 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Model Based Referring Camouflaged Object Detection
Nov 28, 2023
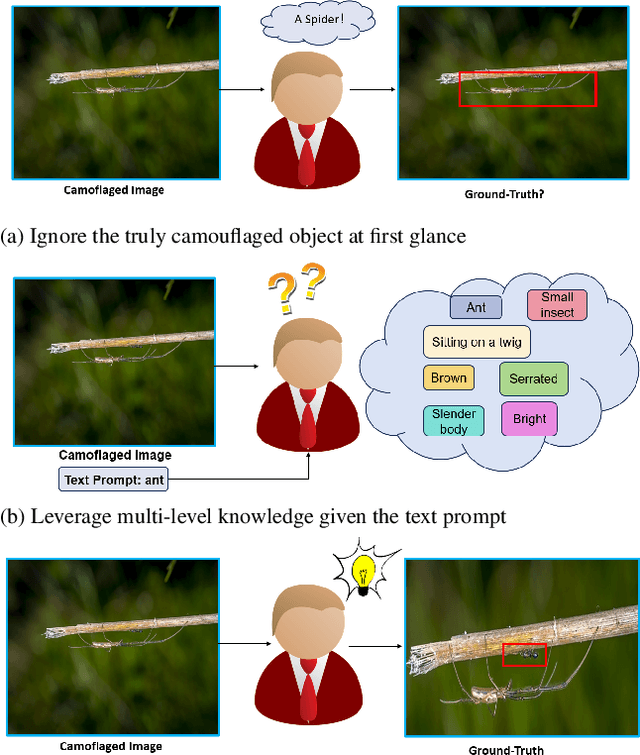
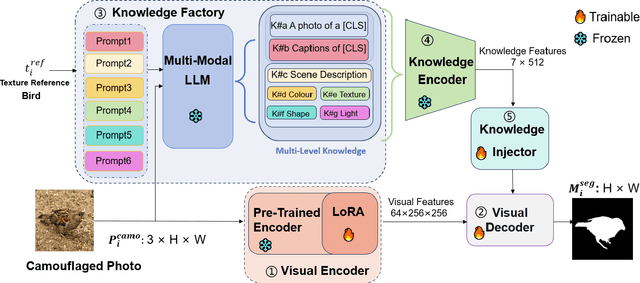

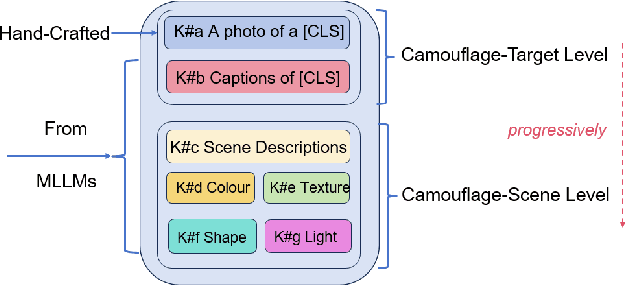
Referring camouflaged object detection (Ref-COD) is a recently-proposed problem aiming to segment out specified camouflaged objects matched with a textual or visual reference. This task involves two major challenges: the COD domain-specific perception and multimodal reference-image alignment. Our motivation is to make full use of the semantic intelligence and intrinsic knowledge of recent Multimodal Large Language Models (MLLMs) to decompose this complex task in a human-like way. As language is highly condensed and inductive, linguistic expression is the main media of human knowledge learning, and the transmission of knowledge information follows a multi-level progression from simplicity to complexity. In this paper, we propose a large-model-based Multi-Level Knowledge-Guided multimodal method for Ref-COD termed MLKG, where multi-level knowledge descriptions from MLLM are organized to guide the large vision model of segmentation to perceive the camouflage-targets and camouflage-scene progressively and meanwhile deeply align the textual references with camouflaged photos. To our knowledge, our contributions mainly include: (1) This is the first time that the MLLM knowledge is studied for Ref-COD and COD. (2) We, for the first time, propose decomposing Ref-COD into two main perspectives of perceiving the target and scene by integrating MLLM knowledge, and contribute a multi-level knowledge-guided method. (3) Our method achieves the state-of-the-art on the Ref-COD benchmark outperforming numerous strong competitors. Moreover, thanks to the injected rich knowledge, it demonstrates zero-shot generalization ability on uni-modal COD datasets. We will release our code soon.
