 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating Human-Centric Visual Cues for Human-Object Interaction Detection via Large Vision-Language Models
Nov 26, 2023
Human-object interaction (HOI) detection aims at detecting human-object pairs and predicting their interactions. However, the complexity of human behavior and the diverse contexts in which these interactions occur make it challenging. Intuitively, human-centric visual cues, such as the involved participants, the body language, and the surrounding environment, play crucial roles in shaping these interactions. These cues are particularly vital in interpreting unseen interactions. In this paper, we propose three prompts with VLM to generate human-centric visual cues within an image from multiple perspectives of humans. To capitalize on these rich Human-Centric Visual Cues, we propose a novel approach named HCVC for HOI detection. Particularly, we develop a transformer-based multimodal fusion module with multitower architecture to integrate visual cue features into the instance and interaction decoders. Our extensive experiments and analysis validate the efficacy of leveraging the generated human-centric visual cues for HOI detection. Notably, the experimental results indicate the superiority of the proposed model over the existing state-of-the-art methods on two widely used datasets.
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 26, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
Domain Aligned CLIP for Few-shot Classification
Nov 15, 2023Large vision-language representation learning models like CLIP have demonstrated impressive performance for zero-shot transfer to downstream tasks while largely benefiting from inter-modal (image-text) alignment via contrastive objectives. This downstream performance can further be enhanced by full-scale fine-tuning which is often compute intensive, requires large labelled data, and can reduce out-of-distribution (OOD) robustness. Furthermore, sole reliance on inter-modal alignment might overlook the rich information embedded within each individual modality. In this work, we introduce a sample-efficient domain adaptation strategy for CLIP, termed Domain Aligned CLIP (DAC), which improves both intra-modal (image-image) and inter-modal alignment on target distributions without fine-tuning the main model. For intra-modal alignment, we introduce a lightweight adapter that is specifically trained with an intra-modal contrastive objective. To improve inter-modal alignment, we introduce a simple framework to modulate the precomputed class text embeddings. The proposed few-shot fine-tuning framework is computationally efficient, robust to distribution shifts, and does not alter CLIP's parameters. We study the effectiveness of DAC by benchmarking on 11 widely used image classification tasks with consistent improvements in 16-shot classification upon strong baselines by about 2.3% and demonstrate competitive performance on 4 OOD robustness benchmarks.
Learning in Deep Factor Graphs with Gaussian Belief Propagation
Nov 24, 2023We propose an approach to do learning in Gaussian factor graphs. We treat all relevant quantities (inputs, outputs, parameters, latents) as random variables in a graphical model, and view both training and prediction as inference problems with different observed nodes. Our experiments show that these problems can be efficiently solved with belief propagation (BP), whose updates are inherently local, presenting exciting opportunities for distributed and asynchronous training. Our approach can be scaled to deep networks and provides a natural means to do continual learning: use the BP-estimated parameter marginals of the current task as parameter priors for the next. On a video denoising task we demonstrate the benefit of learnable parameters over a classical factor graph approach and we show encouraging performance of deep factor graphs for continual image classification on MNIST.
Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images
Nov 27, 2023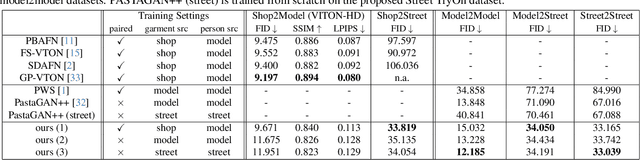
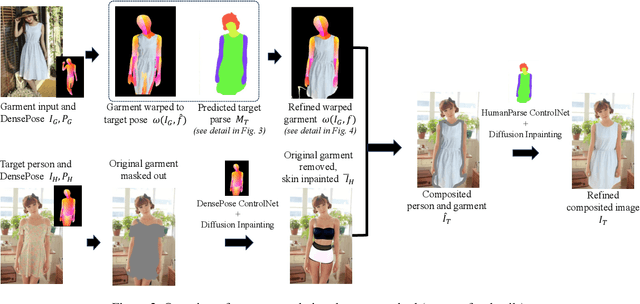
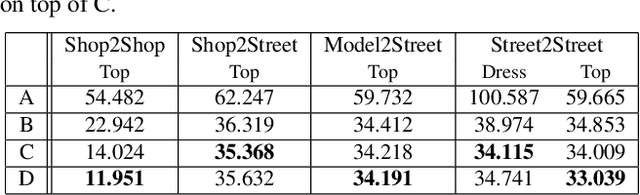
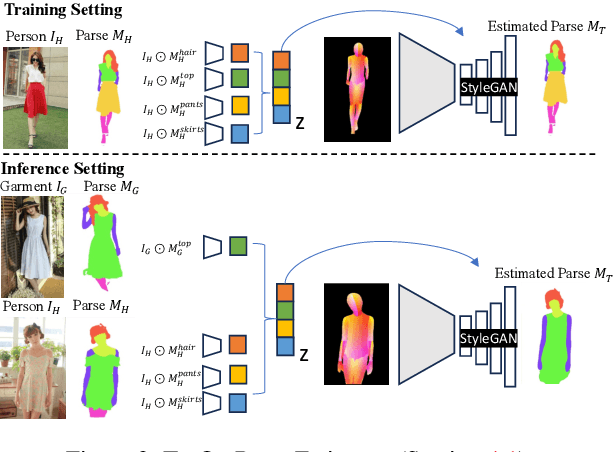
Virtual try-on has become a popular research topic, but most existing methods focus on studio images with a clean background. They can achieve plausible results for this studio try-on setting by learning to warp a garment image to fit a person's body from paired training data, i.e., garment images paired with images of people wearing the same garment. Such data is often collected from commercial websites, where each garment is demonstrated both by itself and on several models. By contrast, it is hard to collect paired data for in-the-wild scenes, and therefore, virtual try-on for casual images of people against cluttered backgrounds is rarely studied. In this work, we fill the gap in the current virtual try-on research by (1) introducing a Street TryOn benchmark to evaluate performance on street scenes and (2) proposing a novel method that can learn without paired data, from a set of in-the-wild person images directly. Our method can achieve robust performance across shop and street domains using a novel DensePose warping correction method combined with diffusion-based inpainting controlled by pose and semantic segmentation. Our experiments demonstrate competitive performance for standard studio try-on tasks and SOTA performance for street try-on and cross-domain try-on tasks.
Unleashing the Power of Prompt-driven Nucleus Instance Segmentation
Nov 27, 2023Nuclear instance segmentation in histology images is crucial for a broad spectrum of clinical applications. Current prevailing nuclear instance segmentation algorithms rely on regression of nuclei contours, distance maps, watershed markers or a proxy nuclear representation of star-convex polygons. Consequently, these methods necessitate sophisticated post-processing operations to distinguish nuclei instances, which are commonly acknowledged to be error-prone and parameter-sensitive. Recently, the segment anything model (SAM) has earned attracted huge attention within the domain of medical image segmentation due to its impressive generalization ability and promptable property. Nevertheless, its potential on nuclear instance segmentation remains largely underexplored. In this paper, we present a novel prompt-driven framework that consists of a point prompter and a SAM for automatic nuclei instance segmentation. Specifically, the prompter learns to generate a unique point prompt for each nucleus while the SAM is fine tuned to output the corresponding mask of the cued nucleus. Furthermore, we propose to add adjacent nuclei as negative prompts to promote the model's ability to recognize overlapping nuclei. Without bells and whistles, our proposed method sets a new state-of-the-art performance on three challenging benchmarks. Our code is available at \textcolor{magenta}{\url{https://github.com/windygoo/PromptNucSeg}} .
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Nov 27, 2023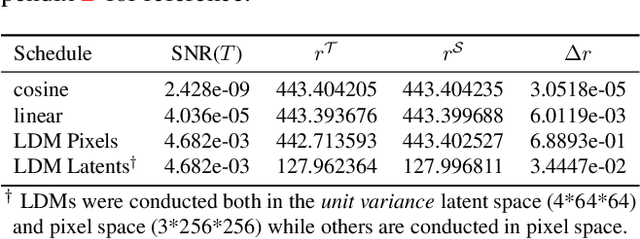
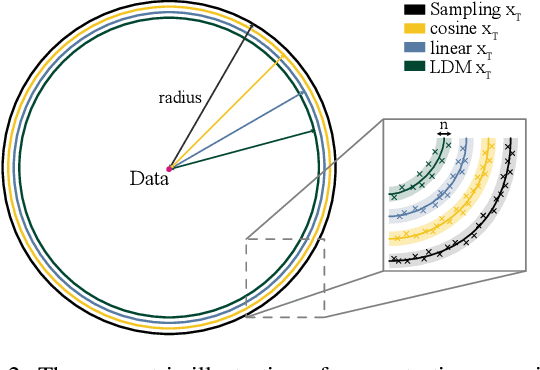
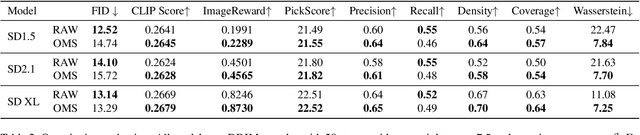
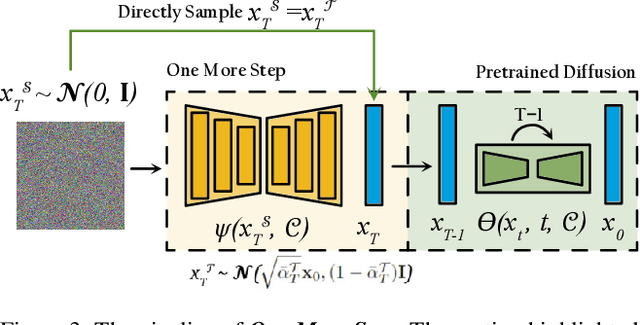
