 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DialMAT: Dialogue-Enabled Transformer with Moment-Based Adversarial Training
Nov 12, 2023
This paper focuses on the DialFRED task, which is the task of embodied instruction following in a setting where an agent can actively ask questions about the task. To address this task, we propose DialMAT. DialMAT introduces Moment-based Adversarial Training, which incorporates adversarial perturbations into the latent space of language, image, and action. Additionally, it introduces a crossmodal parallel feature extraction mechanism that applies foundation models to both language and image. We evaluated our model using a dataset constructed from the DialFRED dataset and demonstrated superior performance compared to the baseline method in terms of success rate and path weighted success rate. The model secured the top position in the DialFRED Challenge, which took place at the CVPR 2023 Embodied AI workshop.
DeltaSpace: A Semantic-aligned Feature Space for Flexible Text-guided Image Editing
Oct 12, 2023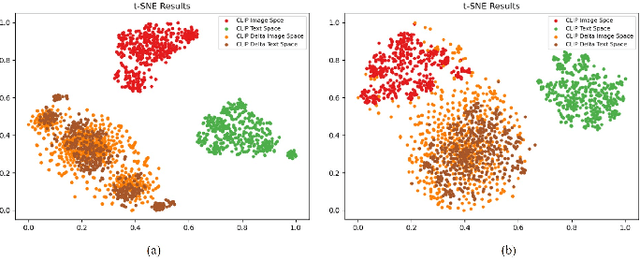
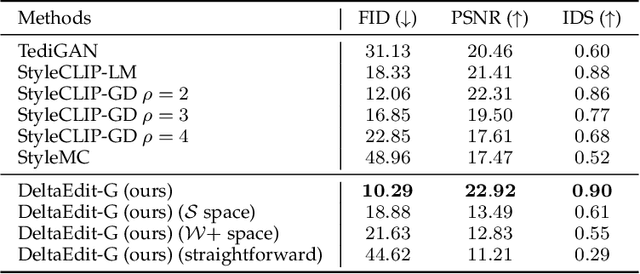


Text-guided image editing faces significant challenges to training and inference flexibility. Much literature collects large amounts of annotated image-text pairs to train text-conditioned generative models from scratch, which is expensive and not efficient. After that, some approaches that leverage pre-trained vision-language models are put forward to avoid data collection, but they are also limited by either per text-prompt optimization or inference-time hyper-parameters tuning. To address these issues, we investigate and identify a specific space, referred to as CLIP DeltaSpace, where the CLIP visual feature difference of two images is semantically aligned with the CLIP textual feature difference of their corresponding text descriptions. Based on DeltaSpace, we propose a novel framework called DeltaEdit, which maps the CLIP visual feature differences to the latent space directions of a generative model during the training phase, and predicts the latent space directions from the CLIP textual feature differences during the inference phase. And this design endows DeltaEdit with two advantages: (1) text-free training; (2) generalization to various text prompts for zero-shot inference. Extensive experiments validate the effectiveness and versatility of DeltaEdit with different generative models, including both the GAN model and the diffusion model, in achieving flexible text-guided image editing. Code is available at https://github.com/Yueming6568/DeltaEdit.
JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
Oct 10, 2023We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.
MNN: Mixed Nearest-Neighbors for Self-Supervised Learning
Nov 13, 2023In contrastive self-supervised learning, positive samples are typically drawn from the same image but in different augmented views, resulting in a relatively limited source of positive samples. An effective way to alleviate this problem is to incorporate the relationship between samples, which involves including the top-K nearest neighbors of positive samples. However, the problem of false neighbors (i.e., neighbors that do not belong to the same category as the positive sample) is an objective but often overlooked challenge due to the query of neighbor samples without supervision information. In this paper, we present a simple self-supervised learning framework called Mixed Nearest-Neighbors for Self-Supervised Learning (MNN). MNN optimizes the influence of neighbor samples on the semantics of positive samples through an intuitive weighting approach and image mixture operations. The results demonstrate that MNN exhibits exceptional generalization performance and training efficiency on four benchmark datasets.
