 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SENetV2: Aggregated dense layer for channelwise and global representations
Nov 17, 2023
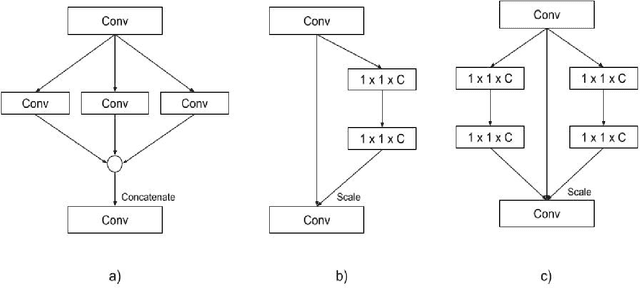
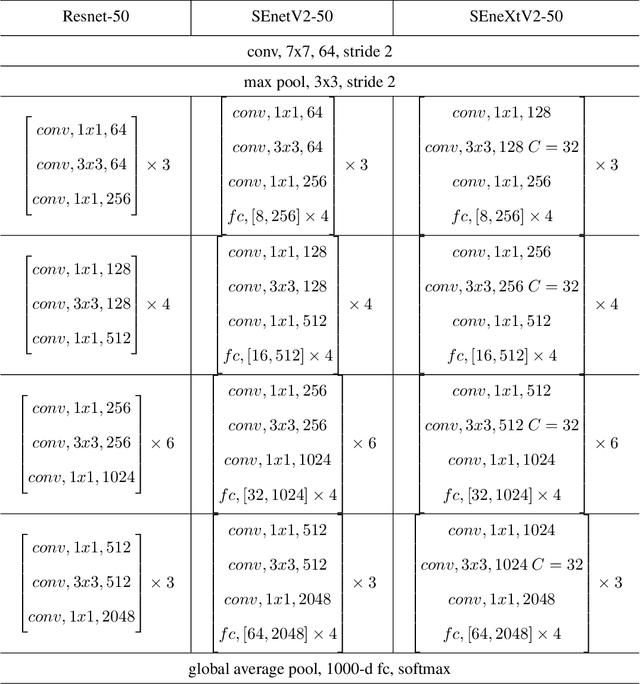
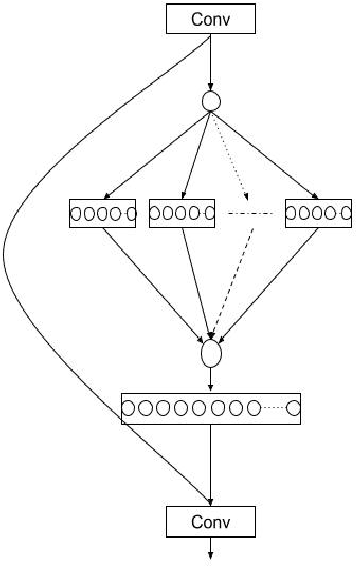
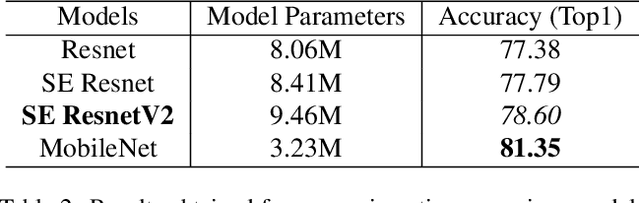
Convolutional Neural Networks (CNNs) have revolutionized image classification by extracting spatial features and enabling state-of-the-art accuracy in vision-based tasks. The squeeze and excitation network proposed module gathers channelwise representations of the input. Multilayer perceptrons (MLP) learn global representation from the data and in most image classification models used to learn extracted features of the image. In this paper, we introduce a novel aggregated multilayer perceptron, a multi-branch dense layer, within the Squeeze excitation residual module designed to surpass the performance of existing architectures. Our approach leverages a combination of squeeze excitation network module with dense layers. This fusion enhances the network's ability to capture channel-wise patterns and have global knowledge, leading to a better feature representation. This proposed model has a negligible increase in parameters when compared to SENet. We conduct extensive experiments on benchmark datasets to validate the model and compare them with established architectures. Experimental results demonstrate a remarkable increase in the classification accuracy of the proposed model.