Unified High-binding Watermark for Unconditional Image Generation Models
Oct 14, 2023Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.
Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion
Nov 27, 2023Recent advances in generative AI have unveiled significant potential for the creation of 3D content. However, current methods either apply a pre-trained 2D diffusion model with the time-consuming score distillation sampling (SDS), or a direct 3D diffusion model trained on limited 3D data losing generation diversity. In this work, we approach the problem by employing a multi-view 2.5D diffusion fine-tuned from a pre-trained 2D diffusion model. The multi-view 2.5D diffusion directly models the structural distribution of 3D data, while still maintaining the strong generalization ability of the original 2D diffusion model, filling the gap between 2D diffusion-based and direct 3D diffusion-based methods for 3D content generation. During inference, multi-view normal maps are generated using the 2.5D diffusion, and a novel differentiable rasterization scheme is introduced to fuse the almost consistent multi-view normal maps into a consistent 3D model. We further design a normal-conditioned multi-view image generation module for fast appearance generation given the 3D geometry. Our method is a one-pass diffusion process and does not require any SDS optimization as post-processing. We demonstrate through extensive experiments that, our direct 2.5D generation with the specially-designed fusion scheme can achieve diverse, mode-seeking-free, and high-fidelity 3D content generation in only 10 seconds. Project page: https://nju-3dv.github.io/projects/direct25.
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Nov 27, 2023Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models
Oct 12, 2023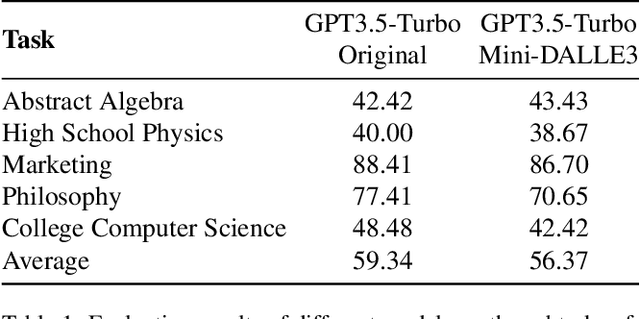
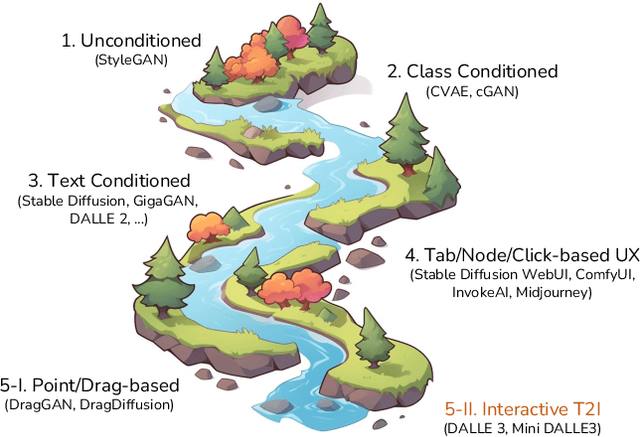
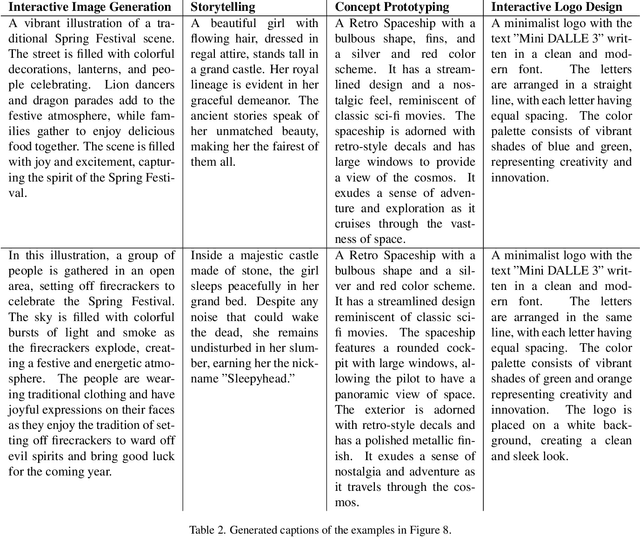

The revolution of artificial intelligence content generation has been rapidly accelerated with the booming text-to-image (T2I) diffusion models. Within just two years of development, it was unprecedentedly of high-quality, diversity, and creativity that the state-of-the-art models could generate. However, a prevalent limitation persists in the effective communication with these popular T2I models, such as Stable Diffusion, using natural language descriptions. This typically makes an engaging image hard to obtain without expertise in prompt engineering with complex word compositions, magic tags, and annotations. Inspired by the recently released DALLE3 - a T2I model directly built-in ChatGPT that talks human language, we revisit the existing T2I systems endeavoring to align human intent and introduce a new task - interactive text to image (iT2I), where people can interact with LLM for interleaved high-quality image generation/edit/refinement and question answering with stronger images and text correspondences using natural language. In addressing the iT2I problem, we present a simple approach that augments LLMs for iT2I with prompting techniques and off-the-shelf T2I models. We evaluate our approach for iT2I in a variety of common-used scenarios under different LLMs, e.g., ChatGPT, LLAMA, Baichuan, and InternLM. We demonstrate that our approach could be a convenient and low-cost way to introduce the iT2I ability for any existing LLMs and any text-to-image models without any training while bringing little degradation on LLMs' inherent capabilities in, e.g., question answering and code generation. We hope this work could draw broader attention and provide inspiration for boosting user experience in human-machine interactions alongside the image quality of the next-generation T2I systems.
