 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Regularized Compound Gaussian Network for Solving Linear Inverse Problems
Nov 28, 2023
Incorporating prior information into inverse problems, e.g. via maximum-a-posteriori estimation, is an important technique for facilitating robust inverse problem solutions. In this paper, we devise two novel approaches for linear inverse problems that permit problem-specific statistical prior selections within the compound Gaussian (CG) class of distributions. The CG class subsumes many commonly used priors in signal and image reconstruction methods including those of sparsity-based approaches. The first method developed is an iterative algorithm, called generalized compound Gaussian least squares (G-CG-LS), that minimizes a regularized least squares objective function where the regularization enforces a CG prior. G-CG-LS is then unrolled, or unfolded, to furnish our second method, which is a novel deep regularized (DR) neural network, called DR-CG-Net, that learns the prior information. A detailed computational theory on convergence properties of G-CG-LS and thorough numerical experiments for DR-CG-Net are provided. Due to the comprehensive nature of the CG prior, these experiments show that our unrolled DR-CG-Net outperforms competitive prior art methods in tomographic imaging and compressive sensing, especially in challenging low-training scenarios.
Astronomical Images Quality Assessment with Automated Machine Learning
Nov 17, 2023Electronically Assisted Astronomy consists in capturing deep sky images with a digital camera coupled to a telescope to display views of celestial objects that would have been invisible through direct observation. This practice generates a large quantity of data, which may then be enhanced with dedicated image editing software after observation sessions. In this study, we show how Image Quality Assessment can be useful for automatically rating astronomical images, and we also develop a dedicated model by using Automated Machine Learning.
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
SimulFlow: Simultaneously Extracting Feature and Identifying Target for Unsupervised Video Object Segmentation
Nov 30, 2023Unsupervised video object segmentation (UVOS) aims at detecting the primary objects in a given video sequence without any human interposing. Most existing methods rely on two-stream architectures that separately encode the appearance and motion information before fusing them to identify the target and generate object masks. However, this pipeline is computationally expensive and can lead to suboptimal performance due to the difficulty of fusing the two modalities properly. In this paper, we propose a novel UVOS model called SimulFlow that simultaneously performs feature extraction and target identification, enabling efficient and effective unsupervised video object segmentation. Concretely, we design a novel SimulFlow Attention mechanism to bridege the image and motion by utilizing the flexibility of attention operation, where coarse masks predicted from fused feature at each stage are used to constrain the attention operation within the mask area and exclude the impact of noise. Because of the bidirectional information flow between visual and optical flow features in SimulFlow Attention, no extra hand-designed fusing module is required and we only adopt a light decoder to obtain the final prediction. We evaluate our method on several benchmark datasets and achieve state-of-the-art results. Our proposed approach not only outperforms existing methods but also addresses the computational complexity and fusion difficulties caused by two-stream architectures. Our models achieve 87.4% J & F on DAVIS-16 with the highest speed (63.7 FPS on a 3090) and the lowest parameters (13.7 M). Our SimulFlow also obtains competitive results on video salient object detection datasets.
X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .
ViLaM: A Vision-Language Model with Enhanced Visual Grounding and Generalization Capability
Nov 21, 2023Vision-language models have revolutionized human-computer interaction and shown significant progress in multi-modal tasks. However, applying these models to complex visual tasks like medical image analysis remains challenging. In this study, we propose ViLaM, a unified Vision-Language transformer model that integrates instruction tuning predicated on a large language model. This approach enables us to optimally utilize the knowledge and reasoning capacities of large pre-trained language models for an array of tasks encompassing both language and vision. We employ frozen pre-trained encoders to encode and align both image and text features, enabling ViLaM to handle a variety of visual tasks following textual instructions. Besides, we've designed cycle training for referring expressions to address the need for high-quality, paired referring expression datasets for training large models in terms of both quantity and quality. We evaluated ViLaM's exceptional performance on public general datasets and further confirmed its generalizability on medical datasets. Importantly, we've observed the model's impressive zero-shot learning ability, indicating the potential future application of ViLaM in the medical field.
Novel OCT mosaicking pipeline with Feature- and Pixel-based registration
Nov 21, 2023High-resolution Optical Coherence Tomography (OCT) images are crucial for ophthalmology studies but are limited by their relatively narrow field of view (FoV). Image mosaicking is a technique for aligning multiple overlapping images to obtain a larger FoV. Current mosaicking pipelines often struggle with substantial noise and considerable displacement between the input sub-fields. In this paper, we propose a versatile pipeline for stitching multi-view OCT/OCTA \textit{en face} projection images. Our method combines the strengths of learning-based feature matching and robust pixel-based registration to align multiple images effectively. Furthermore, we advance the application of a trained foundational model, Segment Anything Model (SAM), to validate mosaicking results in an unsupervised manner. The efficacy of our pipeline is validated using an in-house dataset and a large public dataset, where our method shows superior performance in terms of both accuracy and computational efficiency. We also made our evaluation tool for image mosaicking and the corresponding pipeline publicly available at \url{https://github.com/MedICL-VU/OCT-mosaicking}.
Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
Oct 10, 2023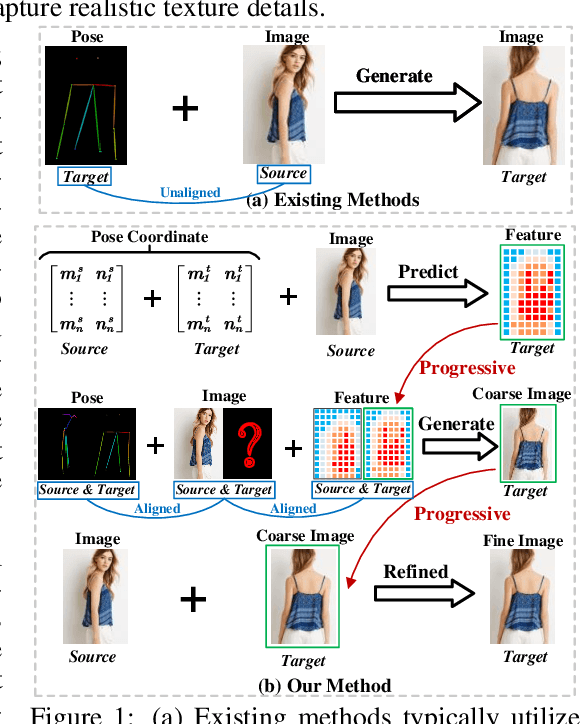
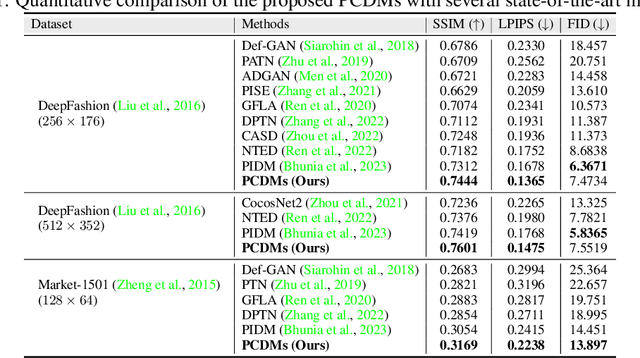
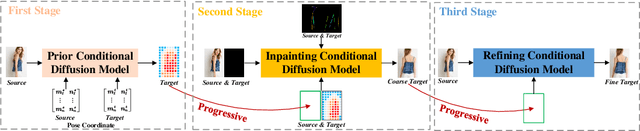
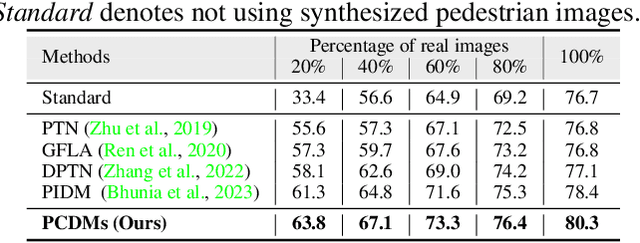
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/muzishen/PCDMs.
Does complimentary information from multispectral imaging improve face presentation attack detection?
Nov 20, 2023Presentation Attack Detection (PAD) has been extensively studied, particularly in the visible spectrum. With the advancement of sensing technology beyond the visible range, multispectral imaging has gained significant attention in this direction. We present PAD based on multispectral images constructed for eight different presentation artifacts resulted from three different artifact species. In this work, we introduce Face Presentation Attack Multispectral (FPAMS) database to demonstrate the significance of employing multispectral imaging. The goal of this work is to study complementary information that can be combined in two different ways (image fusion and score fusion) from multispectral imaging to improve the face PAD. The experimental evaluation results present an extensive qualitative analysis of 61650 sample multispectral images collected for bonafide and artifacts. The PAD based on the score fusion and image fusion method presents superior performance, demonstrating the significance of employing multispectral imaging to detect presentation artifacts.
Improving Faithfulness for Vision Transformers
Nov 29, 2023Vision Transformers (ViTs) have achieved state-of-the-art performance for various vision tasks. One reason behind the success lies in their ability to provide plausible innate explanations for the behavior of neural architectures. However, ViTs suffer from issues with explanation faithfulness, as their focal points are fragile to adversarial attacks and can be easily changed with even slight perturbations on the input image. In this paper, we propose a rigorous approach to mitigate these issues by introducing Faithful ViTs (FViTs). Briefly speaking, an FViT should have the following two properties: (1) The top-$k$ indices of its self-attention vector should remain mostly unchanged under input perturbation, indicating stable explanations; (2) The prediction distribution should be robust to perturbations. To achieve this, we propose a new method called Denoised Diffusion Smoothing (DDS), which adopts randomized smoothing and diffusion-based denoising. We theoretically prove that processing ViTs directly with DDS can turn them into FViTs. We also show that Gaussian noise is nearly optimal for both $\ell_2$ and $\ell_\infty$-norm cases. Finally, we demonstrate the effectiveness of our approach through comprehensive experiments and evaluations. Specifically, we compare our FViTs with other baselines through visual interpretation and robustness accuracy under adversarial attacks. Results show that FViTs are more robust against adversarial attacks while maintaining the explainability of attention, indicating higher faithfulness.