 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Nov 24, 2023
In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
SkeletonGait: Gait Recognition Using Skeleton Maps
Nov 22, 2023The choice of the representations is essential for deep gait recognition methods. The binary silhouettes and skeletal coordinates are two dominant representations in recent literature, achieving remarkable advances in many scenarios. However, inherent challenges remain, in which silhouettes are not always guaranteed in unconstrained scenes, and structural cues have not been fully utilized from skeletons. In this paper, we introduce a novel skeletal gait representation named Skeleton Map, together with SkeletonGait, a skeleton-based method to exploit structural information from human skeleton maps. Specifically, the skeleton map represents the coordinates of human joints as a heatmap with Gaussian approximation, exhibiting a silhouette-like image devoid of exact body structure. Beyond achieving state-of-the-art performances over five popular gait datasets, more importantly, SkeletonGait uncovers novel insights about how important structural features are in describing gait and when do they play a role. Furthermore, we propose a multi-branch architecture, named SkeletonGait++, to make use of complementary features from both skeletons and silhouettes. Experiments indicate that SkeletonGait++ outperforms existing state-of-the-art methods by a significant margin in various scenarios. For instance, it achieves an impressive rank-1 accuracy of over $85\%$ on the challenging GREW dataset. All the source code will be available at https://github.com/ShiqiYu/OpenGait.
CrIBo: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping
Oct 11, 2023Leveraging nearest neighbor retrieval for self-supervised representation learning has proven beneficial with object-centric images. However, this approach faces limitations when applied to scene-centric datasets, where multiple objects within an image are only implicitly captured in the global representation. Such global bootstrapping can lead to undesirable entanglement of object representations. Furthermore, even object-centric datasets stand to benefit from a finer-grained bootstrapping approach. In response to these challenges, we introduce a novel Cross-Image Object-Level Bootstrapping method tailored to enhance dense visual representation learning. By employing object-level nearest neighbor bootstrapping throughout the training, CrIBo emerges as a notably strong and adequate candidate for in-context learning, leveraging nearest neighbor retrieval at test time. CrIBo shows state-of-the-art performance on the latter task while being highly competitive in more standard downstream segmentation tasks. Our code and pretrained models will be publicly available upon acceptance.
Low Latency Instance Segmentation by Continuous Clustering for Rotating LiDAR Sensors
Nov 23, 2023
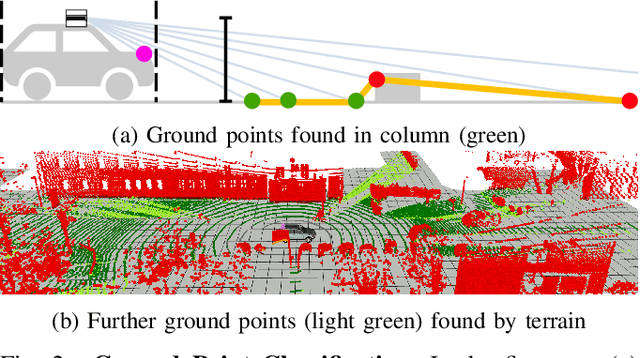
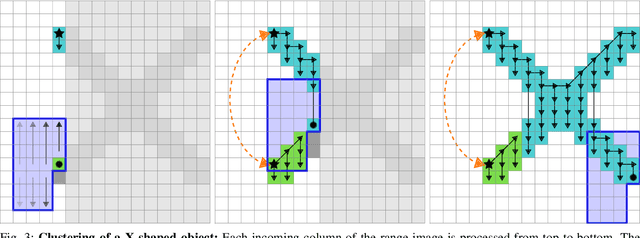
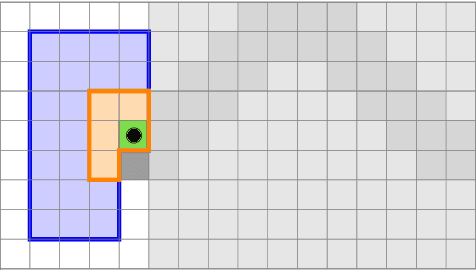
Low-latency instance segmentation of LiDAR point clouds is crucial in real-world applications because it serves as an initial and frequently-used building block in a robot's perception pipeline, where every task adds further delay. Particularly in dynamic environments, this total delay can result in significant positional offsets of dynamic objects, as seen in highway scenarios. To address this issue, we employ continuous clustering of obstacle points in order to obtain an instance-segmented point cloud. Unlike most existing approaches, which use a full revolution of the LiDAR sensor, we process the data stream in a continuous and seamless fashion. More specifically, each column of a range image is processed as soon it is available. Obstacle points are clustered to existing instances in real-time and it is checked at a high-frequency which instances are completed and are ready to be published. An additional advantage is that no problematic discontinuities between the points of the start and the end of a scan are observed. In this work we describe the two-layered data structure and the corresponding algorithm for continuous clustering, which is able to cluster the incoming data in real time. We explain the importance of a large perceptive field of view. Furthermore, we describe and evaluate important architectural design choices, which could be relevant to design an architecture for deep learning based low-latency instance segmentation. We are publishing the source code at https://github.com/UniBwTAS/continuous_clustering.