Asking More Informative Questions for Grounded Retrieval
Nov 14, 2023When a model is trying to gather information in an interactive setting, it benefits from asking informative questions. However, in the case of a grounded multi-turn image identification task, previous studies have been constrained to polar yes/no questions, limiting how much information the model can gain in a single turn. We present an approach that formulates more informative, open-ended questions. In doing so, we discover that off-the-shelf visual question answering (VQA) models often make presupposition errors, which standard information gain question selection methods fail to account for. To address this issue, we propose a method that can incorporate presupposition handling into both question selection and belief updates. Specifically, we use a two-stage process, where the model first filters out images which are irrelevant to a given question, then updates its beliefs about which image the user intends. Through self-play and human evaluations, we show that our method is successful in asking informative open-ended questions, increasing accuracy over the past state-of-the-art by 14%, while resulting in 48% more efficient games in human evaluations.
Image Data Hiding in Neural Compressed Latent Representations
Oct 01, 2023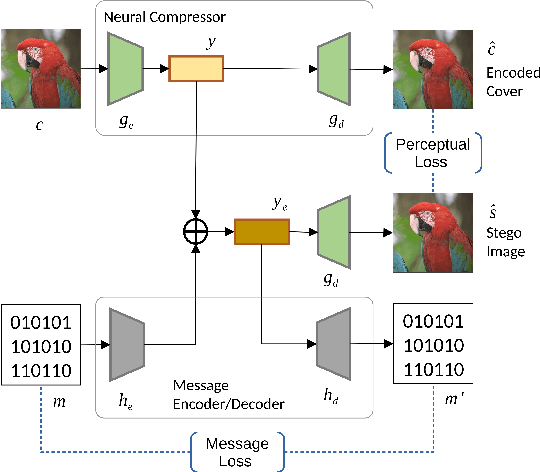
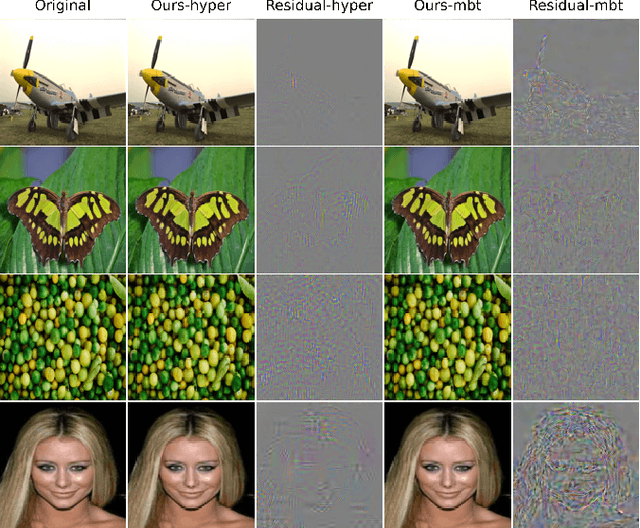

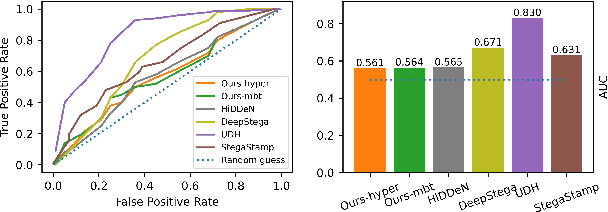
We propose an end-to-end learned image data hiding framework that embeds and extracts secrets in the latent representations of a generic neural compressor. By leveraging a perceptual loss function in conjunction with our proposed message encoder and decoder, our approach simultaneously achieves high image quality and high bit accuracy. Compared to existing techniques, our framework offers superior image secrecy and competitive watermarking robustness in the compressed domain while accelerating the embedding speed by over 50 times. These results demonstrate the potential of combining data hiding techniques and neural compression and offer new insights into developing neural compression techniques and their applications.
