 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based generation of Histopathological Whole Slide Images at a Gigapixel scale
Nov 14, 2023
We present a novel diffusion-based approach to generate synthetic histopathological Whole Slide Images (WSIs) at an unprecedented gigapixel scale. Synthetic WSIs have many potential applications: They can augment training datasets to enhance the performance of many computational pathology applications. They allow the creation of synthesized copies of datasets that can be shared without violating privacy regulations. Or they can facilitate learning representations of WSIs without requiring data annotations. Despite this variety of applications, no existing deep-learning-based method generates WSIs at their typically high resolutions. Mainly due to the high computational complexity. Therefore, we propose a novel coarse-to-fine sampling scheme to tackle image generation of high-resolution WSIs. In this scheme, we increase the resolution of an initial low-resolution image to a high-resolution WSI. Particularly, a diffusion model sequentially adds fine details to images and increases their resolution. In our experiments, we train our method with WSIs from the TCGA-BRCA dataset. Additionally to quantitative evaluations, we also performed a user study with pathologists. The study results suggest that our generated WSIs resemble the structure of real WSIs.
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
Nov 14, 2023Large multimodal models (LMMs) suffer from multimodal hallucination, where they provide incorrect responses misaligned with the given visual information. Recent works have conjectured that one of the reasons behind multimodal hallucination might be due to the vision encoder failing to ground on the image properly. To mitigate this issue, we propose a novel approach that leverages self-feedback as visual cues. Building on this approach, we introduce Volcano, a multimodal self-feedback guided revision model. Volcano generates natural language feedback to its initial response based on the provided visual information and utilizes this feedback to self-revise its initial response. Volcano effectively reduces multimodal hallucination and achieves state-of-the-art on MMHal-Bench, POPE, and GAVIE. It also improves on general multimodal abilities and outperforms previous models on MM-Vet and MMBench. Through a qualitative analysis, we show that Volcano's feedback is properly grounded on the image than the initial response. This indicates that Volcano can provide itself with richer visual information, helping alleviate multimodal hallucination. We publicly release Volcano models of 7B and 13B sizes along with the data and code at https://github.com/kaistAI/Volcano.
EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images
Nov 10, 2023Medical image segmentation has immense clinical applicability but remains a challenge despite advancements in deep learning. The Segment Anything Model (SAM) exhibits potential in this field, yet the requirement for expertise intervention and the domain gap between natural and medical images poses significant obstacles. This paper introduces a novel training-free evidential prompt generation method named EviPrompt to overcome these issues. The proposed method, built on the inherent similarities within medical images, requires only a single reference image-annotation pair, making it a training-free solution that significantly reduces the need for extensive labeling and computational resources. First, to automatically generate prompts for SAM in medical images, we introduce an evidential method based on uncertainty estimation without the interaction of clinical experts. Then, we incorporate the human prior into the prompts, which is vital for alleviating the domain gap between natural and medical images and enhancing the applicability and usefulness of SAM in medical scenarios. EviPrompt represents an efficient and robust approach to medical image segmentation, with evaluations across a broad range of tasks and modalities confirming its efficacy.
Mitigating stereotypical biases in text to image generative systems
Oct 10, 2023
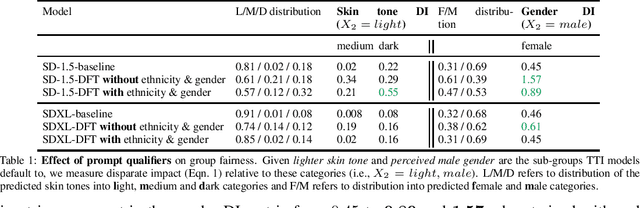
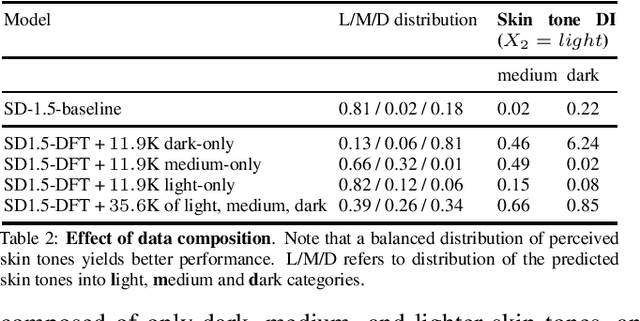

State-of-the-art generative text-to-image models are known to exhibit social biases and over-represent certain groups like people of perceived lighter skin tones and men in their outcomes. In this work, we propose a method to mitigate such biases and ensure that the outcomes are fair across different groups of people. We do this by finetuning text-to-image models on synthetic data that varies in perceived skin tones and genders constructed from diverse text prompts. These text prompts are constructed from multiplicative combinations of ethnicities, genders, professions, age groups, and so on, resulting in diverse synthetic data. Our diversity finetuned (DFT) model improves the group fairness metric by 150% for perceived skin tone and 97.7% for perceived gender. Compared to baselines, DFT models generate more people with perceived darker skin tone and more women. To foster open research, we will release all text prompts and code to generate training images.