It is well known that many open-released foundational diffusion models have difficulty in generating images that substantially depart from average brightness, despite such images being present in the training data. This is due to an inconsistency: while denoising starts from pure Gaussian noise during inference, the training noise schedule retains residual data even in the final timestep distribution, due to difficulties in numerical conditioning in mainstream formulation, leading to unintended bias during inference. To mitigate this issue, certain $\epsilon$-prediction models are combined with an ad-hoc offset-noise methodology. In parallel, some contemporary models have adopted zero-terminal SNR noise schedules together with $\mathbf{v}$-prediction, which necessitate major alterations to pre-trained models. However, such changes risk destabilizing a large multitude of community-driven applications anchored on these pre-trained models. In light of this, our investigation revisits the fundamental causes, leading to our proposal of an innovative and principled remedy, called One More Step (OMS). By integrating a compact network and incorporating an additional simple yet effective step during inference, OMS elevates image fidelity and harmonizes the dichotomy between training and inference, while preserving original model parameters. Once trained, various pre-trained diffusion models with the same latent domain can share the same OMS module.
DAS: A Deformable Attention to Capture Salient Information in CNNs
Nov 20, 2023Convolutional Neural Networks (CNNs) excel in local spatial pattern recognition. For many vision tasks, such as object recognition and segmentation, salient information is also present outside CNN's kernel boundaries. However, CNNs struggle in capturing such relevant information due to their confined receptive fields. Self-attention can improve a model's access to global information but increases computational overhead. We present a fast and simple fully convolutional method called DAS that helps focus attention on relevant information. It uses deformable convolutions for the location of pertinent image regions and separable convolutions for efficiency. DAS plugs into existing CNNs and propagates relevant information using a gating mechanism. Compared to the O(n^2) computational complexity of transformer-style attention, DAS is O(n). Our claim is that DAS's ability to pay increased attention to relevant features results in performance improvements when added to popular CNNs for Image Classification and Object Detection. For example, DAS yields an improvement on Stanford Dogs (4.47%), ImageNet (1.91%), and COCO AP (3.3%) with base ResNet50 backbone. This outperforms other CNN attention mechanisms while using similar or less FLOPs. Our code will be publicly available.
AdvGen: Physical Adversarial Attack on Face Presentation Attack Detection Systems
Nov 20, 2023Evaluating the risk level of adversarial images is essential for safely deploying face authentication models in the real world. Popular approaches for physical-world attacks, such as print or replay attacks, suffer from some limitations, like including physical and geometrical artifacts. Recently, adversarial attacks have gained attraction, which try to digitally deceive the learning strategy of a recognition system using slight modifications to the captured image. While most previous research assumes that the adversarial image could be digitally fed into the authentication systems, this is not always the case for systems deployed in the real world. This paper demonstrates the vulnerability of face authentication systems to adversarial images in physical world scenarios. We propose AdvGen, an automated Generative Adversarial Network, to simulate print and replay attacks and generate adversarial images that can fool state-of-the-art PADs in a physical domain attack setting. Using this attack strategy, the attack success rate goes up to 82.01%. We test AdvGen extensively on four datasets and ten state-of-the-art PADs. We also demonstrate the effectiveness of our attack by conducting experiments in a realistic, physical environment.
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Nov 28, 2023

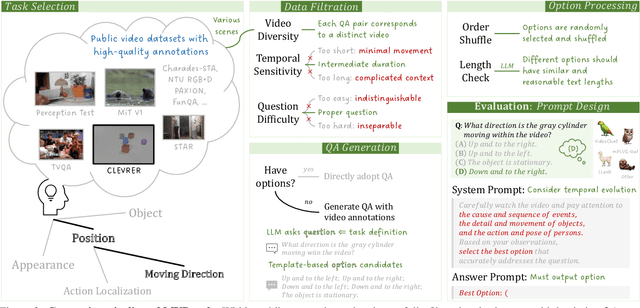

With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.