 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024
Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
MoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024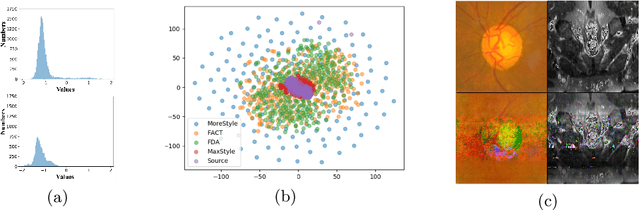
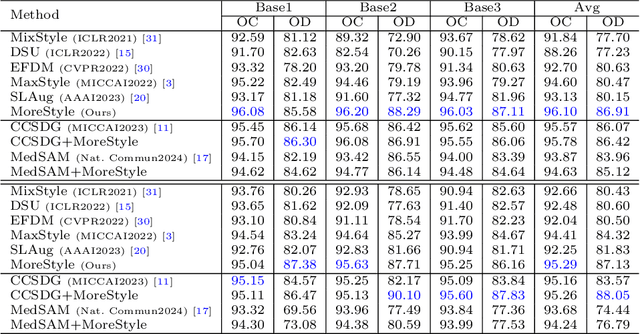
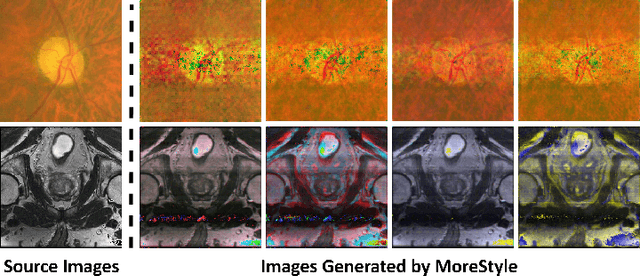
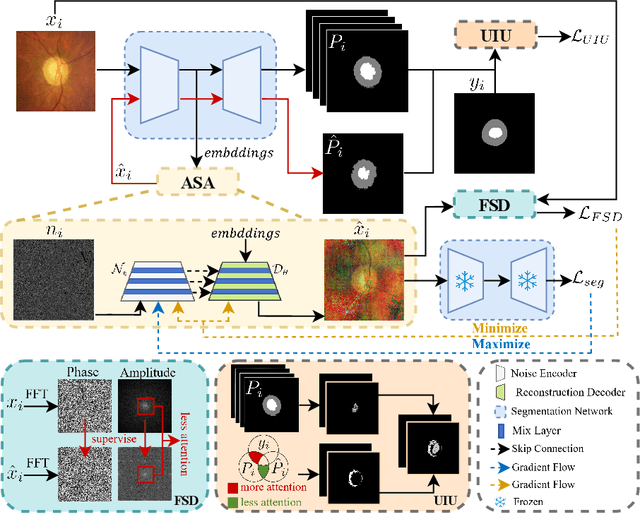
The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
Learning by Correction: Efficient Tuning Task for Zero-Shot Generative Vision-Language Reasoning
Apr 01, 2024Generative vision-language models (VLMs) have shown impressive performance in zero-shot vision-language tasks like image captioning and visual question answering. However, improving their zero-shot reasoning typically requires second-stage instruction tuning, which relies heavily on human-labeled or large language model-generated annotation, incurring high labeling costs. To tackle this challenge, we introduce Image-Conditioned Caption Correction (ICCC), a novel pre-training task designed to enhance VLMs' zero-shot performance without the need for labeled task-aware data. The ICCC task compels VLMs to rectify mismatches between visual and language concepts, thereby enhancing instruction following and text generation conditioned on visual inputs. Leveraging language structure and a lightweight dependency parser, we construct data samples of ICCC task from image-text datasets with low labeling and computation costs. Experimental results on BLIP-2 and InstructBLIP demonstrate significant improvements in zero-shot image-text generation-based VL tasks through ICCC instruction tuning.
Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation
Mar 25, 2024The literature on text-to-image generation is plagued by issues of faithfully composing entities with relations. But there lacks a formal understanding of how entity-relation compositions can be effectively learned. Moreover, the underlying phenomenon space that meaningfully reflects the problem structure is not well-defined, leading to an arms race for larger quantities of data in the hope that generalization emerges out of large-scale pretraining. We hypothesize that the underlying phenomenological coverage has not been proportionally scaled up, leading to a skew of the presented phenomenon which harms generalization. We introduce statistical metrics that quantify both the linguistic and visual skew of a dataset for relational learning, and show that generalization failures of text-to-image generation are a direct result of incomplete or unbalanced phenomenological coverage. We first perform experiments in a synthetic domain and demonstrate that systematically controlled metrics are strongly predictive of generalization performance. Then we move to natural images and show that simple distribution perturbations in light of our theories boost generalization without enlarging the absolute data size. This work informs an important direction towards quality-enhancing the data diversity or balance orthogonal to scaling up the absolute size. Our discussions point out important open questions on 1) Evaluation of generated entity-relation compositions, and 2) Better models for reasoning with abstract relations.
Translation-based Video-to-Video Synthesis
Apr 03, 2024Translation-based Video Synthesis (TVS) has emerged as a vital research area in computer vision, aiming to facilitate the transformation of videos between distinct domains while preserving both temporal continuity and underlying content features. This technique has found wide-ranging applications, encompassing video super-resolution, colorization, segmentation, and more, by extending the capabilities of traditional image-to-image translation to the temporal domain. One of the principal challenges faced in TVS is the inherent risk of introducing flickering artifacts and inconsistencies between frames during the synthesis process. This is particularly challenging due to the necessity of ensuring smooth and coherent transitions between video frames. Efforts to tackle this challenge have induced the creation of diverse strategies and algorithms aimed at mitigating these unwanted consequences. This comprehensive review extensively examines the latest progress in the realm of TVS. It thoroughly investigates emerging methodologies, shedding light on the fundamental concepts and mechanisms utilized for proficient video synthesis. This survey also illuminates their inherent strengths, limitations, appropriate applications, and potential avenues for future development.
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Apr 02, 2024In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
Autonomous Artificial Intelligence Agents for Clinical Decision Making in Oncology
Apr 06, 2024Multimodal artificial intelligence (AI) systems have the potential to enhance clinical decision-making by interpreting various types of medical data. However, the effectiveness of these models across all medical fields is uncertain. Each discipline presents unique challenges that need to be addressed for optimal performance. This complexity is further increased when attempting to integrate different fields into a single model. Here, we introduce an alternative approach to multimodal medical AI that utilizes the generalist capabilities of a large language model (LLM) as a central reasoning engine. This engine autonomously coordinates and deploys a set of specialized medical AI tools. These tools include text, radiology and histopathology image interpretation, genomic data processing, web searches, and document retrieval from medical guidelines. We validate our system across a series of clinical oncology scenarios that closely resemble typical patient care workflows. We show that the system has a high capability in employing appropriate tools (97%), drawing correct conclusions (93.6%), and providing complete (94%), and helpful (89.2%) recommendations for individual patient cases while consistently referencing relevant literature (82.5%) upon instruction. This work provides evidence that LLMs can effectively plan and execute domain-specific models to retrieve or synthesize new information when used as autonomous agents. This enables them to function as specialist, patient-tailored clinical assistants. It also simplifies regulatory compliance by allowing each component tool to be individually validated and approved. We believe, that our work can serve as a proof-of-concept for more advanced LLM-agents in the medical domain.
Smooth Deep Saliency
Apr 04, 2024In this work, we investigate methods to reduce the noise in deep saliency maps coming from convolutional downsampling, with the purpose of explaining how a deep learning model detects tumors in scanned histological tissue samples. Those methods make the investigated models more interpretable for gradient-based saliency maps, computed in hidden layers. We test our approach on different models trained for image classification on ImageNet1K, and models trained for tumor detection on Camelyon16 and in-house real-world digital pathology scans of stained tissue samples. Our results show that the checkerboard noise in the gradient gets reduced, resulting in smoother and therefore easier to interpret saliency maps.