You Only Explain Once
Nov 23, 2023In this paper, we propose a new black-box explainability algorithm and tool, YO-ReX, for efficient explanation of the outputs of object detectors. The new algorithm computes explanations for all objects detected in the image simultaneously. Hence, compared to the baseline, the new algorithm reduces the number of queries by a factor of 10X for the case of ten detected objects. The speedup increases further with with the number of objects. Our experimental results demonstrate that YO-ReX can explain the outputs of YOLO with a negligible overhead over the running time of YOLO. We also demonstrate similar results for explaining SSD and Faster R-CNN. The speedup is achieved by avoiding backtracking by combining aggressive pruning with a causal analysis.
Deep Equilibrium Diffusion Restoration with Parallel Sampling
Nov 20, 2023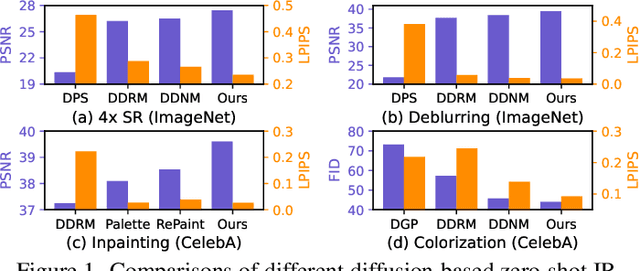
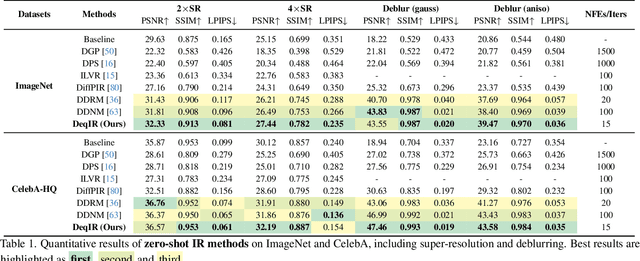
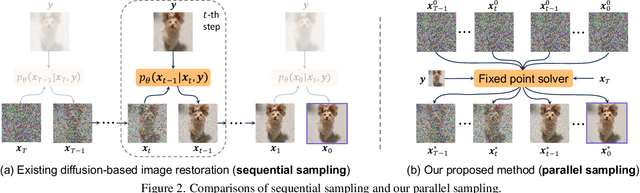
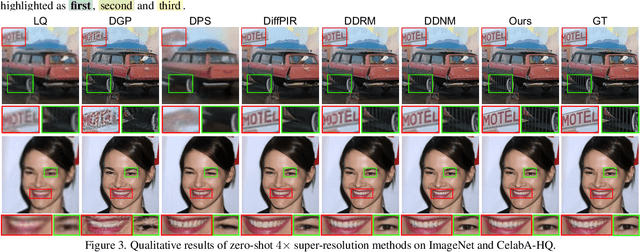
Diffusion-based image restoration (IR) methods aim to use diffusion models to recover high-quality (HQ) images from degraded images and achieve promising performance. Due to the inherent property of diffusion models, most of these methods need long serial sampling chains to restore HQ images step-by-step. As a result, it leads to expensive sampling time and high computation costs. Moreover, such long sampling chains hinder understanding the relationship between the restoration results and the inputs since it is hard to compute the gradients in the whole chains. In this work, we aim to rethink the diffusion-based IR models through a different perspective, i.e., a deep equilibrium (DEQ) fixed point system. Specifically, we derive an analytical solution by modeling the entire sampling chain in diffusion-based IR models as a joint multivariate fixed point system. With the help of the analytical solution, we are able to conduct single-image sampling in a parallel way and restore HQ images without training. Furthermore, we compute fast gradients in DEQ and found that initialization optimization can boost performance and control the generation direction. Extensive experiments on benchmarks demonstrate the effectiveness of our proposed method on typical IR tasks and real-world settings. The code and models will be made publicly available.
