 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DAS: A Deformable Attention to Capture Salient Information in CNNs
Nov 20, 2023
Convolutional Neural Networks (CNNs) excel in local spatial pattern recognition. For many vision tasks, such as object recognition and segmentation, salient information is also present outside CNN's kernel boundaries. However, CNNs struggle in capturing such relevant information due to their confined receptive fields. Self-attention can improve a model's access to global information but increases computational overhead. We present a fast and simple fully convolutional method called DAS that helps focus attention on relevant information. It uses deformable convolutions for the location of pertinent image regions and separable convolutions for efficiency. DAS plugs into existing CNNs and propagates relevant information using a gating mechanism. Compared to the O(n^2) computational complexity of transformer-style attention, DAS is O(n). Our claim is that DAS's ability to pay increased attention to relevant features results in performance improvements when added to popular CNNs for Image Classification and Object Detection. For example, DAS yields an improvement on Stanford Dogs (4.47%), ImageNet (1.91%), and COCO AP (3.3%) with base ResNet50 backbone. This outperforms other CNN attention mechanisms while using similar or less FLOPs. Our code will be publicly available.
AdvGen: Physical Adversarial Attack on Face Presentation Attack Detection Systems
Nov 20, 2023Evaluating the risk level of adversarial images is essential for safely deploying face authentication models in the real world. Popular approaches for physical-world attacks, such as print or replay attacks, suffer from some limitations, like including physical and geometrical artifacts. Recently, adversarial attacks have gained attraction, which try to digitally deceive the learning strategy of a recognition system using slight modifications to the captured image. While most previous research assumes that the adversarial image could be digitally fed into the authentication systems, this is not always the case for systems deployed in the real world. This paper demonstrates the vulnerability of face authentication systems to adversarial images in physical world scenarios. We propose AdvGen, an automated Generative Adversarial Network, to simulate print and replay attacks and generate adversarial images that can fool state-of-the-art PADs in a physical domain attack setting. Using this attack strategy, the attack success rate goes up to 82.01%. We test AdvGen extensively on four datasets and ten state-of-the-art PADs. We also demonstrate the effectiveness of our attack by conducting experiments in a realistic, physical environment.
SDDPM: Speckle Denoising Diffusion Probabilistic Models
Nov 17, 2023Coherent imaging systems, such as medical ultrasound and synthetic aperture radar (SAR), are subject to corruption from speckle due to sub-resolution scatterers. Since speckle is multiplicative in nature, the constituent image regions become corrupted to different extents. The task of denoising such images requires algorithms specifically designed for removing signal-dependent noise. This paper proposes a novel image denoising algorithm for removing signal-dependent multiplicative noise with diffusion models, called Speckle Denoising Diffusion Probabilistic Models (SDDPM). We derive the mathematical formulations for the forward process, the reverse process, and the training objective. In the forward process, we apply multiplicative noise to a given image and prove that the forward process is Gaussian. We show that the reverse process is also Gaussian and the final training objective can be expressed as the Kullback Leibler (KL) divergence between the forward and reverse processes. As derived in the paper, the final denoising task is a single step process, thereby reducing the denoising time significantly. We have trained our model with natural land-use images and ultrasound images for different noise levels. Extensive experiments centered around two different applications show that SDDPM is robust and performs significantly better than the comparative models even when the images are severely corrupted.
Multi-task Planar Reconstruction with Feature Warping Guidance
Nov 25, 2023Piece-wise planar 3D reconstruction simultaneously segments plane instances and recovers their 3D plane parameters from an image, which is particularly useful for indoor or man-made environments. Efficient reconstruction of 3D planes coupled with semantic predictions offers advantages for a wide range of applications requiring scene understanding and concurrent spatial mapping. However, most existing planar reconstruction models either neglect semantic predictions or do not run efficiently enough for real-time applications. We introduce SoloPlanes, a real-time planar reconstruction model based on a modified instance segmentation architecture which simultaneously predicts semantics for each plane instance, along with plane parameters and piece-wise plane instance masks. By providing multi-view guidance in feature space, we achieve an improvement in instance mask segmentation despite only warping plane features due to the nature of feature sharing in multi-task learning. Our model simultaneously predicts semantics using single images at inference time, while achieving real-time predictions at 43 FPS. The code will be released post-publication.