Damping Density of an Absorptive Shoebox Room Derived from the Image-Source Method
Oct 11, 2023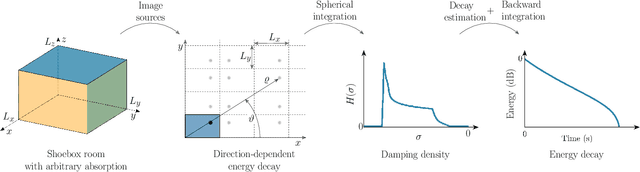
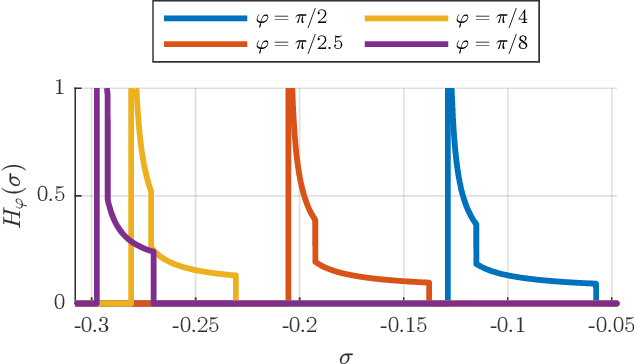
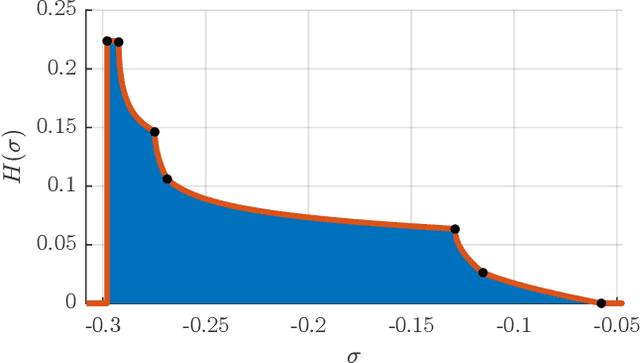
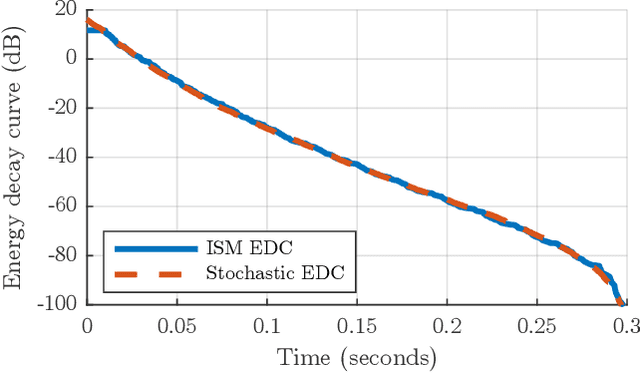
The image-source method is widely applied to compute room impulse responses (RIRs) of shoebox rooms with arbitrary absorption. However, with increasing RIR lengths, the number of image sources grows rapidly, leading to slow computation. In this paper, we derive a closed-form expression for the damping density, which characterizes the overall multi-slope energy decay. The omnidirectional energy decay over time is directly derived from the damping density. The resulting energy decay model accurately matches the late reverberation simulated via the image-source method. The proposed model allows the fast stochastic synthesis of late reverberation by shaping noise with the energy envelope. Simulations of various wall damping coefficients demonstrate the model's accuracy. The proposed model consistently outperforms the energy decay prediction accuracy compared to a state-of-the-art approximation method. The paper elaborates on the proposed damping density's applicability to modeling multi-sloped sound energy decay, predicting reverberation time in non-diffuse sound fields, and fast frequency-dependent RIR synthesis.
