 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ImagenHub: Standardizing the evaluation of conditional image generation models
Oct 02, 2023
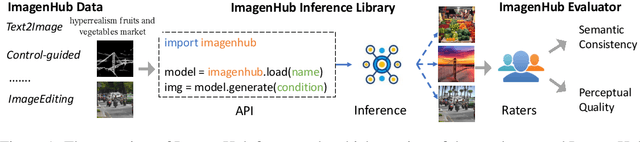
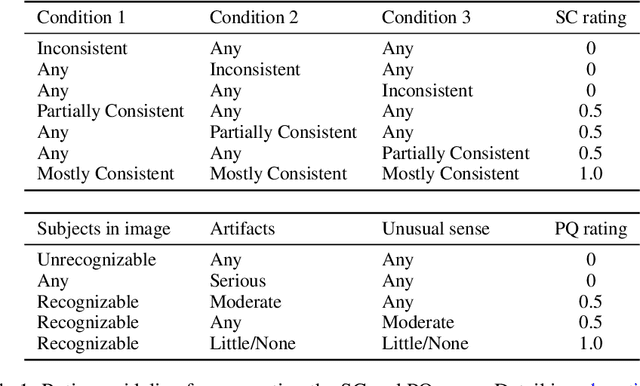
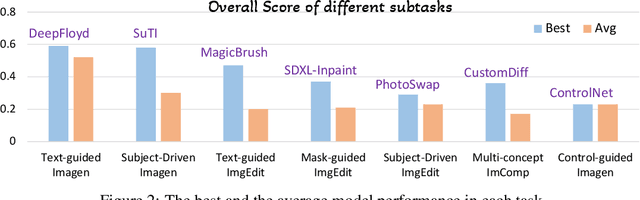
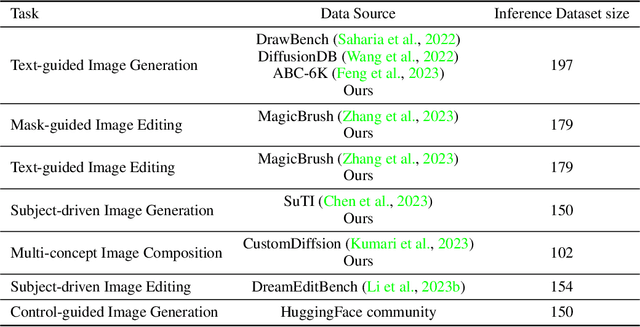
Recently, a myriad of conditional image generation and editing models have been developed to serve different downstream tasks, including text-to-image generation, text-guided image editing, subject-driven image generation, control-guided image generation, etc. However, we observe huge inconsistencies in experimental conditions: datasets, inference, and evaluation metrics - render fair comparisons difficult. This paper proposes ImagenHub, which is a one-stop library to standardize the inference and evaluation of all the conditional image generation models. Firstly, we define seven prominent tasks and curate high-quality evaluation datasets for them. Secondly, we built a unified inference pipeline to ensure fair comparison. Thirdly, we design two human evaluation scores, i.e. Semantic Consistency and Perceptual Quality, along with comprehensive guidelines to evaluate generated images. We train expert raters to evaluate the model outputs based on the proposed metrics. Our human evaluation achieves a high inter-worker agreement of Krippendorff's alpha on 76% models with a value higher than 0.4. We comprehensively evaluated a total of around 30 models and observed three key takeaways: (1) the existing models' performance is generally unsatisfying except for Text-guided Image Generation and Subject-driven Image Generation, with 74% models achieving an overall score lower than 0.5. (2) we examined the claims from published papers and found 83% of them hold with a few exceptions. (3) None of the existing automatic metrics has a Spearman's correlation higher than 0.2 except subject-driven image generation. Moving forward, we will continue our efforts to evaluate newly published models and update our leaderboard to keep track of the progress in conditional image generation.
