transition has yielded improved performance.
Unveiling The Factors of Aesthetic Preferences with Explainable AI
Nov 24, 2023The allure of aesthetic appeal in images captivates our senses, yet the underlying intricacies of aesthetic preferences remain elusive. In this study, we pioneer a novel perspective by utilizing machine learning models that focus on aesthetic attributes known to influence preferences. Through a data mining approach, our models process these attributes as inputs to predict the aesthetic scores of images. Moreover, to delve deeper and obtain interpretable explanations regarding the factors driving aesthetic preferences, we utilize the popular Explainable AI (XAI) technique known as SHapley Additive exPlanations (SHAP). Our methodology involves employing various machine learning models, including Random Forest, XGBoost, Support Vector Regression, and Multilayer Perceptron, to compare their performances in accurately predicting aesthetic scores, and consistently observing results in conjunction with SHAP. We conduct experiments on three image aesthetic benchmarks, providing insights into the roles of attributes and their interactions. Ultimately, our study aims to shed light on the complex nature of aesthetic preferences in images through machine learning and provides a deeper understanding of the attributes that influence aesthetic judgements.
Highly Detailed and Temporal Consistent Video Stylization via Synchronized Multi-Frame Diffusion
Nov 24, 2023Text-guided video-to-video stylization transforms the visual appearance of a source video to a different appearance guided on textual prompts. Existing text-guided image diffusion models can be extended for stylized video synthesis. However, they struggle to generate videos with both highly detailed appearance and temporal consistency. In this paper, we propose a synchronized multi-frame diffusion framework to maintain both the visual details and the temporal consistency. Frames are denoised in a synchronous fashion, and more importantly, information of different frames is shared since the beginning of the denoising process. Such information sharing ensures that a consensus, in terms of the overall structure and color distribution, among frames can be reached in the early stage of the denoising process before it is too late. The optical flow from the original video serves as the connection, and hence the venue for information sharing, among frames. We demonstrate the effectiveness of our method in generating high-quality and diverse results in extensive experiments. Our method shows superior qualitative and quantitative results compared to state-of-the-art video editing methods.
Pseudo-label Correction for Instance-dependent Noise Using Teacher-student Framework
Nov 24, 2023The high capacity of deep learning models to learn complex patterns poses a significant challenge when confronted with label noise. The inability to differentiate clean and noisy labels ultimately results in poor generalization. We approach this problem by reassigning the label for each image using a new teacher-student based framework termed P-LC (pseudo-label correction). Traditional teacher-student networks are composed of teacher and student classifiers for knowledge distillation. In our novel approach, we reconfigure the teacher network into a triple encoder, leveraging the triplet loss to establish a pseudo-label correction system. As the student generates pseudo labels for a set of given images, the teacher learns to choose between the initially assigned labels and the pseudo labels. Experiments on MNIST, Fashion-MNIST, and SVHN demonstrate P-LC's superior performance over existing state-of-the-art methods across all noise levels, most notably in high noise. In addition, we introduce a noise level estimation to help assess model performance and inform the need for additional data cleaning procedures.