Compositional Zero-shot Learning via Progressive Language-based Observations
Nov 23, 2023Compositional zero-shot learning aims to recognize unseen state-object compositions by leveraging known primitives (state and object) during training. However, effectively modeling interactions between primitives and generalizing knowledge to novel compositions remains a perennial challenge. There are two key factors: object-conditioned and state-conditioned variance, i.e., the appearance of states (or objects) can vary significantly when combined with different objects (or states). For instance, the state "old" can signify a vintage design for a "car" or an advanced age for a "cat". In this paper, we argue that these variances can be mitigated by predicting composition categories based on pre-observed primitive. To this end, we propose Progressive Language-based Observations (PLO), which can dynamically determine a better observation order of primitives. These observations comprise a series of concepts or languages that allow the model to understand image content in a step-by-step manner. Specifically, PLO adopts pre-trained vision-language models (VLMs) to empower the model with observation capabilities. We further devise two variants: 1) PLO-VLM: a two-step method, where a pre-observing classifier dynamically determines the observation order of two primitives. 2) PLO-LLM: a multi-step scheme, which utilizes large language models (LLMs) to craft composition-specific prompts for step-by-step observing. Extensive ablations on three challenging datasets demonstrate the superiority of PLO compared with state-of-the-art methods, affirming its abilities in compositional recognition.
An Efficient Detection and Control System for Underwater Docking using Machine Learning and Realistic Simulation: A Comprehensive Approach
Nov 06, 2023
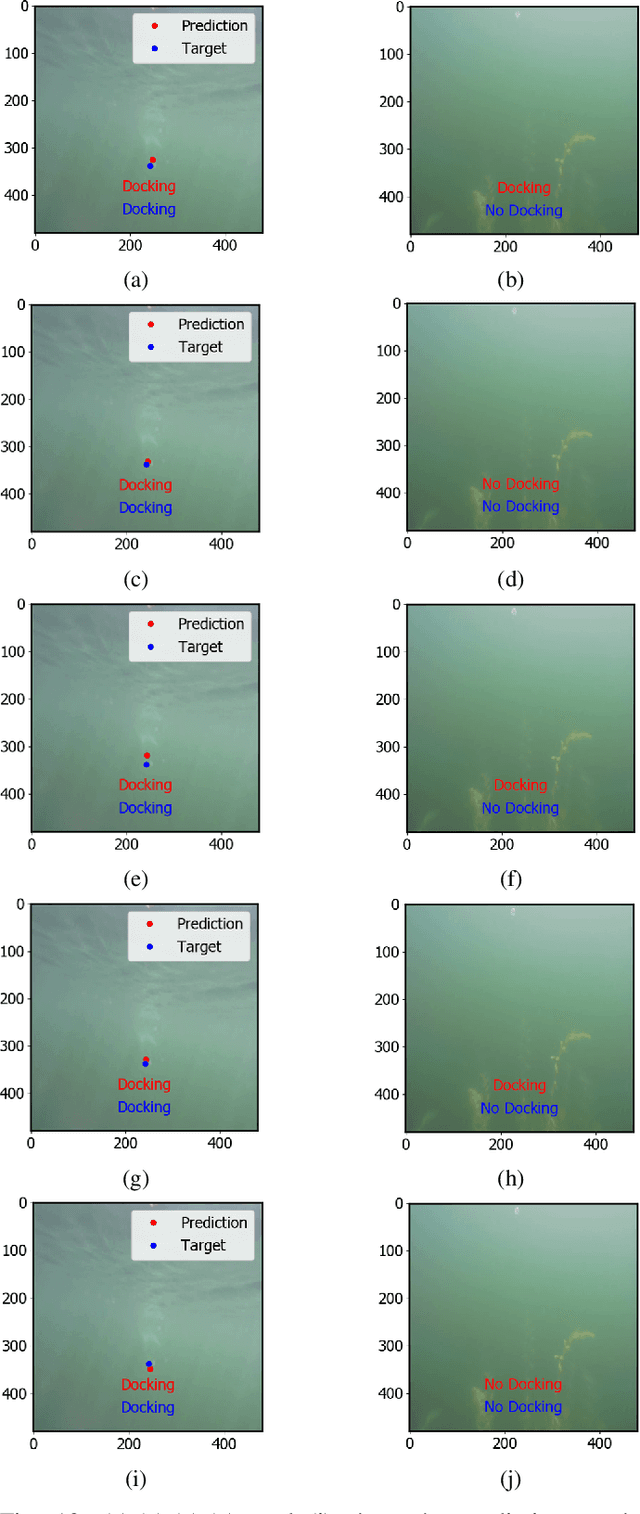


Underwater docking is critical to enable the persistent operation of Autonomous Underwater Vehicles (AUVs). For this, the AUV must be capable of detecting and localizing the docking station, which is complex due to the highly dynamic undersea environment. Image-based solutions offer a high acquisition rate and versatile alternative to adapt to this environment; however, the underwater environment presents challenges such as low visibility, high turbidity, and distortion. In addition to this, field experiments to validate underwater docking capabilities can be costly and dangerous due to the specialized equipment and safety considerations required to conduct the experiments. This work compares different deep-learning architectures to perform underwater docking detection and classification. The architecture with the best performance is then compressed using knowledge distillation under the teacher-student paradigm to reduce the network's memory footprint, allowing real-time implementation. To reduce the simulation-to-reality gap, a Generative Adversarial Network (GAN) is used to do image-to-image translation, converting the Gazebo simulation image into a realistic underwater-looking image. The obtained image is then processed using an underwater image formation model to simulate image attenuation over distance under different water types. The proposed method is finally evaluated according to the AUV docking success rate and compared with classical vision methods. The simulation results show an improvement of 20% in the high turbidity scenarios regardless of the underwater currents. Furthermore, we show the performance of the proposed approach by showing experimental results on the off-the-shelf AUV Iver3.