Knowledge Extraction and Distillation from Large-Scale Image-Text Colonoscopy Records Leveraging Large Language and Vision Models
Oct 17, 2023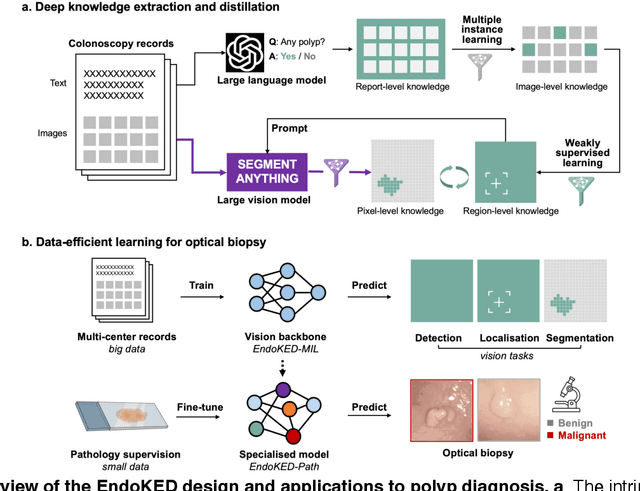
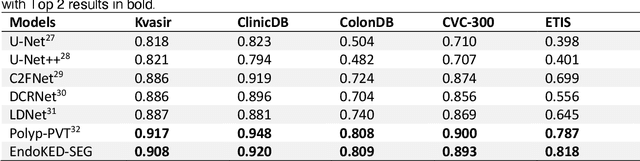
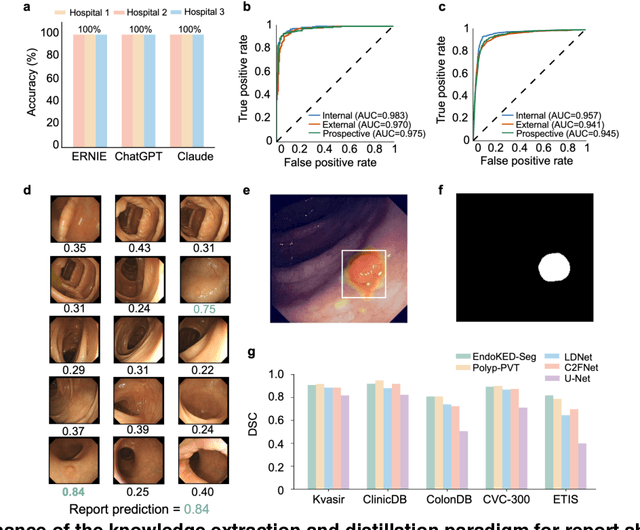
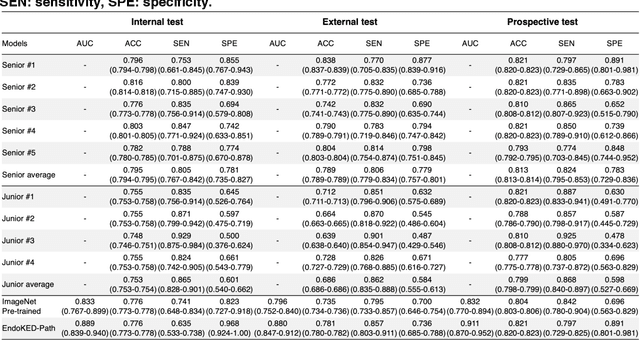
The development of artificial intelligence systems for colonoscopy analysis often necessitates expert-annotated image datasets. However, limitations in dataset size and diversity impede model performance and generalisation. Image-text colonoscopy records from routine clinical practice, comprising millions of images and text reports, serve as a valuable data source, though annotating them is labour-intensive. Here we leverage recent advancements in large language and vision models and propose EndoKED, a data mining paradigm for deep knowledge extraction and distillation. EndoKED automates the transformation of raw colonoscopy records into image datasets with pixel-level annotation. We validate EndoKED using multi-centre datasets of raw colonoscopy records (~1 million images), demonstrating its superior performance in training polyp detection and segmentation models. Furthermore, the EndoKED pre-trained vision backbone enables data-efficient and generalisable learning for optical biopsy, achieving expert-level performance in both retrospective and prospective validation.