CD-COCO: A Versatile Complex Distorted COCO Database for Scene-Context-Aware Computer Vision
Nov 12, 2023

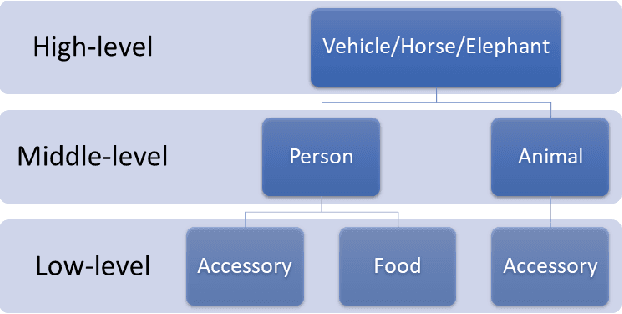
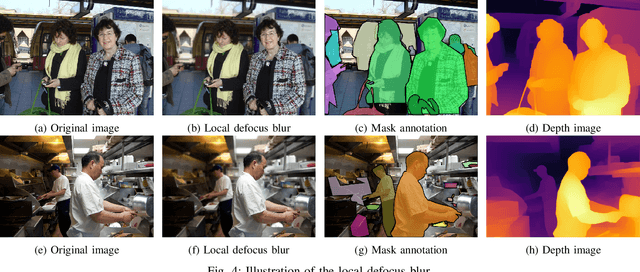
The recent development of deep learning methods applied to vision has enabled their increasing integration into real-world applications to perform complex Computer Vision (CV) tasks. However, image acquisition conditions have a major impact on the performance of high-level image processing. A possible solution to overcome these limitations is to artificially augment the training databases or to design deep learning models that are robust to signal distortions. We opt here for the first solution by enriching the database with complex and realistic distortions which were ignored until now in the existing databases. To this end, we built a new versatile database derived from the well-known MS-COCO database to which we applied local and global photo-realistic distortions. These new local distortions are generated by considering the scene context of the images that guarantees a high level of photo-realism. Distortions are generated by exploiting the depth information of the objects in the scene as well as their semantics. This guarantees a high level of photo-realism and allows to explore real scenarios ignored in conventional databases dedicated to various CV applications. Our versatile database offers an efficient solution to improve the robustness of various CV tasks such as Object Detection (OD), scene segmentation, and distortion-type classification methods. The image database, scene classification index, and distortion generation codes are publicly available \footnote{\url{https://github.com/Aymanbegh/CD-COCO}}
Using Diffusion Models to Generate Synthetic Labelled Data for Medical Image Segmentation
Oct 25, 2023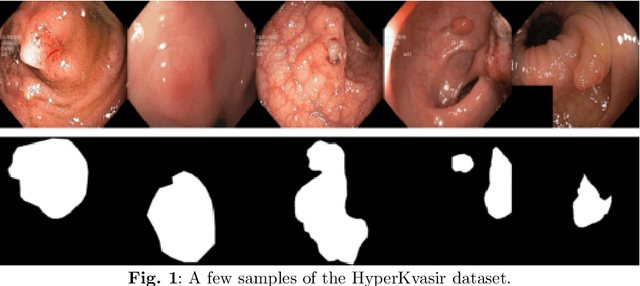
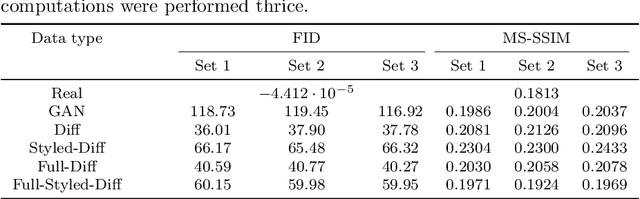
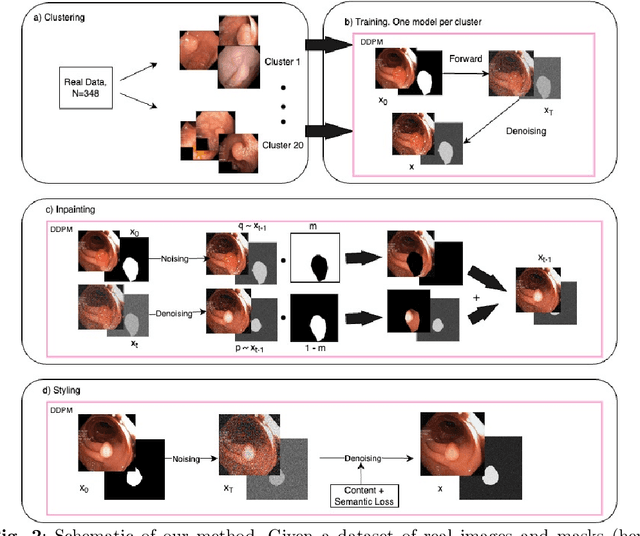
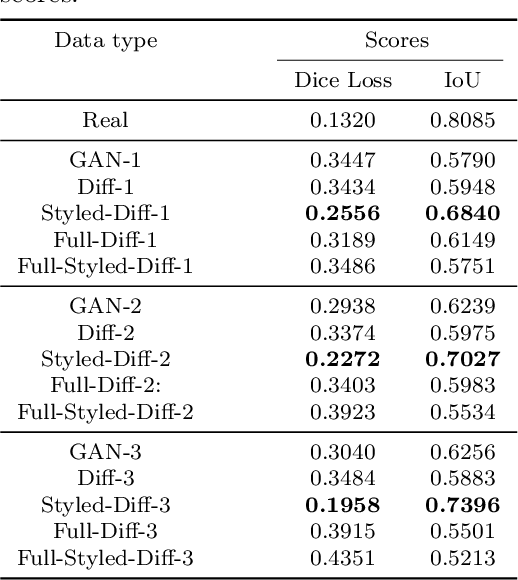
In this paper, we proposed and evaluated a pipeline for generating synthetic labeled polyp images with the aim of augmenting automatic medical image segmentation models. In doing so, we explored the use of diffusion models to generate and style synthetic labeled data. The HyperKvasir dataset consisting of 1000 images of polyps in the human GI tract obtained from 2008 to 2016 during clinical endoscopies was used for training and testing. Furthermore, we did a qualitative expert review, and computed the Fr\'echet Inception Distance (FID) and Multi-Scale Structural Similarity (MS-SSIM) between the output images and the source images to evaluate our samples. To evaluate its augmentation potential, a segmentation model was trained with the synthetic data to compare their performance with the real data and previous Generative Adversarial Networks (GAN) methods. These models were evaluated using the Dice loss (DL) and Intersection over Union (IoU) score. Our pipeline generated images that more closely resembled real images according to the FID scores (GAN: $118.37 \pm 1.06 \text{ vs SD: } 65.99 \pm 0.37$). Improvements over GAN methods were seen on average when the segmenter was entirely trained (DL difference: $-0.0880 \pm 0.0170$, IoU difference: $0.0993 \pm 0.01493$) or augmented (DL difference: GAN $-0.1140 \pm 0.0900 \text{ vs SD }-0.1053 \pm 0.0981$, IoU difference: GAN $0.01533 \pm 0.03831 \text{ vs SD }0.0255 \pm 0.0454$) with synthetic data. Overall, we obtained more realistic synthetic images and improved segmentation model performance when fully or partially trained on synthetic data.
LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts
Oct 16, 2023Diffusion-based generative models have significantly advanced text-to-image generation but encounter challenges when processing lengthy and intricate text prompts describing complex scenes with multiple objects. While excelling in generating images from short, single-object descriptions, these models often struggle to faithfully capture all the nuanced details within longer and more elaborate textual inputs. In response, we present a novel approach leveraging Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. These components form the foundation of our layout-to-image generation model, which operates in two phases. The initial Global Scene Generation utilizes object layouts and background context to create an initial scene but often falls short in faithfully representing object characteristics as specified in the prompts. To address this limitation, we introduce an Iterative Refinement Scheme that iteratively evaluates and refines box-level content to align them with their textual descriptions, recomposing objects as needed to ensure consistency. Our evaluation on complex prompts featuring multiple objects demonstrates a substantial improvement in recall compared to baseline diffusion models. This is further validated by a user study, underscoring the efficacy of our approach in generating coherent and detailed scenes from intricate textual inputs.