 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Nov 08, 2023
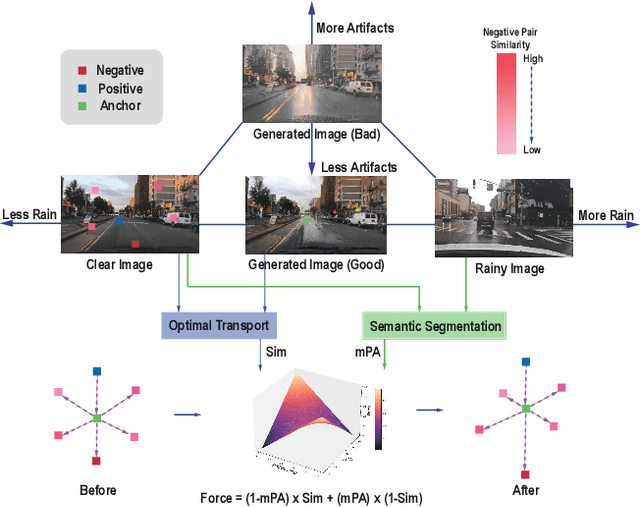

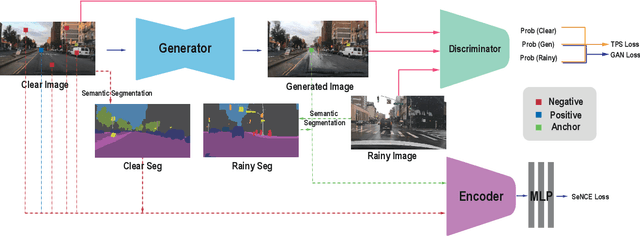
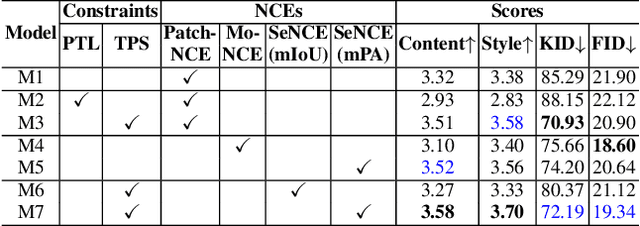
Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability. Code is available at https://github.com/ShenZheng2000/TPSeNCE.
Zero-shot Translation of Attention Patterns in VQA Models to Natural Language
Nov 08, 2023Converting a model's internals to text can yield human-understandable insights about the model. Inspired by the recent success of training-free approaches for image captioning, we propose ZS-A2T, a zero-shot framework that translates the transformer attention of a given model into natural language without requiring any training. We consider this in the context of Visual Question Answering (VQA). ZS-A2T builds on a pre-trained large language model (LLM), which receives a task prompt, question, and predicted answer, as inputs. The LLM is guided to select tokens which describe the regions in the input image that the VQA model attended to. Crucially, we determine this similarity by exploiting the text-image matching capabilities of the underlying VQA model. Our framework does not require any training and allows the drop-in replacement of different guiding sources (e.g. attribution instead of attention maps), or language models. We evaluate this novel task on textual explanation datasets for VQA, giving state-of-the-art performances for the zero-shot setting on GQA-REX and VQA-X. Our code is available at: https://github.com/ExplainableML/ZS-A2T.
Covering Number of Real Algebraic Varieties and Beyond: Improved Bounds and Applications
Nov 16, 2023We prove an upper bound on the covering number of real algebraic varieties, images of polynomial maps and semialgebraic sets. The bound remarkably improves the best known general bound by Yomdin-Comte, and its proof is much more straightforward. As a consequence, our result gives new bounds on the volume of the tubular neighborhood of the image of a polynomial map and a semialgebraic set, where results for varieties by Lotz and Basu-Lerario are not directly applicable. We apply our theory to three main application domains. Firstly, we derive a near-optimal bound on the covering number of low rank CP tensors. Secondly, we prove a bound on the sketching dimension for (general) polynomial optimization problems. Lastly, we deduce generalization error bounds for deep neural networks with rational or ReLU activations, improving or matching the best known results in the literature.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Nov 16, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
ZeroI2V: Zero-Cost Adaptation of Pre-trained Transformers from Image to Video
Oct 02, 2023Adapting image models to video domain is becoming an efficient paradigm for solving video recognition tasks. Due to the huge number of parameters and effective transferability of image models, performing full fine-tuning is less efficient and even unnecessary. Thus, recent research is shifting its focus towards parameter-efficient image-to-video adaptation. However, these adaptation strategies inevitably introduce extra computational cost to deal with the domain gap and temporal modeling in videos. In this paper, our goal is to present a zero-cost adaptation paradigm (ZeroI2V) to transfer the image transformers to video recognition tasks (i.e., introduce zero extra cost to the adapted models during inference). To achieve this goal, we present two core designs. First, to capture the dynamics in videos and reduce the difficulty of achieving image-to-video adaptation, we exploit the flexibility of self-attention and introduce the spatial-temporal dual-headed attention (STDHA) that efficiently endow the image transformers with temporal modeling capability at zero extra parameters and computation. Second, to handle the domain gap between images and videos, we propose a linear adaption strategy which utilizes lightweight densely placed linear adapters to fully transfer the frozen image models to video recognition. Due to its customized linear design, all newly added adapters could be easily merged with the original modules through structural reparameterization after training, thus achieving zero extra cost during inference. Extensive experiments on four widely-used video recognition benchmarks show that our ZeroI2V can match or even outperform previous state-of-the-art methods while enjoying superior parameter and inference efficiency.
Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Oct 14, 2023Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.
Expanding Scene Graph Boundaries: Fully Open-vocabulary Scene Graph Generation via Visual-Concept Alignment and Retention
Nov 18, 2023Scene Graph Generation (SGG) offers a structured representation critical in many computer vision applications. Traditional SGG approaches, however, are limited by a closed-set assumption, restricting their ability to recognize only predefined object and relation categories. To overcome this, we categorize SGG scenarios into four distinct settings based on the node and edge: Closed-set SGG, Open Vocabulary (object) Detection-based SGG (OvD-SGG), Open Vocabulary Relation-based SGG (OvR-SGG), and Open Vocabulary Detection + Relation-based SGG (OvD+R-SGG). While object-centric open vocabulary SGG has been studied recently, the more challenging problem of relation-involved open-vocabulary SGG remains relatively unexplored. To fill this gap, we propose a unified framework named OvSGTR towards fully open vocabulary SGG from a holistic view. The proposed framework is an end-toend transformer architecture, which learns a visual-concept alignment for both nodes and edges, enabling the model to recognize unseen categories. For the more challenging settings of relation-involved open vocabulary SGG, the proposed approach integrates relation-aware pre-training utilizing image-caption data and retains visual-concept alignment through knowledge distillation. Comprehensive experimental results on the Visual Genome benchmark demonstrate the effectiveness and superiority of the proposed framework.
Auxiliary Losses for Learning Generalizable Concept-based Models
Nov 18, 2023The increasing use of neural networks in various applications has lead to increasing apprehensions, underscoring the necessity to understand their operations beyond mere final predictions. As a solution to enhance model transparency, Concept Bottleneck Models (CBMs) have gained popularity since their introduction. CBMs essentially limit the latent space of a model to human-understandable high-level concepts. While beneficial, CBMs have been reported to often learn irrelevant concept representations that consecutively damage model performance. To overcome the performance trade-off, we propose cooperative-Concept Bottleneck Model (coop-CBM). The concept representation of our model is particularly meaningful when fine-grained concept labels are absent. Furthermore, we introduce the concept orthogonal loss (COL) to encourage the separation between the concept representations and to reduce the intra-concept distance. This paper presents extensive experiments on real-world datasets for image classification tasks, namely CUB, AwA2, CelebA and TIL. We also study the performance of coop-CBM models under various distributional shift settings. We show that our proposed method achieves higher accuracy in all distributional shift settings even compared to the black-box models with the highest concept accuracy.
An evaluation of pre-trained models for feature extraction in image classification
Oct 03, 2023In recent years, we have witnessed a considerable increase in performance in image classification tasks. This performance improvement is mainly due to the adoption of deep learning techniques. Generally, deep learning techniques demand a large set of annotated data, making it a challenge when applying it to small datasets. In this scenario, transfer learning strategies have become a promising alternative to overcome these issues. This work aims to compare the performance of different pre-trained neural networks for feature extraction in image classification tasks. We evaluated 16 different pre-trained models in four image datasets. Our results demonstrate that the best general performance along the datasets was achieved by CLIP-ViT-B and ViT-H-14, where the CLIP-ResNet50 model had similar performance but with less variability. Therefore, our study provides evidence supporting the choice of models for feature extraction in image classification tasks.
Enhancing Recommender System Performance by Histogram Equalization
Nov 15, 2023Recommender system has been researched for decades with millions of different versions of algorithms created in the industry. In spite of the huge amount of work spent on the field, there are many basic questions to be answered in the field. The most fundamental question to be answered is the accuracy problem, and in recent years, fairness becomes the new buzz word for researchers. In this paper, we borrow an idea from image processing, namely, histogram equalization. As a preprocessing step to recommender system algorithms, histogram equalization could enhance both the accuracy and fairness metrics of the recommender system algorithms. In the experiment section, we prove that our new approach could improve vanilla algorithms by a large margin in accuracy metric and stay competitive on fairness metrics.