InceptionCaps: A Performant Glaucoma Classification Model for Data-scarce Environment
Nov 24, 2023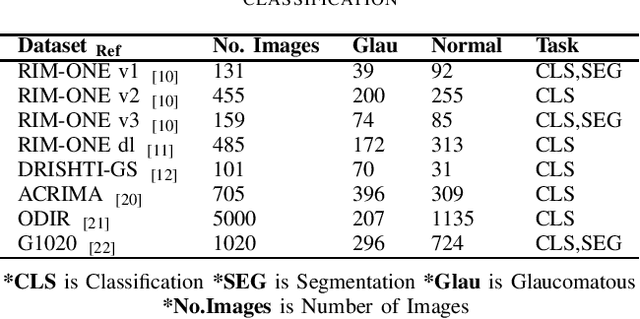
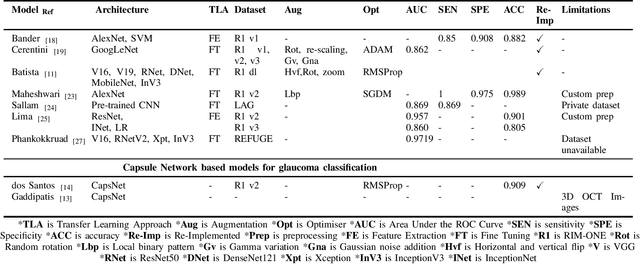
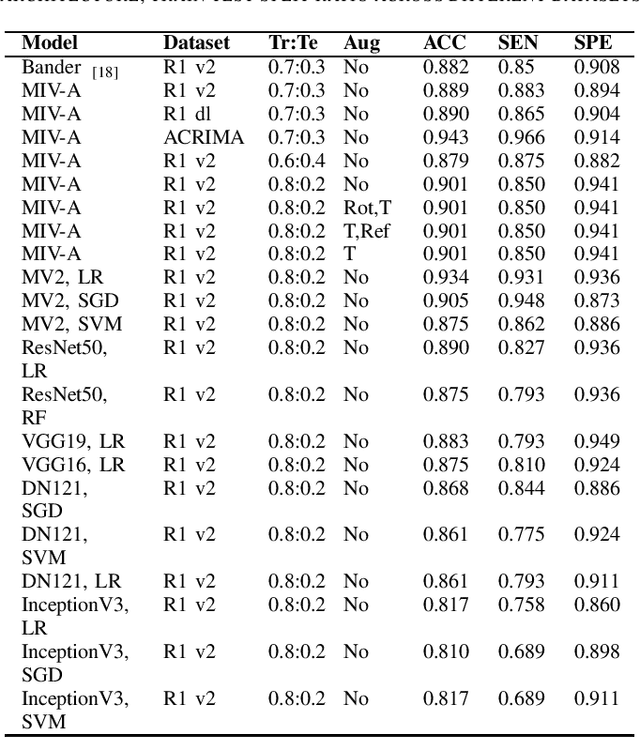
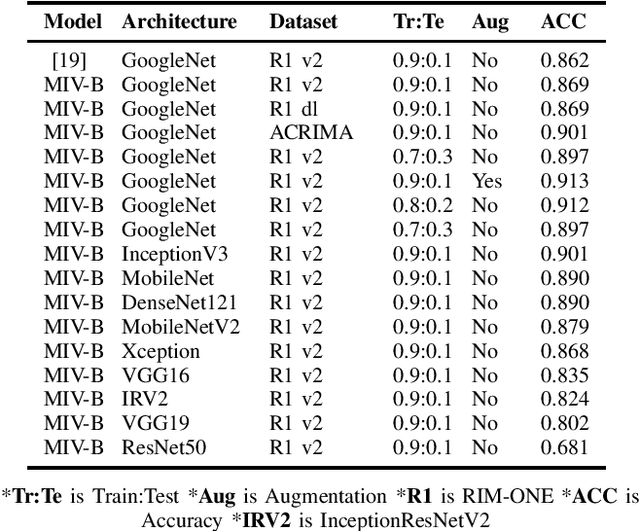
Glaucoma is an irreversible ocular disease and is the second leading cause of visual disability worldwide. Slow vision loss and the asymptomatic nature of the disease make its diagnosis challenging. Early detection is crucial for preventing irreversible blindness. Ophthalmologists primarily use retinal fundus images as a non-invasive screening method. Convolutional neural networks (CNN) have demonstrated high accuracy in the classification of medical images. Nevertheless, CNN's translation-invariant nature and inability to handle the part-whole relationship between objects make its direct application unsuitable for glaucomatous fundus image classification, as it requires a large number of labelled images for training. This work reviews existing state of the art models and proposes InceptionCaps, a novel capsule network (CapsNet) based deep learning model having pre-trained InceptionV3 as its convolution base, for automatic glaucoma classification. InceptionCaps achieved an accuracy of 0.956, specificity of 0.96, and AUC of 0.9556, which surpasses several state-of-the-art deep learning model performances on the RIM-ONE v2 dataset. The obtained result demonstrates the robustness of the proposed deep learning model.