Occlusion Sensitivity Analysis with Augmentation Subspace Perturbation in Deep Feature Space
Nov 25, 2023Deep Learning of neural networks has gained prominence in multiple life-critical applications like medical diagnoses and autonomous vehicle accident investigations. However, concerns about model transparency and biases persist. Explainable methods are viewed as the solution to address these challenges. In this study, we introduce the Occlusion Sensitivity Analysis with Deep Feature Augmentation Subspace (OSA-DAS), a novel perturbation-based interpretability approach for computer vision. While traditional perturbation methods make only use of occlusions to explain the model predictions, OSA-DAS extends standard occlusion sensitivity analysis by enabling the integration with diverse image augmentations. Distinctly, our method utilizes the output vector of a DNN to build low-dimensional subspaces within the deep feature vector space, offering a more precise explanation of the model prediction. The structural similarity between these subspaces encompasses the influence of diverse augmentations and occlusions. We test extensively on the ImageNet-1k, and our class- and model-agnostic approach outperforms commonly used interpreters, setting it apart in the realm of explainable AI.
DA-STC: Domain Adaptive Video Semantic Segmentation via Spatio-Temporal Consistency
Nov 22, 2023Video semantic segmentation is a pivotal aspect of video representation learning. However, significant domain shifts present a challenge in effectively learning invariant spatio-temporal features across the labeled source domain and unlabeled target domain for video semantic segmentation. To solve the challenge, we propose a novel DA-STC method for domain adaptive video semantic segmentation, which incorporates a bidirectional multi-level spatio-temporal fusion module and a category-aware spatio-temporal feature alignment module to facilitate consistent learning for domain-invariant features. Firstly, we perform bidirectional spatio-temporal fusion at the image sequence level and shallow feature level, leading to the construction of two fused intermediate video domains. This prompts the video semantic segmentation model to consistently learn spatio-temporal features of shared patch sequences which are influenced by domain-specific contexts, thereby mitigating the feature gap between the source and target domain. Secondly, we propose a category-aware feature alignment module to promote the consistency of spatio-temporal features, facilitating adaptation to the target domain. Specifically, we adaptively aggregate the domain-specific deep features of each category along spatio-temporal dimensions, which are further constrained to achieve cross-domain intra-class feature alignment and inter-class feature separation. Extensive experiments demonstrate the effectiveness of our method, which achieves state-of-the-art mIOUs on multiple challenging benchmarks. Furthermore, we extend the proposed DA-STC to the image domain, where it also exhibits superior performance for domain adaptive semantic segmentation. The source code and models will be made available at \url{https://github.com/ZHE-SAPI/DA-STC}.
Multi-modal Medical Neurological Image Fusion using Wavelet Pooled Edge Preserving Autoencoder
Oct 18, 2023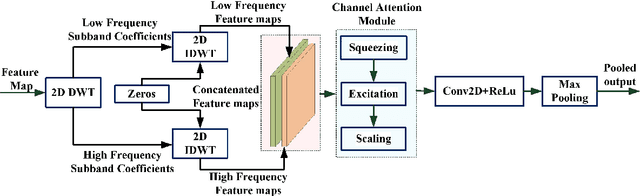
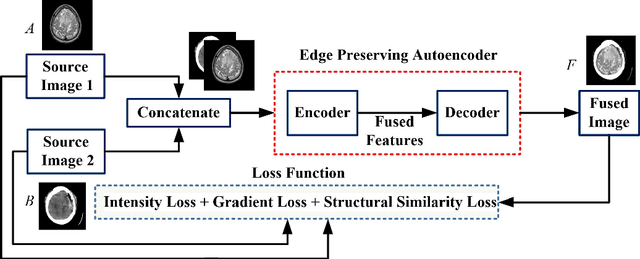
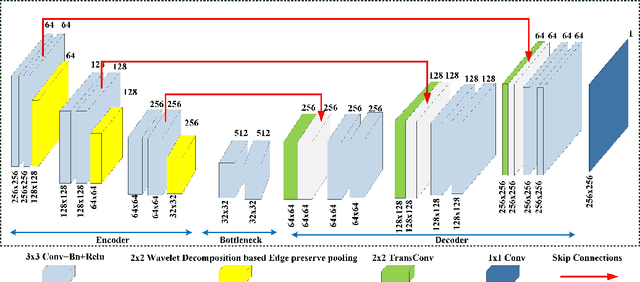
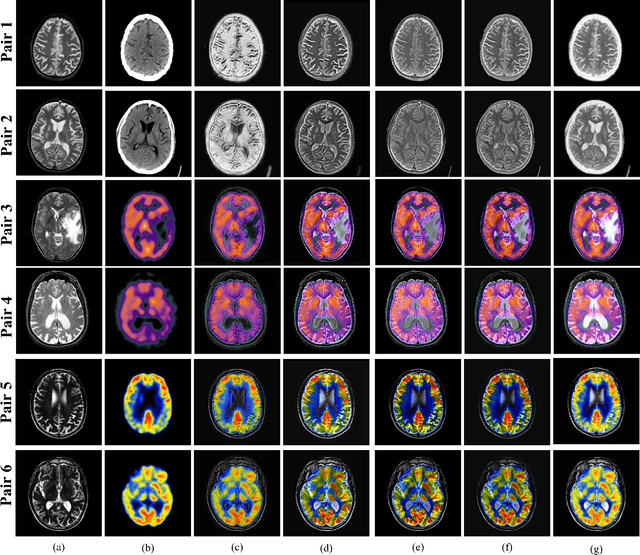
