 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Label Embedding -- Measuring classification difficulty
Nov 15, 2023
Uncertainty quantification in machine learning is a timely and vast field of research. In supervised learning, uncertainty can already occur in the very first stage of the training process, the labelling step. In particular, this is the case when not every instance can be unambiguously classified. The problem occurs for classifying instances, where classes may overlap or instances can not be clearly categorised. In other words, there is inevitable ambiguity in the annotation step and not necessarily a 'ground truth'. We look exemplary at the classification of satellite images. Each image is annotated independently by multiple labellers and classified into local climate zones (LCZs). For each instance we have multiple votes, leading to a distribution of labels rather than a single value. The main idea of this work is that we do not assume a ground truth label but embed the votes into a K-dimensional space, with K as the number of possible categories. The embedding is derived from the voting distribution in a Bayesian setup, modelled via a Dirichlet-Multinomial model. We estimate the model and posteriors using a stochastic Expectation Maximisation algorithm with Markov Chain Monte Carlo steps. While we focus on the particular example of LCZ classification, the methods developed in this paper readily extend to other situations where multiple annotators independently label texts or images. We also apply our approach to two other benchmark datasets for image classification to demonstrate this. Besides the embeddings themselves, we can investigate the resulting correlation matrices, which can be seen as generalised confusion matrices and reflect the semantic similarities of the original classes very well for all three exemplary datasets. The insights gained are valuable and can serve as general label embedding if a single ground truth per observation cannot be guaranteed.
Photonic Accelerators for Image Segmentation in Autonomous Driving and Defect Detection
Oct 03, 2023Photonic computing promises faster and more energy-efficient deep neural network (DNN) inference than traditional digital hardware. Advances in photonic computing can have profound impacts on applications such as autonomous driving and defect detection that depend on fast, accurate and energy efficient execution of image segmentation models. In this paper, we investigate image segmentation on photonic accelerators to explore: a) the types of image segmentation DNN architectures that are best suited for photonic accelerators, and b) the throughput and energy efficiency of executing the different image segmentation models on photonic accelerators, along with the trade-offs involved therein. Specifically, we demonstrate that certain segmentation models exhibit negligible loss in accuracy (compared to digital float32 models) when executed on photonic accelerators, and explore the empirical reasoning for their robustness. We also discuss techniques for recovering accuracy in the case of models that do not perform well. Further, we compare throughput (inferences-per-second) and energy consumption estimates for different image segmentation workloads on photonic accelerators. We discuss the challenges and potential optimizations that can help improve the application of photonic accelerators to such computer vision tasks.
Pre- to Post-Contrast Breast MRI Synthesis for Enhanced Tumour Segmentation
Nov 17, 2023Despite its benefits for tumour detection and treatment, the administration of contrast agents in dynamic contrast-enhanced MRI (DCE-MRI) is associated with a range of issues, including their invasiveness, bioaccumulation, and a risk of nephrogenic systemic fibrosis. This study explores the feasibility of producing synthetic contrast enhancements by translating pre-contrast T1-weighted fat-saturated breast MRI to their corresponding first DCE-MRI sequence leveraging the capabilities of a generative adversarial network (GAN). Additionally, we introduce a Scaled Aggregate Measure (SAMe) designed for quantitatively evaluating the quality of synthetic data in a principled manner and serving as a basis for selecting the optimal generative model. We assess the generated DCE-MRI data using quantitative image quality metrics and apply them to the downstream task of 3D breast tumour segmentation. Our results highlight the potential of post-contrast DCE-MRI synthesis in enhancing the robustness of breast tumour segmentation models via data augmentation. Our code is available at https://github.com/RichardObi/pre_post_synthesis.