Improving Faithfulness for Vision Transformers
Nov 29, 2023Vision Transformers (ViTs) have achieved state-of-the-art performance for various vision tasks. One reason behind the success lies in their ability to provide plausible innate explanations for the behavior of neural architectures. However, ViTs suffer from issues with explanation faithfulness, as their focal points are fragile to adversarial attacks and can be easily changed with even slight perturbations on the input image. In this paper, we propose a rigorous approach to mitigate these issues by introducing Faithful ViTs (FViTs). Briefly speaking, an FViT should have the following two properties: (1) The top-$k$ indices of its self-attention vector should remain mostly unchanged under input perturbation, indicating stable explanations; (2) The prediction distribution should be robust to perturbations. To achieve this, we propose a new method called Denoised Diffusion Smoothing (DDS), which adopts randomized smoothing and diffusion-based denoising. We theoretically prove that processing ViTs directly with DDS can turn them into FViTs. We also show that Gaussian noise is nearly optimal for both $\ell_2$ and $\ell_\infty$-norm cases. Finally, we demonstrate the effectiveness of our approach through comprehensive experiments and evaluations. Specifically, we compare our FViTs with other baselines through visual interpretation and robustness accuracy under adversarial attacks. Results show that FViTs are more robust against adversarial attacks while maintaining the explainability of attention, indicating higher faithfulness.
C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Nov 29, 2023We present Compound Conditioned ControlNet, C3Net, a novel generative neural architecture taking conditions from multiple modalities and synthesizing multimodal contents simultaneously (e.g., image, text, audio). C3Net adapts the ControlNet architecture to jointly train and make inferences on a production-ready diffusion model and its trainable copies. Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training. Then, it generates multimodal outputs based on the aligned latent space, whose semantic information is combined using a ControlNet-like architecture called Control C3-UNet. Correspondingly, with this system design, our model offers an improved solution for joint-modality generation through learning and explaining multimodal conditions instead of simply taking linear interpolations on the latent space. Meanwhile, as we align conditions to a unified latent space, C3Net only requires one trainable Control C3-UNet to work on multimodal semantic information. Furthermore, our model employs unimodal pretraining on the condition alignment stage, outperforming the non-pretrained alignment even on relatively scarce training data and thus demonstrating high-quality compound condition generation. We contribute the first high-quality tri-modal validation set to validate quantitatively that C3Net outperforms or is on par with first and contemporary state-of-the-art multimodal generation. Our codes and tri-modal dataset will be released.
Bounding and Filling: A Fast and Flexible Framework for Image Captioning
Oct 15, 2023Most image captioning models following an autoregressive manner suffer from significant inference latency. Several models adopted a non-autoregressive manner to speed up the process. However, the vanilla non-autoregressive manner results in subpar performance, since it generates all words simultaneously, which fails to capture the relationships between words in a description. The semi-autoregressive manner employs a partially parallel method to preserve performance, but it sacrifices inference speed. In this paper, we introduce a fast and flexible framework for image captioning called BoFiCap based on bounding and filling techniques. The BoFiCap model leverages the inherent characteristics of image captioning tasks to pre-define bounding boxes for image regions and their relationships. Subsequently, the BoFiCap model fills corresponding words in each box using two-generation manners. Leveraging the box hints, our filling process allows each word to better perceive other words. Additionally, our model offers flexible image description generation: 1) by employing different generation manners based on speed or performance requirements, 2) producing varied sentences based on user-specified boxes. Experimental evaluations on the MS-COCO benchmark dataset demonstrate that our framework in a non-autoregressive manner achieves the state-of-the-art on task-specific metric CIDEr (125.6) while speeding up 9.22x than the baseline model with an autoregressive manner; in a semi-autoregressive manner, our method reaches 128.4 on CIDEr while a 3.69x speedup. Our code and data is available at https://github.com/ChangxinWang/BoFiCap.
Nighttime Thermal Infrared Image Colorization with Feedback-based Object Appearance Learning
Oct 24, 2023Stable imaging in adverse environments (e.g., total darkness) makes thermal infrared (TIR) cameras a prevalent option for night scene perception. However, the low contrast and lack of chromaticity of TIR images are detrimental to human interpretation and subsequent deployment of RGB-based vision algorithms. Therefore, it makes sense to colorize the nighttime TIR images by translating them into the corresponding daytime color images (NTIR2DC). Despite the impressive progress made in the NTIR2DC task, how to improve the translation performance of small object classes is under-explored. To address this problem, we propose a generative adversarial network incorporating feedback-based object appearance learning (FoalGAN). Specifically, an occlusion-aware mixup module and corresponding appearance consistency loss are proposed to reduce the context dependence of object translation. As a representative example of small objects in nighttime street scenes, we illustrate how to enhance the realism of traffic light by designing a traffic light appearance loss. To further improve the appearance learning of small objects, we devise a dual feedback learning strategy to selectively adjust the learning frequency of different samples. In addition, we provide pixel-level annotation for a subset of the Brno dataset, which can facilitate the research of NTIR image understanding under multiple weather conditions. Extensive experiments illustrate that the proposed FoalGAN is not only effective for appearance learning of small objects, but also outperforms other image translation methods in terms of semantic preservation and edge consistency for the NTIR2DC task.