Medical image fusion integrates the complementary diagnostic information of the source image modalities for improved visualization and analysis of underlying anomalies. Recently, deep learning-based models have excelled the conventional fusion methods by executing feature extraction, feature selection, and feature fusion tasks, simultaneously. However, most of the existing convolutional neural network (CNN) architectures use conventional pooling or strided convolutional strategies to downsample the feature maps. It causes the blurring or loss of important diagnostic information and edge details available in the source images and dilutes the efficacy of the feature extraction process. Therefore, this paper presents an end-to-end unsupervised fusion model for multimodal medical images based on an edge-preserving dense autoencoder network. In the proposed model, feature extraction is improved by using wavelet decomposition-based attention pooling of feature maps. This helps in preserving the fine edge detail information present in both the source images and enhances the visual perception of fused images. Further, the proposed model is trained on a variety of medical image pairs which helps in capturing the intensity distributions of the source images and preserves the diagnostic information effectively. Substantial experiments are conducted which demonstrate that the proposed method provides improved visual and quantitative results as compared to the other state-of-the-art fusion methods.
HiFi-123: Towards High-fidelity One Image to 3D Content Generation
Oct 10, 2023

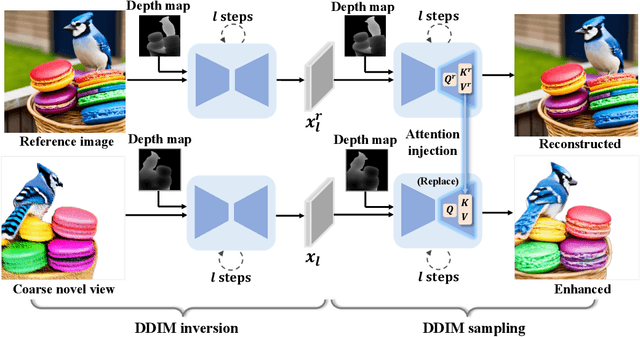

Recent advances in text-to-image diffusion models have enabled 3D generation from a single image. However, current image-to-3D methods often produce suboptimal results for novel views, with blurred textures and deviations from the reference image, limiting their practical applications. In this paper, we introduce HiFi-123, a method designed for high-fidelity and multi-view consistent 3D generation. Our contributions are twofold: First, we propose a reference-guided novel view enhancement technique that substantially reduces the quality gap between synthesized and reference views. Second, capitalizing on the novel view enhancement, we present a novel reference-guided state distillation loss. When incorporated into the optimization-based image-to-3D pipeline, our method significantly improves 3D generation quality, achieving state-of-the-art performance. Comprehensive evaluations demonstrate the effectiveness of our approach over existing methods, both qualitatively and quantitatively.
Predicting breast cancer with AI for individual risk-adjusted MRI screening and early detection
Nov 29, 2023Women with an increased life-time risk of breast cancer undergo supplemental annual screening MRI. We propose to predict the risk of developing breast cancer within one year based on the current MRI, with the objective of reducing screening burden and facilitating early detection. An AI algorithm was developed on 53,858 breasts from 12,694 patients who underwent screening or diagnostic MRI and accrued over 12 years, with 2,331 confirmed cancers. A first U-Net was trained to segment lesions and identify regions of concern. A second convolutional network was trained to detect malignant cancer using features extracted by the U-Net. This network was then fine-tuned to estimate the risk of developing cancer within a year in cases that radiologists considered normal or likely benign. Risk predictions from this AI were evaluated with a retrospective analysis of 9,183 breasts from a high-risk screening cohort, which were not used for training. Statistical analysis focused on the tradeoff between number of omitted exams versus negative predictive value, and number of potential early detections versus positive predictive value. The AI algorithm identified regions of concern that coincided with future tumors in 52% of screen-detected cancers. Upon directed review, a radiologist found that 71.3% of cancers had a visible correlate on the MRI prior to diagnosis, 65% of these correlates were identified by the AI model. Reevaluating these regions in 10% of all cases with higher AI-predicted risk could have resulted in up to 33% early detections by a radiologist. Additionally, screening burden could have been reduced in 16% of lower-risk cases by recommending a later follow-up without compromising current interval cancer rate. With increasing datasets and improving image quality we expect this new AI-aided, adaptive screening to meaningfully reduce screening burden and improve early detection.