Supervised structure learning
Nov 17, 2023This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
Uni-COAL: A Unified Framework for Cross-Modality Synthesis and Super-Resolution of MR Images
Nov 14, 2023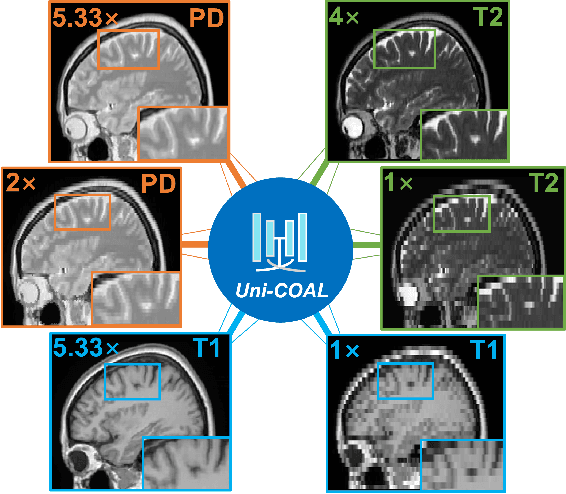
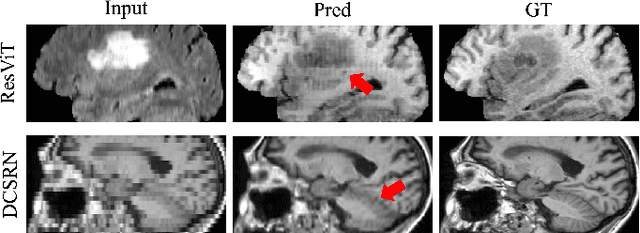
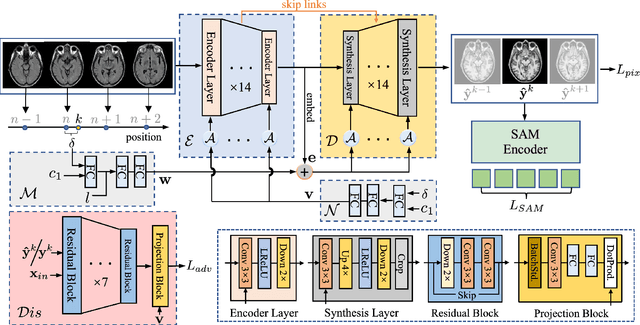
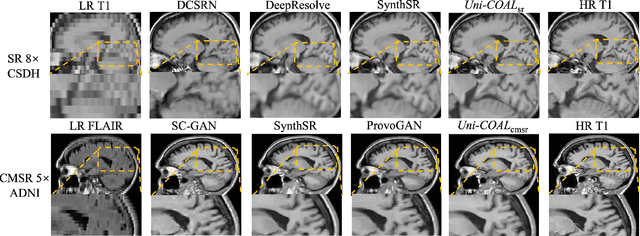
Cross-modality synthesis (CMS), super-resolution (SR), and their combination (CMSR) have been extensively studied for magnetic resonance imaging (MRI). Their primary goals are to enhance the imaging quality by synthesizing the desired modality and reducing the slice thickness. Despite the promising synthetic results, these techniques are often tailored to specific tasks, thereby limiting their adaptability to complex clinical scenarios. Therefore, it is crucial to build a unified network that can handle various image synthesis tasks with arbitrary requirements of modality and resolution settings, so that the resources for training and deploying the models can be greatly reduced. However, none of the previous works is capable of performing CMS, SR, and CMSR using a unified network. Moreover, these MRI reconstruction methods often treat alias frequencies improperly, resulting in suboptimal detail restoration. In this paper, we propose a Unified Co-Modulated Alias-free framework (Uni-COAL) to accomplish the aforementioned tasks with a single network. The co-modulation design of the image-conditioned and stochastic attribute representations ensures the consistency between CMS and SR, while simultaneously accommodating arbitrary combinations of input/output modalities and thickness. The generator of Uni-COAL is also designed to be alias-free based on the Shannon-Nyquist signal processing framework, ensuring effective suppression of alias frequencies. Additionally, we leverage the semantic prior of Segment Anything Model (SAM) to guide Uni-COAL, ensuring a more authentic preservation of anatomical structures during synthesis. Experiments on three datasets demonstrate that Uni-COAL outperforms the alternatives in CMS, SR, and CMSR tasks for MR images, which highlights its generalizability to wide-range applications.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
Unseen Image Synthesis with Diffusion Models
Oct 13, 2023

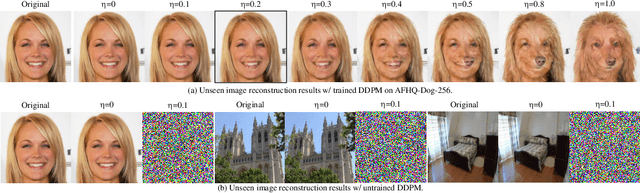
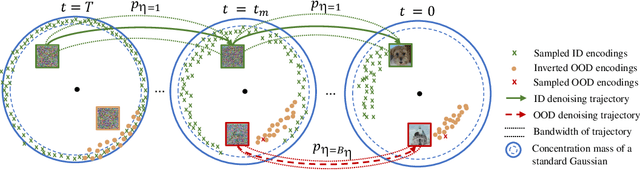
While the current trend in the generative field is scaling up towards larger models and more training data for generalized domain representations, we go the opposite direction in this work by synthesizing unseen domain images without additional training. We do so via latent sampling and geometric optimization using pre-trained and frozen Denoising Diffusion Probabilistic Models (DDPMs) on single-domain datasets. Our key observation is that DDPMs pre-trained even just on single-domain images are already equipped with sufficient representation abilities to reconstruct arbitrary images from the inverted latent encoding following bi-directional deterministic diffusion and denoising trajectories. This motivates us to investigate the statistical and geometric behaviors of the Out-Of-Distribution (OOD) samples from unseen image domains in the latent