 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Unfolding Network for Image Compressed Sensing by Content-adaptive Gradient Updating and Deformation-invariant Non-local Modeling
Oct 16, 2023
Inspired by certain optimization solvers, the deep unfolding network (DUN) has attracted much attention in recent years for image compressed sensing (CS). However, there still exist the following two issues: 1) In existing DUNs, most hyperparameters are usually content independent, which greatly limits their adaptability for different input contents. 2) In each iteration, a plain convolutional neural network is usually adopted, which weakens the perception of wider context prior and therefore depresses the expressive ability. In this paper, inspired by the traditional Proximal Gradient Descent (PGD) algorithm, a novel DUN for image compressed sensing (dubbed DUN-CSNet) is proposed to solve the above two issues. Specifically, for the first issue, a novel content adaptive gradient descent network is proposed, in which a well-designed step size generation sub-network is developed to dynamically allocate the corresponding step sizes for different textures of input image by generating a content-aware step size map, realizing a content-adaptive gradient updating. For the second issue, considering the fact that many similar patches exist in an image but have undergone a deformation, a novel deformation-invariant non-local proximal mapping network is developed, which can adaptively build the long-range dependencies between the nonlocal patches by deformation-invariant non-local modeling, leading to a wider perception on context priors. Extensive experiments manifest that the proposed DUN-CSNet outperforms existing state-of-the-art CS methods by large margins.
Image Data Hiding in Neural Compressed Latent Representations
Oct 01, 2023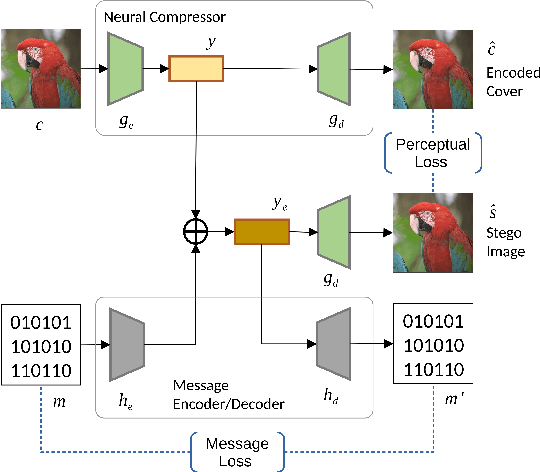
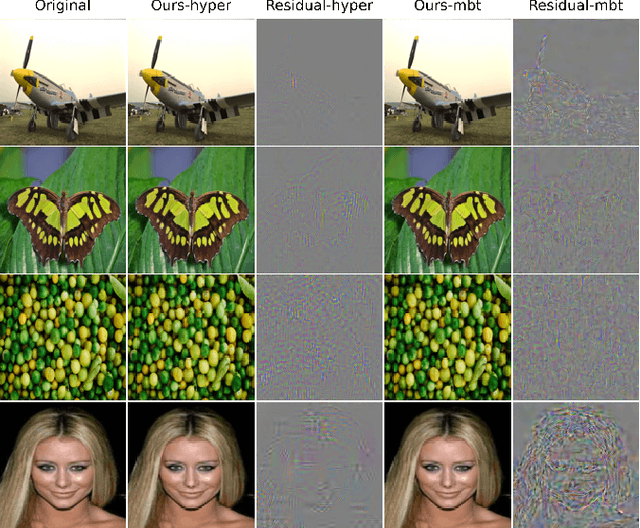

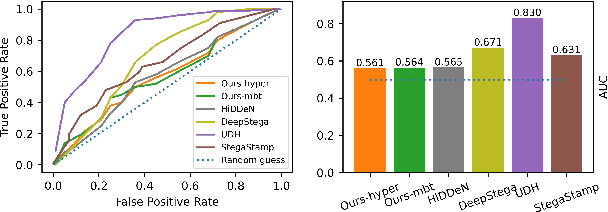
We propose an end-to-end learned image data hiding framework that embeds and extracts secrets in the latent representations of a generic neural compressor. By leveraging a perceptual loss function in conjunction with our proposed message encoder and decoder, our approach simultaneously achieves high image quality and high bit accuracy. Compared to existing techniques, our framework offers superior image secrecy and competitive watermarking robustness in the compressed domain while accelerating the embedding speed by over 50 times. These results demonstrate the potential of combining data hiding techniques and neural compression and offer new insights into developing neural compression techniques and their applications.
A Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology
Nov 20, 2023Deep learning is revolutionising pathology, offering novel opportunities in disease prognosis and personalised treatment. Historically, stain normalisation has been a crucial preprocessing step in computational pathology pipelines, and persists into the deep learning era. Yet, with the emergence of feature extractors trained using self-supervised learning (SSL) on diverse pathology datasets, we call this practice into question. In an empirical evaluation of publicly available feature extractors, we find that omitting stain normalisation and image augmentations does not compromise downstream performance, while incurring substantial savings in memory and compute. Further, we show that the top-performing feature extractors are remarkably robust to variations in stain and augmentations like rotation in their latent space. Contrary to previous patch-level benchmarking studies, our approach emphasises clinical relevance by focusing on slide-level prediction tasks in a weakly supervised setting with external validation cohorts. This work represents the most comprehensive robustness evaluation of public pathology SSL feature extractors to date, involving more than 6,000 training runs across nine tasks, five datasets, three downstream architectures, and various preprocessing setups. Our findings stand to streamline digital pathology workflows by minimising preprocessing needs and informing the selection of feature extractors.
OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning
Nov 20, 2023Towards holistic understanding of 3D scenes, a general 3D segmentation method is needed that can segment diverse objects without restrictions on object quantity or categories, while also reflecting the inherent hierarchical structure. To achieve this, we propose OmniSeg3D, an omniversal segmentation method aims for segmenting anything in 3D all at once. The key insight is to lift multi-view inconsistent 2D segmentations into a consistent 3D feature field through a hierarchical contrastive learning framework, which is accomplished by two steps. Firstly, we design a novel hierarchical representation based on category-agnostic 2D segmentations to model the multi-level relationship among pixels. Secondly, image features rendered from the 3D feature field are clustered at different levels, which can be further drawn closer or pushed apart according to the hierarchical relationship between different levels. In tackling the challenges posed by inconsistent 2D segmentations, this framework yields a global consistent 3D feature field, which further enables hierarchical segmentation, multi-object selection, and global discretization. Extensive experiments demonstrate the effectiveness of our method on high-quality 3D segmentation and accurate hierarchical structure understanding. A graphical user interface further facilitates flexible interaction for omniversal 3D segmentation.