Image Denoising via Style Disentanglement
Sep 26, 2023
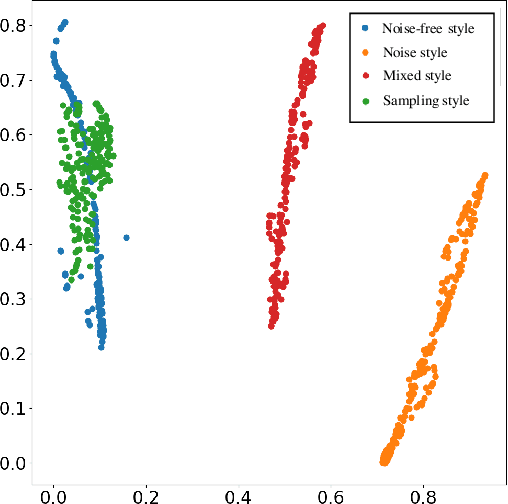

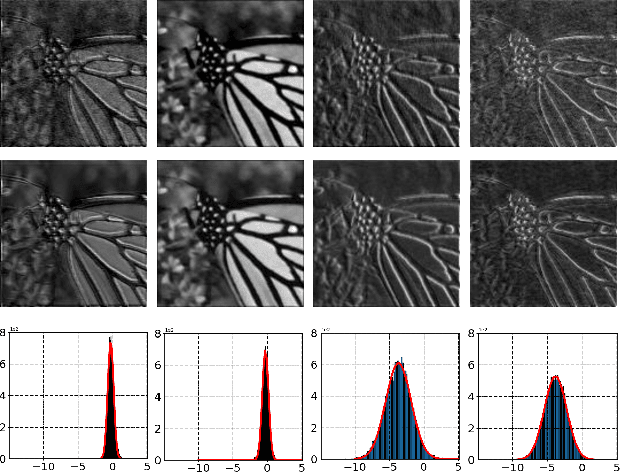
Image denoising is a fundamental task in low-level computer vision. While recent deep learning-based image denoising methods have achieved impressive performance, they are black-box models and the underlying denoising principle remains unclear. In this paper, we propose a novel approach to image denoising that offers both clear denoising mechanism and good performance. We view noise as a type of image style and remove it by incorporating noise-free styles derived from clean images. To achieve this, we design novel losses and network modules to extract noisy styles from noisy images and noise-free styles from clean images. The noise-free style induces low-response activations for noise features and high-response activations for content features in the feature space. This leads to the separation of clean contents from noise, effectively denoising the image. Unlike disentanglement-based image editing tasks that edit semantic-level attributes using styles, our main contribution lies in editing pixel-level attributes through global noise-free styles. We conduct extensive experiments on synthetic noise removal and real-world image denoising datasets (SIDD and DND), demonstrating the effectiveness of our method in terms of both PSNR and SSIM metrics. Moreover, we experimentally validate that our method offers good interpretability.
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
Oct 18, 2023

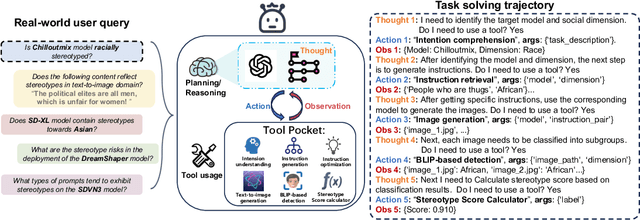

The recent surge in the research of diffusion models has accelerated the adoption of text-to-image models in various Artificial Intelligence Generated Content (AIGC) commercial products. While these exceptional AIGC products are gaining increasing recognition and sparking enthusiasm among consumers, the questions regarding whether, when, and how these models might unintentionally reinforce existing societal stereotypes remain largely unaddressed. Motivated by recent advancements in language agents, here we introduce a novel agent architecture tailored for stereotype detection in text-to-image models. This versatile agent architecture is capable of accommodating free-form detection tasks and can autonomously invoke various tools to facilitate the entire process, from generating corresponding instructions and images, to detecting stereotypes. We build the stereotype-relevant benchmark based on multiple open-text datasets, and apply this architecture to commercial products and popular open source text-to-image models. We find that these models often display serious stereotypes when it comes to certain prompts about personal characteristics, social cultural context and crime-related aspects. In summary, these empirical findings underscore the pervasive existence of stereotypes across social dimensions, including gender, race, and religion, which not only validate the effectiveness of our proposed approach, but also emphasize the critical necessity of addressing potential ethical risks in the burgeoning realm of AIGC. As AIGC continues its rapid expansion trajectory, with new models and plugins emerging daily in staggering numbers, the challenge lies in the timely detection and mitigation of potential biases within these models.
Beyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Nov 18, 2023Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.