Radiology Report Generation Using Transformers Conditioned with Non-imaging Data
Nov 18, 2023Medical image interpretation is central to most clinical applications such as disease diagnosis, treatment planning, and prognostication. In clinical practice, radiologists examine medical images and manually compile their findings into reports, which can be a time-consuming process. Automated approaches to radiology report generation, therefore, can reduce radiologist workload and improve efficiency in the clinical pathway. While recent deep-learning approaches for automated report generation from medical images have seen some success, most studies have relied on image-derived features alone, ignoring non-imaging patient data. Although a few studies have included the word-level contexts along with the image, the use of patient demographics is still unexplored. This paper proposes a novel multi-modal transformer network that integrates chest x-ray (CXR) images and associated patient demographic information, to synthesise patient-specific radiology reports. The proposed network uses a convolutional neural network to extract visual features from CXRs and a transformer-based encoder-decoder network that combines the visual features with semantic text embeddings of patient demographic information, to synthesise full-text radiology reports. Data from two public databases were used to train and evaluate the proposed approach. CXRs and reports were extracted from the MIMIC-CXR database and combined with corresponding patients' data MIMIC-IV. Based on the evaluation metrics used including patient demographic information was found to improve the quality of reports generated using the proposed approach, relative to a baseline network trained using CXRs alone. The proposed approach shows potential for enhancing radiology report generation by leveraging rich patient metadata and combining semantic text embeddings derived thereof, with medical image-derived visual features.
A Study on Altering the Latent Space of Pretrained Text to Speech Models for Improved Expressiveness
Nov 17, 2023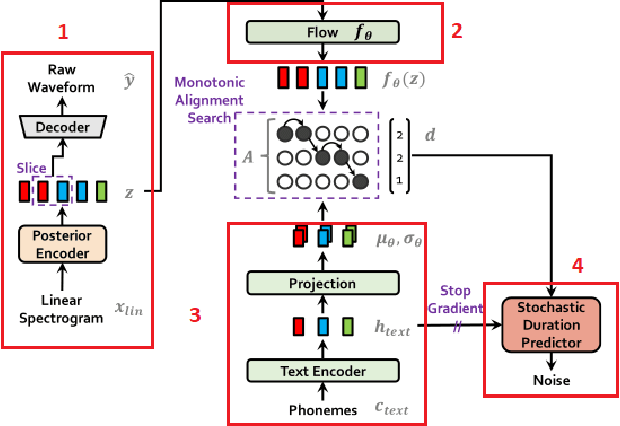
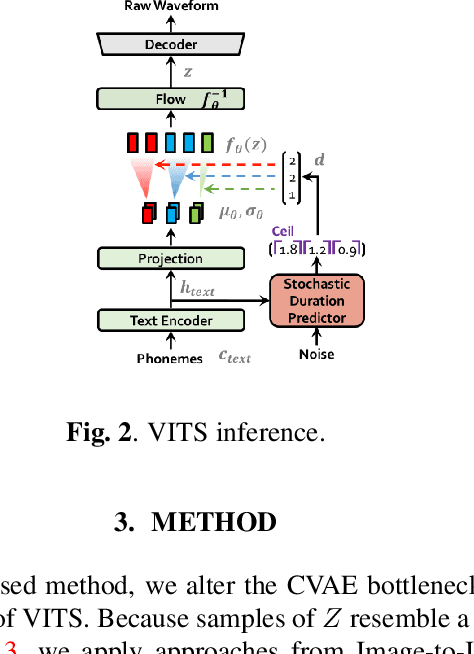

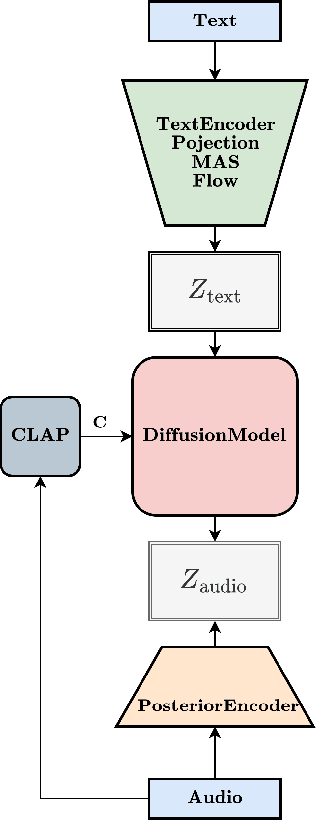
This report explores the challenge of enhancing expressiveness control in Text-to-Speech (TTS) models by augmenting a frozen pretrained model with a Diffusion Model that is conditioned on joint semantic audio/text embeddings. The paper identifies the challenges encountered when working with a VAE-based TTS model and evaluates different image-to-image methods for altering latent speech features. Our results offer valuable insights into the complexities of adding expressiveness control to TTS systems and open avenues for future research in this direction.