Constructing Image-Text Pair Dataset from Books
Oct 03, 2023Digital archiving is becoming widespread owing to its effectiveness in protecting valuable books and providing knowledge to many people electronically. In this paper, we propose a novel approach to leverage digital archives for machine learning. If we can fully utilize such digitized data, machine learning has the potential to uncover unknown insights and ultimately acquire knowledge autonomously, just like humans read books. As a first step, we design a dataset construction pipeline comprising an optical character reader (OCR), an object detector, and a layout analyzer for the autonomous extraction of image-text pairs. In our experiments, we apply our pipeline on old photo books to construct an image-text pair dataset, showing its effectiveness in image-text retrieval and insight extraction.
Shifting to Machine Supervision: Annotation-Efficient Semi and Self-Supervised Learning for Automatic Medical Image Segmentation and Classification
Nov 17, 2023Advancements in clinical treatment and research are limited by supervised learning techniques that rely on large amounts of annotated data, an expensive task requiring many hours of clinical specialists' time. In this paper, we propose using self-supervised and semi-supervised learning. These techniques perform an auxiliary task that is label-free, scaling up machine-supervision is easier compared with fully-supervised techniques. This paper proposes S4MI (Self-Supervision and Semi-Supervision for Medical Imaging), our pipeline to leverage advances in self and semi-supervision learning. We benchmark them on three medical imaging datasets to analyze their efficacy for classification and segmentation. This advancement in self-supervised learning with 10% annotation performed better than 100% annotation for the classification of most datasets. The semi-supervised approach yielded favorable outcomes for segmentation, outperforming the fully-supervised approach by using 50% fewer labels in all three datasets.
A Comparative Study of Pre-trained CNNs and GRU-Based Attention for Image Caption Generation
Oct 11, 2023
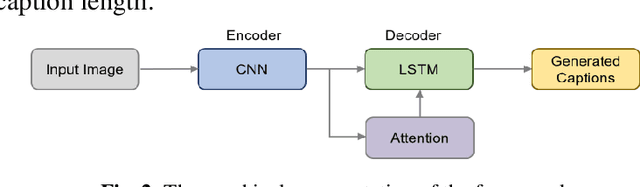
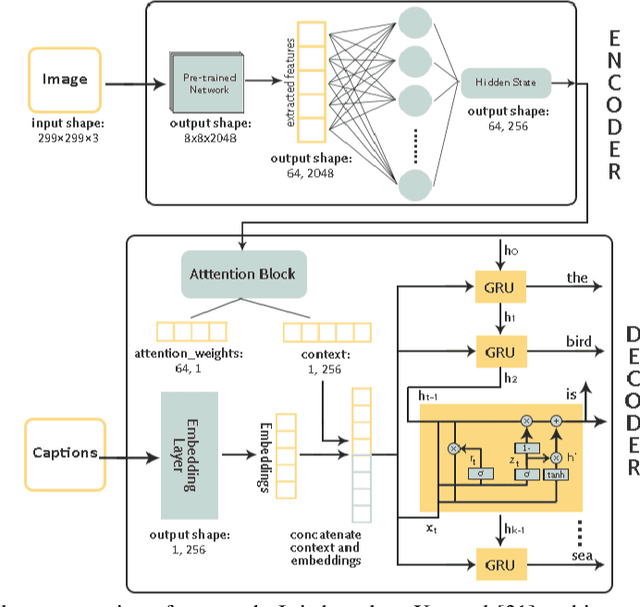
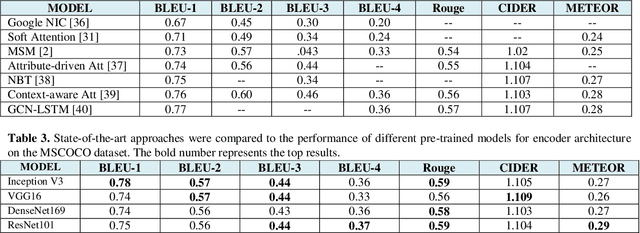
Image captioning is a challenging task involving generating a textual description for an image using computer vision and natural language processing techniques. This paper proposes a deep neural framework for image caption generation using a GRU-based attention mechanism. Our approach employs multiple pre-trained convolutional neural networks as the encoder to extract features from the image and a GRU-based language model as the decoder to generate descriptive sentences. To improve performance, we integrate the Bahdanau attention model with the GRU decoder to enable learning to focus on specific image parts. We evaluate our approach using the MSCOCO and Flickr30k datasets and show that it achieves competitive scores compared to state-of-the-art methods. Our proposed framework can bridge the gap between computer vision and natural language and can be extended to specific domains.