spaces along the denoising chain. Notably, we theoretically and empirically show that the inverted OOD samples also establish Gaussians that are distinguishable from the original In-Domain (ID) samples in the intermediate latent spaces, which allows us to sample from them directly. Geometrical domain-specific and model-dependent information of the unseen subspace (e.g., sample-wise distance and angles) is used to further optimize the sampled OOD latent encodings from the estimated Gaussian prior. We conduct extensive analysis and experiments using pre-trained diffusion models (DDPM, iDDPM) on different datasets (AFHQ, CelebA-HQ, LSUN-Church, and LSUN-Bedroom), proving the effectiveness of this novel perspective to explore and re-think the diffusion models' data synthesis generalization ability.
AGNES: Abstraction-guided Framework for Deep Neural Networks Security
Nov 07, 2023Deep Neural Networks (DNNs) are becoming widespread, particularly in safety-critical areas. One prominent application is image recognition in autonomous driving, where the correct classification of objects, such as traffic signs, is essential for safe driving. Unfortunately, DNNs are prone to backdoors, meaning that they concentrate on attributes of the image that should be irrelevant for their correct classification. Backdoors are integrated into a DNN during training, either with malicious intent (such as a manipulated training process, because of which a yellow sticker always leads to a traffic sign being recognised as a stop sign) or unintentional (such as a rural background leading to any traffic sign being recognised as animal crossing, because of biased training data). In this paper, we introduce AGNES, a tool to detect backdoors in DNNs for image recognition. We discuss the principle approach on which AGNES is based. Afterwards, we show that our tool performs better than many state-of-the-art methods for multiple relevant case studies.
Can CLIP Help Sound Source Localization?
Nov 07, 2023Large-scale pre-trained image-text models demonstrate remarkable versatility across diverse tasks, benefiting from their robust representational capabilities and effective multimodal alignment. We extend the application of these models, specifically CLIP, to the domain of sound source localization. Unlike conventional approaches, we employ the pre-trained CLIP model without explicit text input, relying solely on the audio-visual correspondence. To this end, we introduce a framework that translates audio signals into tokens compatible with CLIP's text encoder, yielding audio-driven embeddings. By directly using these embeddings, our method generates audio-grounded masks for the provided audio, extracts audio-grounded image features from the highlighted regions, and aligns them with the audio-driven embeddings using the audio-visual correspondence objective. Our findings suggest that utilizing pre-trained image-text models enable our model to generate more complete and compact localization maps for the sounding objects. Extensive experiments show that our method outperforms state-of-the-art approaches by a significant margin.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Nov 16, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.