Unearthing Common Inconsistency for Generalisable Deepfake Detection
Nov 20, 2023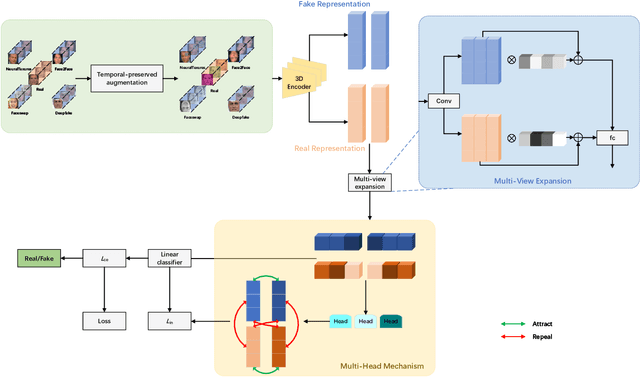
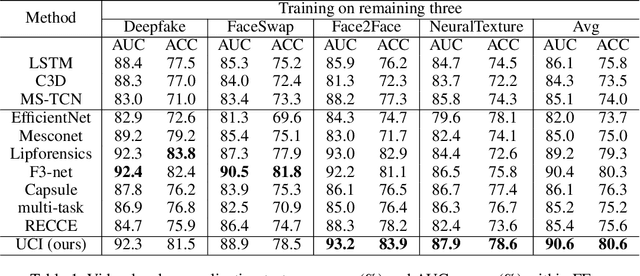
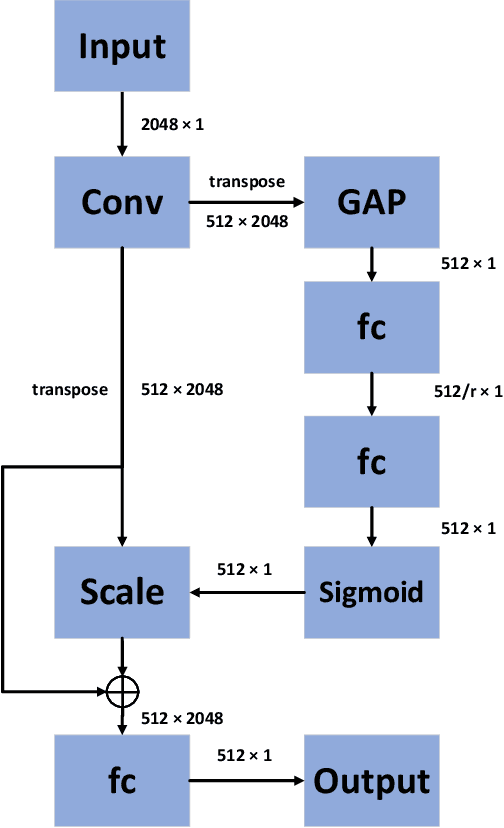
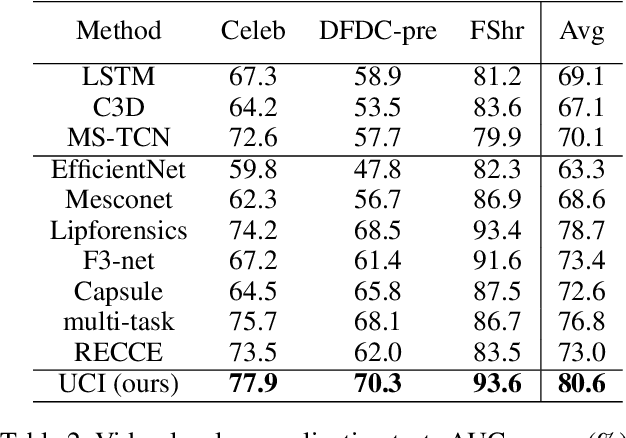
Deepfake has emerged for several years, yet efficient detection techniques could generalize over different manipulation methods require further research. While current image-level detection method fails to generalize to unseen domains, owing to the domain-shift phenomenon brought by CNN's strong inductive bias towards Deepfake texture, video-level one shows its potential to have both generalization across multiple domains and robustness to compression. We argue that although distinct face manipulation tools have different inherent bias, they all disrupt the consistency between frames, which is a natural characteristic shared by authentic videos. Inspired by this, we proposed a detection approach by capturing frame inconsistency that broadly exists in different forgery techniques, termed unearthing-common-inconsistency (UCI). Concretely, the UCI network based on self-supervised contrastive learning can better distinguish temporal consistency between real and fake videos from multiple domains. We introduced a temporally-preserved module method to introduce spatial noise perturbations, directing the model's attention towards temporal information. Subsequently, leveraging a multi-view cross-correlation learning module, we extensively learn the disparities in temporal representations between genuine and fake samples. Extensive experiments demonstrate the generalization ability of our method on unseen Deepfake domains.