Tubular Curvature Filter: Implicit Pointwise Curvature Calculation Method for Tubular Objects
Nov 20, 2023Curvature estimation methods are important as they capture salient features for various applications in image processing, especially within medical domains where tortuosity of vascular structures is of significant interest. Existing methods based on centerline or skeleton curvature fail to capture curvature gradients across a rotating tubular structure. This paper presents a Tubular Curvature Filter method that locally calculates the acceleration of bundles of curves that traverse along the tubular object parallel to the centerline. This is achieved by examining the directional rate of change in the eigenvectors of the Hessian matrix of a tubular intensity function in space. This method implicitly calculates the local tubular curvature without the need to explicitly segment the tubular object. Experimental results demonstrate that the Tubular Curvature Filter method provides accurate estimates of local curvature at any point inside tubular structures.
R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation
Oct 26, 2023Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
ViStruct: Visual Structural Knowledge Extraction via Curriculum Guided Code-Vision Representation
Nov 22, 2023
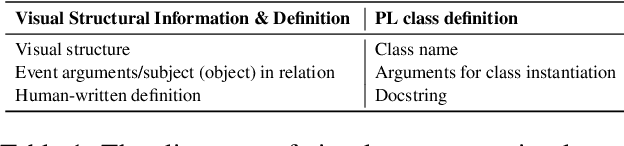


State-of-the-art vision-language models (VLMs) still have limited performance in structural knowledge extraction, such as relations between objects. In this work, we present ViStruct, a training framework to learn VLMs for effective visual structural knowledge extraction. Two novel designs are incorporated. First, we propose to leverage the inherent structure of programming language to depict visual structural information. This approach enables explicit and consistent representation of visual structural information of multiple granularities, such as concepts, relations, and events, in a well-organized structured format. Second, we introduce curriculum-based learning for VLMs to progressively comprehend visual structures, from fundamental visual concepts to intricate event structures. Our intuition is that lower-level knowledge may contribute to complex visual structure understanding. Furthermore, we compile and release a collection of datasets tailored for visual structural knowledge extraction. We adopt a weakly-supervised approach to directly generate visual event structures from captions for ViStruct training, capitalizing on abundant image-caption pairs from the web. In experiments, we evaluate ViStruct on visual structure prediction tasks, demonstrating its effectiveness in improving the understanding of visual structures. The code is public at \url{https://github.com/Yangyi-Chen/vi-struct}.
Volumetric Reconstruction Resolves Off-Resonance Artifacts in Static and Dynamic PROPELLER MRI
Nov 22, 2023Off-resonance artifacts in magnetic resonance imaging (MRI) are visual distortions that occur when the actual resonant frequencies of spins within the imaging volume differ from the expected frequencies used to encode spatial information. These discrepancies can be caused by a variety of factors, including magnetic field inhomogeneities, chemical shifts, or susceptibility differences within the tissues. Such artifacts can manifest as blurring, ghosting, or misregistration of the reconstructed image, and they often compromise its diagnostic quality. We propose to resolve these artifacts by lifting the 2D MRI reconstruction problem to 3D, introducing an additional "spectral" dimension to model this off-resonance. Our approach is inspired by recent progress in modeling radiance fields, and is capable of reconstructing both static and dynamic MR images as well as separating fat and water, which is of independent clinical interest. We demonstrate our approach in the context of PROPELLER (Periodically Rotated Overlapping ParallEL Lines with Enhanced Reconstruction) MRI acquisitions, which are popular for their robustness to motion artifacts. Our method operates in a few minutes on a single GPU, and to our knowledge is the first to correct for chemical shift in gradient echo PROPELLER MRI reconstruction without additional measurements or pretraining data.
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack Detection
Nov 22, 2023Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset. The source code is available at https://github.com/redwankarimsony/WeightPerturbation-MSU.