Three-Dimensional Medical Image Fusion with Deformable Cross-Attention
Oct 10, 2023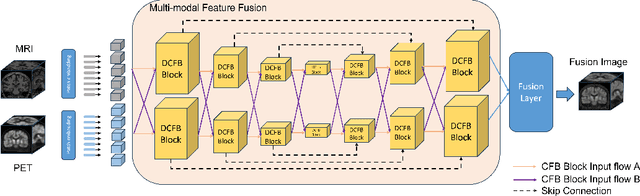
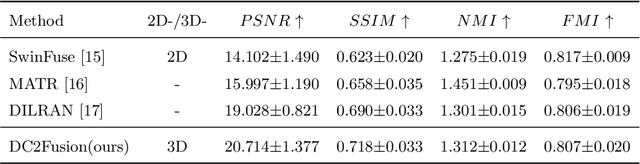
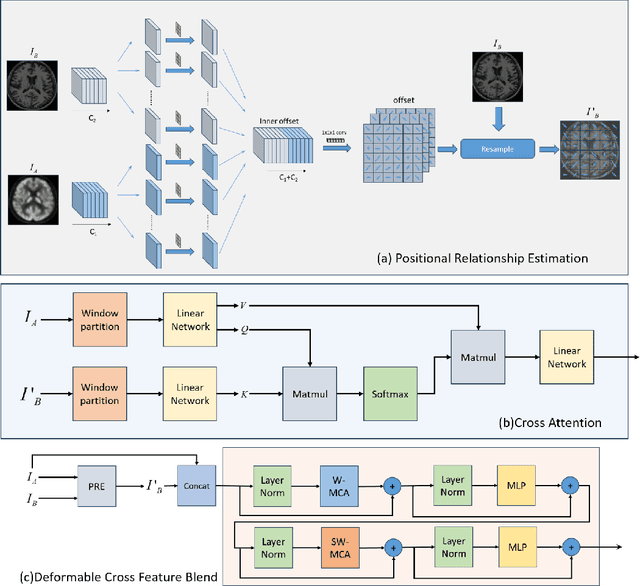
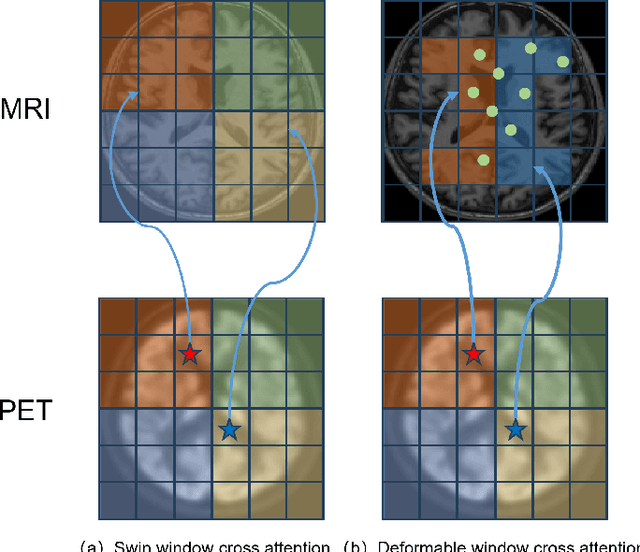
Multimodal medical image fusion plays an instrumental role in several areas of medical image processing, particularly in disease recognition and tumor detection. Traditional fusion methods tend to process each modality independently before combining the features and reconstructing the fusion image. However, this approach often neglects the fundamental commonalities and disparities between multimodal information. Furthermore, the prevailing methodologies are largely confined to fusing two-dimensional (2D) medical image slices, leading to a lack of contextual supervision in the fusion images and subsequently, a decreased information yield for physicians relative to three-dimensional (3D) images. In this study, we introduce an innovative unsupervised feature mutual learning fusion network designed to rectify these limitations. Our approach incorporates a Deformable Cross Feature Blend (DCFB) module that facilitates the dual modalities in discerning their respective similarities and differences. We have applied our model to the fusion of 3D MRI and PET images obtained from 660 patients in the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through the application of the DCFB module, our network generates high-quality MRI-PET fusion images. Experimental results demonstrate that our method surpasses traditional 2D image fusion methods in performance metrics such as Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM). Importantly, the capacity of our method to fuse 3D images enhances the information available to physicians and researchers, thus marking a significant step forward in the field. The code will soon be available online.