Appearance Codes using Joint Embedding Learning of Multiple Modalities
Nov 19, 2023The use of appearance codes in recent work on generative modeling has enabled novel view renders with variable appearance and illumination, such as day-time and night-time renders of a scene. A major limitation of this technique is the need to re-train new appearance codes for every scene on inference, so in this work we address this problem proposing a framework that learns a joint embedding space for the appearance and structure of the scene by enforcing a contrastive loss constraint between different modalities. We apply our framework to a simple Variational Auto-Encoder model on the RADIATE dataset \cite{sheeny2021radiate} and qualitatively demonstrate that we can generate new renders of night-time photos using day-time appearance codes without additional optimization iterations. Additionally, we compare our model to a baseline VAE that uses the standard per-image appearance code technique and show that our approach achieves generations of similar quality without learning appearance codes for any unseen images on inference.
MLOps for Scarce Image Data: A Use Case in Microscopic Image Analysis
Sep 27, 2023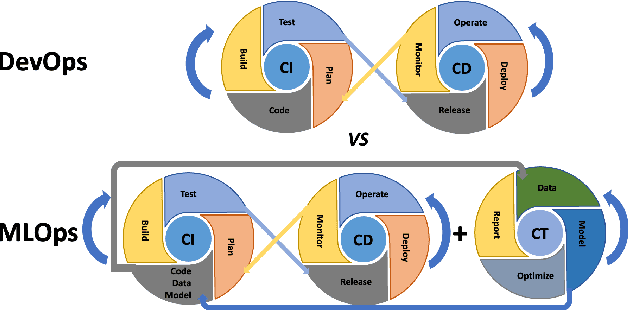
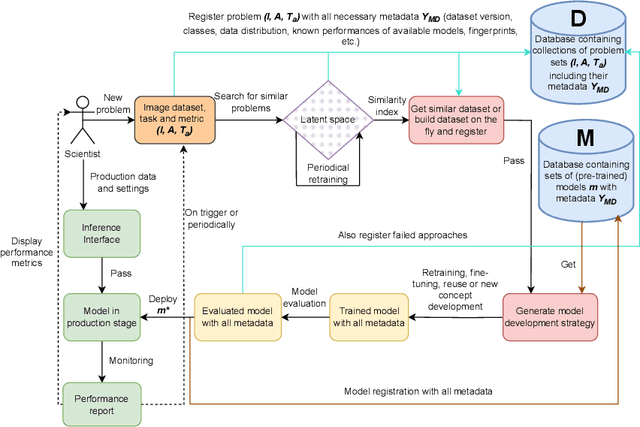
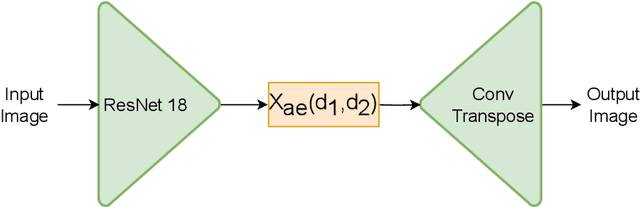
Nowadays, Machine Learning (ML) is experiencing tremendous popularity that has never been seen before. The operationalization of ML models is governed by a set of concepts and methods referred to as Machine Learning Operations (MLOps). Nevertheless, researchers, as well as professionals, often focus more on the automation aspect and neglect the continuous deployment and monitoring aspects of MLOps. As a result, there is a lack of continuous learning through the flow of feedback from production to development, causing unexpected model deterioration over time due to concept drifts, particularly when dealing with scarce data. This work explores the complete application of MLOps in the context of scarce data analysis. The paper proposes a new holistic approach to enhance biomedical image analysis. Our method includes: a fingerprinting process that enables selecting the best models, datasets, and model development strategy relative to the image analysis task at hand; an automated model development stage; and a continuous deployment and monitoring process to ensure continuous learning. For preliminary results, we perform a proof of concept for fingerprinting in microscopic image datasets.