Data Center Audio/Video Intelligence on Device (DAVID) -- An Edge-AI Platform for Smart-Toys
Nov 18, 2023An overview is given of the DAVID Smart-Toy platform, one of the first Edge AI platform designs to incorporate advanced low-power data processing by neural inference models co-located with the relevant image or audio sensors. There is also on-board capability for in-device text-to-speech generation. Two alternative embodiments are presented: a smart Teddy-bear, and a roving dog-like robot. The platform offers a speech-driven user interface and can observe and interpret user actions and facial expressions via its computer vision sensor node. A particular benefit of this design is that no personally identifiable information passes beyond the neural inference nodes thus providing inbuilt compliance with data protection regulations.
Video Face Re-Aging: Toward Temporally Consistent Face Re-Aging
Nov 20, 2023Video face re-aging deals with altering the apparent age of a person to the target age in videos. This problem is challenging due to the lack of paired video datasets maintaining temporal consistency in identity and age. Most re-aging methods process each image individually without considering the temporal consistency of videos. While some existing works address the issue of temporal coherence through video facial attribute manipulation in latent space, they often fail to deliver satisfactory performance in age transformation. To tackle the issues, we propose (1) a novel synthetic video dataset that features subjects across a diverse range of age groups; (2) a baseline architecture designed to validate the effectiveness of our proposed dataset, and (3) the development of three novel metrics tailored explicitly for evaluating the temporal consistency of video re-aging techniques. Our comprehensive experiments on public datasets, such as VFHQ and CelebV-HQ, show that our method outperforms the existing approaches in terms of both age transformation and temporal consistency.
Generating Realistic Counterfactuals for Retinal Fundus and OCT Images using Diffusion Models
Nov 20, 2023Counterfactual reasoning is often used in a clinical setting to explain decisions or weigh alternatives. Therefore, for imaging based modalities such as ophthalmology, it would be beneficial to be able to create counterfactual images, illustrating the answer to the question: "If the subject had had diabetic retinopathy, how would the fundus image have looked?" Here, we demonstrate that using a diffusion model in combination with an adversarially robust classifier trained on retinal disease classification tasks enables generation of highly realistic counterfactuals of retinal fundus images and optical coherence tomorgraphy (OCT) B-scans. Ideally, these classifiers encode the salient features indicative for each disease class and can steer the diffusion model to show realistic disease signs or remove disease-related lesions in a realistic way. Importantly, in a user study, domain experts found the counterfactuals generated using our method significantly more realistic than counterfactuals generated from a previous method, and even indistiguishable from realistic images.
Few-shot Multispectral Segmentation with Representations Generated by Reinforcement Learning
Nov 20, 2023The task of multispectral image segmentation (segmentation of images with numerous channels/bands, each capturing a specific range of wavelengths of electromagnetic radiation) has been previously explored in contexts with large amounts of labeled data. However, these models tend not to generalize well to datasets of smaller size. In this paper, we propose a novel approach for improving few-shot segmentation performance on multispectral images using reinforcement learning to generate representations. These representations are generated in the form of mathematical expressions between channels and are tailored to the specific class being segmented. Our methodology involves training an agent to identify the most informative expressions, updating the dataset using these expressions, and then using the updated dataset to perform segmentation. Due to the limited length of the expressions, the model receives useful representations without any added risk of overfitting. We evaluate the effectiveness of our approach on several multispectral datasets and demonstrate its effectiveness in boosting the performance of segmentation algorithms.