Robust Image Watermarking based on Cross-Attention and Invariant Domain Learning
Oct 09, 2023Image watermarking involves embedding and extracting watermarks within a cover image, with deep learning approaches emerging to bolster generalization and robustness. Predominantly, current methods employ convolution and concatenation for watermark embedding, while also integrating conceivable augmentation in the training process. This paper explores a robust image watermarking methodology by harnessing cross-attention and invariant domain learning, marking two novel, significant advancements. First, we design a watermark embedding technique utilizing a multi-head cross attention mechanism, enabling information exchange between the cover image and watermark to identify semantically suitable embedding locations. Second, we advocate for learning an invariant domain representation that encapsulates both semantic and noise-invariant information concerning the watermark, shedding light on promising avenues for enhancing image watermarking techniques.
Multi Task Consistency Guided Source-Free Test-Time Domain Adaptation Medical Image Segmentation
Oct 18, 2023Source-free test-time adaptation for medical image segmentation aims to enhance the adaptability of segmentation models to diverse and previously unseen test sets of the target domain, which contributes to the generalizability and robustness of medical image segmentation models without access to the source domain. Ensuring consistency between target edges and paired inputs is crucial for test-time adaptation. To improve the performance of test-time domain adaptation, we propose a multi task consistency guided source-free test-time domain adaptation medical image segmentation method which ensures the consistency of the local boundary predictions and the global prototype representation. Specifically, we introduce a local boundary consistency constraint method that explores the relationship between tissue region segmentation and tissue boundary localization tasks. Additionally, we propose a global feature consistency constraint toto enhance the intra-class compactness. We conduct extensive experiments on the segmentation of benchmark fundus images. Compared to prediction directly by the source domain model, the segmentation Dice score is improved by 6.27\% and 0.96\% in RIM-ONE-r3 and Drishti GS datasets, respectively. Additionally, the results of experiments demonstrate that our proposed method outperforms existing competitive domain adaptation segmentation algorithms.
Stable Unlearnable Example: Enhancing the Robustness of Unlearnable Examples via Stable Error-Minimizing Noise
Nov 22, 2023The open source of large amounts of image data promotes the development of deep learning techniques. Along with this comes the privacy risk of these open-source image datasets being exploited by unauthorized third parties to train deep learning models for commercial or illegal purposes. To avoid the abuse of public data, a poisoning-based technique, the unlearnable example, is proposed to significantly degrade the generalization performance of models by adding a kind of imperceptible noise to the data. To further enhance its robustness against adversarial training, existing works leverage iterative adversarial training on both the defensive noise and the surrogate model. However, it still remains unknown whether the robustness of unlearnable examples primarily comes from the effect of enhancement in the surrogate model or the defensive noise. Observing that simply removing the adversarial noise on the training process of the defensive noise can improve the performance of robust unlearnable examples, we identify that solely the surrogate model's robustness contributes to the performance. Furthermore, we found a negative correlation exists between the robustness of defensive noise and the protection performance, indicating defensive noise's instability issue. Motivated by this, to further boost the robust unlearnable example, we introduce stable error-minimizing noise (SEM), which trains the defensive noise against random perturbation instead of the time-consuming adversarial perturbation to improve the stability of defensive noise. Through extensive experiments, we demonstrate that SEM achieves a new state-of-the-art performance on CIFAR-10, CIFAR-100, and ImageNet Subset in terms of both effectiveness and efficiency. The code is available at https://github.com/liuyixin-louis/Stable-Unlearnable-Example.