FNOSeg3D: Resolution-Robust 3D Image Segmentation with Fourier Neural Operator
Oct 05, 2023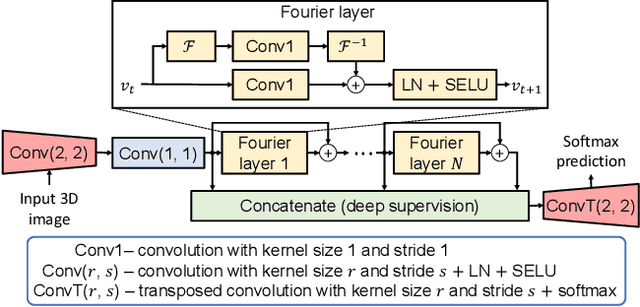
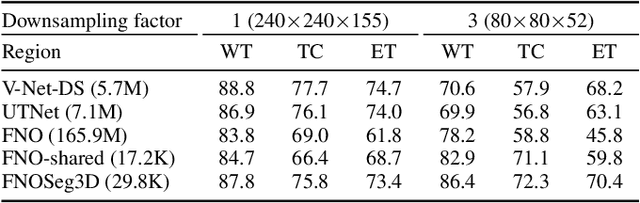
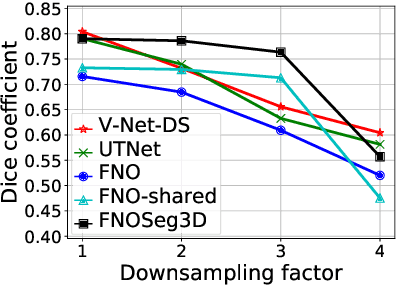

Due to the computational complexity of 3D medical image segmentation, training with downsampled images is a common remedy for out-of-memory errors in deep learning. Nevertheless, as standard spatial convolution is sensitive to variations in image resolution, the accuracy of a convolutional neural network trained with downsampled images can be suboptimal when applied on the original resolution. To address this limitation, we introduce FNOSeg3D, a 3D segmentation model robust to training image resolution based on the Fourier neural operator (FNO). The FNO is a deep learning framework for learning mappings between functions in partial differential equations, which has the appealing properties of zero-shot super-resolution and global receptive field. We improve the FNO by reducing its parameter requirement and enhancing its learning capability through residual connections and deep supervision, and these result in our FNOSeg3D model which is parameter efficient and resolution robust. When tested on the BraTS'19 dataset, it achieved superior robustness to training image resolution than other tested models with less than 1% of their model parameters.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.
ITRE: Low-light Image Enhancement Based on Illumination Transmission Ratio Estimation
Oct 08, 2023



Noise, artifacts, and over-exposure are significant challenges in the field of low-light image enhancement. Existing methods often struggle to address these issues simultaneously. In this paper, we propose a novel Retinex-based method, called ITRE, which suppresses noise and artifacts from the origin of the model, prevents over-exposure throughout the enhancement process. Specifically, we assume that there must exist a pixel which is least disturbed by low light within pixels of same color. First, clustering the pixels on the RGB color space to find the Illumination Transmission Ratio (ITR) matrix of the whole image, which determines that noise is not over-amplified easily. Next, we consider ITR of the image as the initial illumination transmission map to construct a base model for refined transmission map, which prevents artifacts. Additionally, we design an over-exposure module that captures the fundamental characteristics of pixel over-exposure and seamlessly integrate it into the base model. Finally, there is a possibility of weak enhancement when inter-class distance of pixels with same color is too small. To counteract this, we design a Robust-Guard module that safeguards the robustness of the image enhancement process. Extensive experiments demonstrate the effectiveness of our approach in suppressing noise, preventing artifacts, and controlling over-exposure level simultaneously. Our method performs superiority in qualitative and quantitative performance evaluations by comparing with state-of-the-art methods.