CrIBo: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping
Oct 11, 2023Leveraging nearest neighbor retrieval for self-supervised representation learning has proven beneficial with object-centric images. However, this approach faces limitations when applied to scene-centric datasets, where multiple objects within an image are only implicitly captured in the global representation. Such global bootstrapping can lead to undesirable entanglement of object representations. Furthermore, even object-centric datasets stand to benefit from a finer-grained bootstrapping approach. In response to these challenges, we introduce a novel Cross-Image Object-Level Bootstrapping method tailored to enhance dense visual representation learning. By employing object-level nearest neighbor bootstrapping throughout the training, CrIBo emerges as a notably strong and adequate candidate for in-context learning, leveraging nearest neighbor retrieval at test time. CrIBo shows state-of-the-art performance on the latter task while being highly competitive in more standard downstream segmentation tasks. Our code and pretrained models will be publicly available upon acceptance.
Cross-view and Cross-pose Completion for 3D Human Understanding
Nov 15, 2023Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
HFORD: High-Fidelity and Occlusion-Robust De-identification for Face Privacy Protection
Nov 15, 2023With the popularity of smart devices and the development of computer vision technology, concerns about face privacy protection are growing. The face de-identification technique is a practical way to solve the identity protection problem. The existing facial de-identification methods have revealed several problems, including the impact on the realism of anonymized results when faced with occlusions and the inability to maintain identity-irrelevant details in anonymized results. We present a High-Fidelity and Occlusion-Robust De-identification (HFORD) method to deal with these issues. This approach can disentangle identities and attributes while preserving image-specific details such as background, facial features (e.g., wrinkles), and lighting, even in occluded scenes. To disentangle the latent codes in the GAN inversion space, we introduce an Identity Disentanglement Module (IDM). This module selects the latent codes that are closely related to the identity. It further separates the latent codes into identity-related codes and attribute-related codes, enabling the network to preserve attributes while only modifying the identity. To ensure the preservation of image details and enhance the network's robustness to occlusions, we propose an Attribute Retention Module (ARM). This module adaptively preserves identity-irrelevant details and facial occlusions and blends them into the generated results in a modulated manner. Extensive experiments show that our method has higher quality, better detail fidelity, and stronger occlusion robustness than other face de-identification methods.
Investigating the Use of Traveltime and Reflection Tomography for Deep Learning-Based Sound-Speed Estimation in Ultrasound Computed Tomography
Nov 16, 2023Ultrasound computed tomography (USCT) is actively being developed to quantify acoustic tissue properties such as the speed-of-sound (SOS). Although full-waveform inversion (FWI) is an effective method for accurate SOS reconstruction, it can be computationally challenging for large-scale problems. Deep learning-based image-to-image learned reconstruction (IILR) methods are being investigated as scalable and computationally efficient alternatives. This study investigates the impact of the chosen input modalities on IILR methods for high-resolution SOS reconstruction in USCT. The selected modalities are traveltime tomography (TT) and reflection tomography (RT), which produce a low-resolution SOS map and a reflectivity map, respectively. These modalities have been chosen for their lower computational cost relative to FWI and their capacity to provide complementary information: TT offers a direct -- while low resolution -- SOS measure, while RT reveals tissue boundary information. Systematic analyses were facilitated by employing a stylized USCT imaging system with anatomically realistic numerical breast phantoms. Within this testbed, a supervised convolutional neural network (CNN) was trained to map dual-channel (TT and RT images) to a high-resolution SOS map. Moreover, the CNN was fine-tuned using a weighted reconstruction loss that prioritized tumor regions to address tumor underrepresentation in the training dataset. To understand the benefits of employing dual-channel inputs, single-input CNNs were trained separately using inputs from each modality alone (TT or RT). The methods were assessed quantitatively using normalized root mean squared error and structural similarity index measure for reconstruction accuracy and receiver operating characteristic analysis to assess signal detection-based performance measures.