A Principled Hierarchical Deep Learning Approach to Joint Image Compression and Classification
Oct 30, 2023Among applications of deep learning (DL) involving low cost sensors, remote image classification involves a physical channel that separates edge sensors and cloud classifiers. Traditional DL models must be divided between an encoder for the sensor and the decoder + classifier at the edge server. An important challenge is to effectively train such distributed models when the connecting channels have limited rate/capacity. Our goal is to optimize DL models such that the encoder latent requires low channel bandwidth while still delivers feature information for high classification accuracy. This work proposes a three-step joint learning strategy to guide encoders to extract features that are compact, discriminative, and amenable to common augmentations/transformations. We optimize latent dimension through an initial screening phase before end-to-end (E2E) training. To obtain an adjustable bit rate via a single pre-deployed encoder, we apply entropy-based quantization and/or manual truncation on the latent representations. Tests show that our proposed method achieves accuracy improvement of up to 1.5% on CIFAR-10 and 3% on CIFAR-100 over conventional E2E cross-entropy training.
Image Super-resolution Via Latent Diffusion: A Sampling-space Mixture Of Experts And Frequency-augmented Decoder Approach
Oct 20, 2023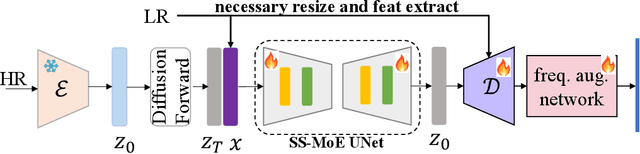

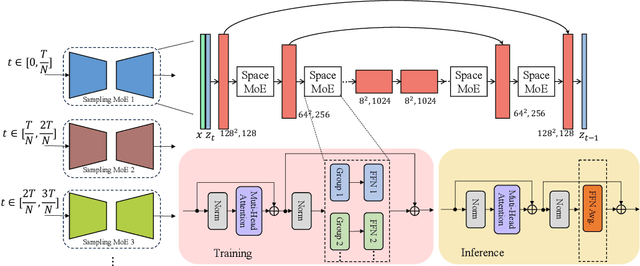
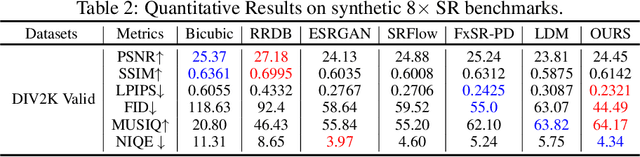
The recent use of diffusion prior, enhanced by pre-trained text-image models, has markedly elevated the performance of image super-resolution (SR). To alleviate the huge computational cost required by pixel-based diffusion SR, latent-based methods utilize a feature encoder to transform the image and then implement the SR image generation in a compact latent space. Nevertheless, there are two major issues that limit the performance of latent-based diffusion. First, the compression of latent space usually causes reconstruction distortion. Second, huge computational cost constrains the parameter scale of the diffusion model. To counteract these issues, we first propose a frequency compensation module that enhances the frequency components from latent space to pixel space. The reconstruction distortion (especially for high-frequency information) can be significantly decreased. Then, we propose to use Sample-Space Mixture of Experts (SS-MoE) to achieve more powerful latent-based SR, which steadily improves the capacity of the model without a significant increase in inference costs. These carefully crafted designs contribute to performance improvements in largely explored 4x blind super-resolution benchmarks and extend to large magnification factors, i.e., 8x image SR benchmarks. The code is available at https://github.com/amandaluof/moe_sr.
An Innovative Tool for Uploading/Scraping Large Image Datasets on Social Networks
Nov 01, 2023Nowadays, people can retrieve and share digital information in an increasingly easy and fast fashion through the well-known digital platforms, including sensitive data, inappropriate or illegal content, and, in general, information that might serve as probative evidence in court. Consequently, to assess forensics issues, we need to figure out how to trace back to the posting chain of a digital evidence (e.g., a picture, an audio) throughout the involved platforms -- this is what Digital (also Forensics) Ballistics basically deals with. With the entry of Machine Learning as a tool of the trade in many research areas, the need for vast amounts of data has been dramatically increasing over the last few years. However, collecting or simply find the "right" datasets that properly enables data-driven research studies can turn out to be not trivial in some cases, if not extremely challenging, especially when it comes with highly specialized tasks, such as creating datasets analyzed to detect the source media platform of a given digital media. In this paper we propose an automated approach by means of a digital tool that we created on purpose. The tool is capable of automatically uploading an entire image dataset to the desired digital platform and then downloading all the uploaded pictures, thus shortening the overall time required to output the final dataset to be analyzed.