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 09, 2023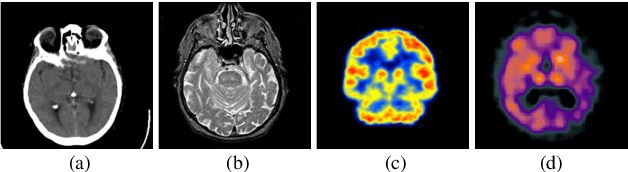
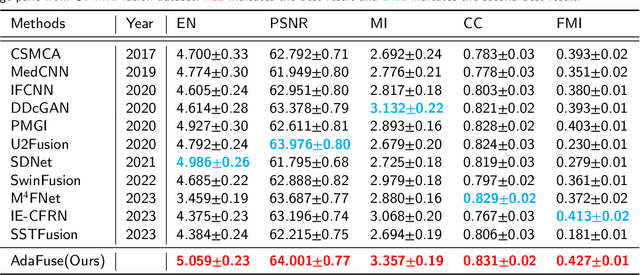
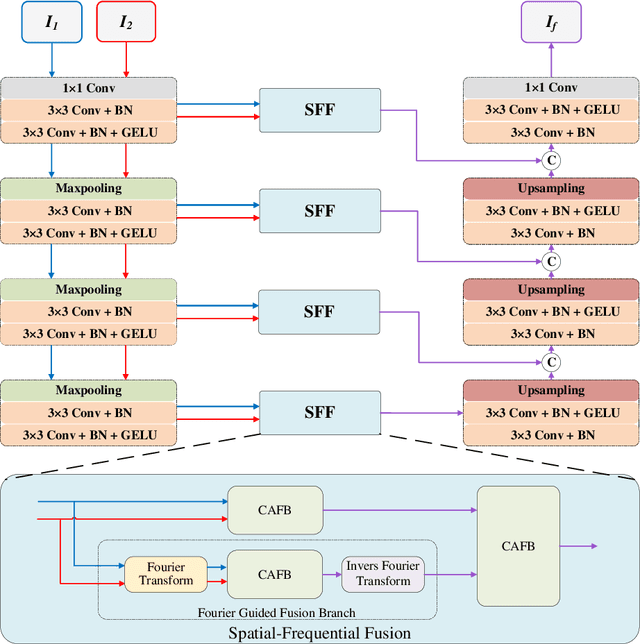
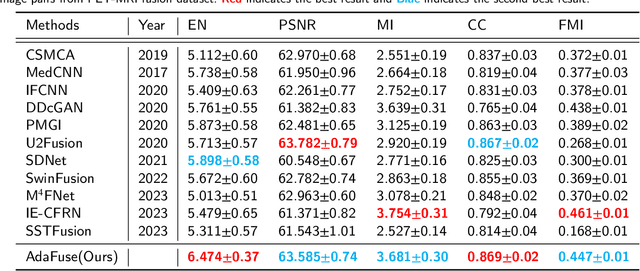
Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy. Our code is publicly available at https://github.com/xianming-gu/AdaFuse.
ChessVision -- A Dataset for Logically Coherent Multi-label Classification
Nov 21, 2023Starting with early successes in computer vision tasks, deep learning based techniques have since overtaken state of the art approaches in a multitude of domains. However, it has been demonstrated time and again that these techniques fail to capture semantic context and logical constraints, instead often relying on spurious correlations to arrive at the answer. Since application of deep learning techniques to critical scenarios are dependent on adherence to domain specific constraints, several attempts have been made to address this issue. One limitation holding back a thorough exploration of this area, is a lack of suitable datasets which feature a rich set of rules. In order to address this, we present the ChessVision Dataset, consisting of 200,000+ images of annotated chess games in progress, requiring recreation of the game state from its corresponding image. This is accompanied by a curated set of rules which constrains the set of predictions to "reasonable" game states, and are designed to probe key semantic abilities like localization and enumeration. Alongside standard metrics, additional metrics to measure performance with regards to logical consistency is presented. We analyze several popular and state of the art vision models on this task, and show that, although their performance on standard metrics are laudable, they produce a plethora of incoherent results, indicating that this dataset presents a significant challenge for future works.