 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023
Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
Temporal-Aware Refinement for Video-based Human Pose and Shape Recovery
Nov 16, 2023
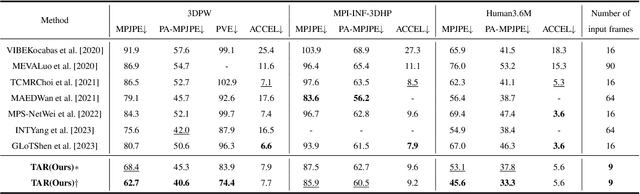
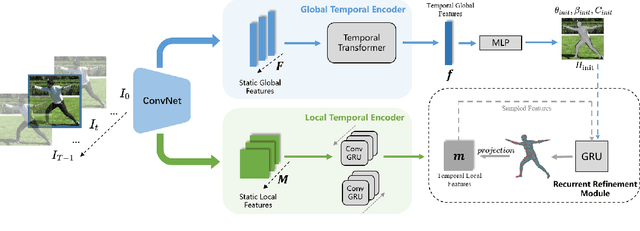
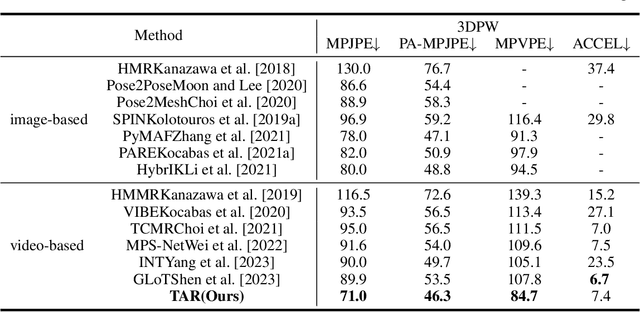
Though significant progress in human pose and shape recovery from monocular RGB images has been made in recent years, obtaining 3D human motion with high accuracy and temporal consistency from videos remains challenging. Existing video-based methods tend to reconstruct human motion from global image features, which lack detailed representation capability and limit the reconstruction accuracy. In this paper, we propose a Temporal-Aware Refining Network (TAR), to synchronously explore temporal-aware global and local image features for accurate pose and shape recovery. First, a global transformer encoder is introduced to obtain temporal global features from static feature sequences. Second, a bidirectional ConvGRU network takes the sequence of high-resolution feature maps as input, and outputs temporal local feature maps that maintain high resolution and capture the local motion of the human body. Finally, a recurrent refinement module iteratively updates estimated SMPL parameters by leveraging both global and local temporal information to achieve accurate and smooth results. Extensive experiments demonstrate that our TAR obtains more accurate results than previous state-of-the-art methods on popular benchmarks, i.e., 3DPW, MPI-INF-3DHP, and Human3.6M.
Hyperspectral Image Fusion via Logarithmic Low-rank Tensor Ring Decomposition
Oct 16, 2023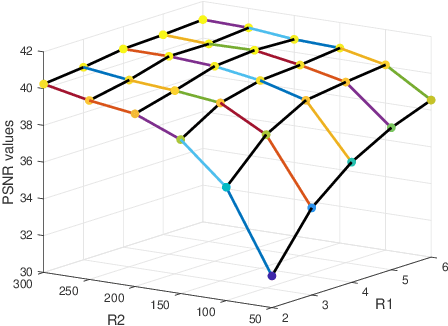
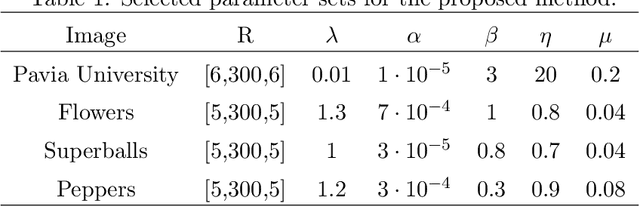
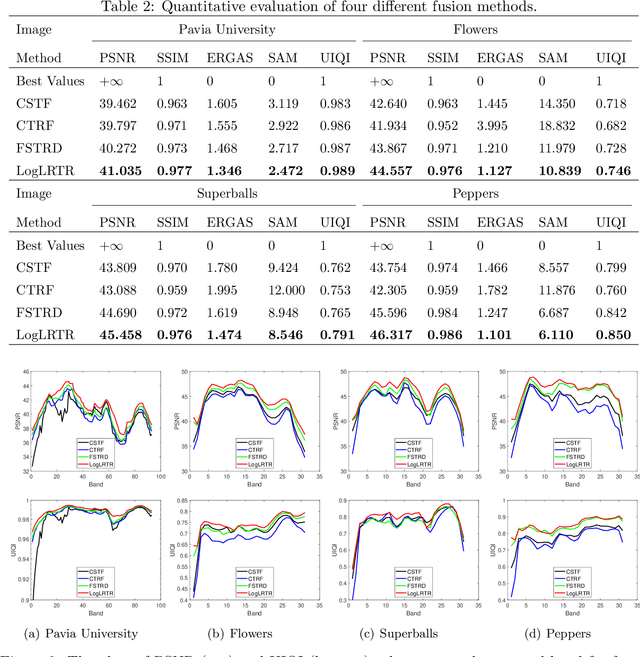

Integrating a low-spatial-resolution hyperspectral image (LR-HSI) with a high-spatial-resolution multispectral image (HR-MSI) is recognized as a valid method for acquiring HR-HSI. Among the current fusion approaches, the tensor ring (TR) decomposition-based method has received growing attention owing to its superior performance on preserving the spatial-spectral correlation. Furthermore, the low-rank property in some TR factors has been exploited via the matrix nuclear norm regularization along mode-2. On the other hand, the tensor nuclear norm (TNN)-based approaches have recently demonstrated to be more efficient on keeping high-dimensional low-rank structures in tensor recovery. Here, we study the low-rankness of TR factors from the TNN perspective and consider the mode-2 logarithmic TNN (LTNN) on each TR factor. A novel fusion model is proposed by incorporating this LTNN regularization and the weighted total variation which is to promote the continuity of HR-HSI in the spatial-spectral domain. Meanwhile, we have devised a highly efficient proximal alternating minimization algorithm to solve the proposed model. The experimental results indicate that our method improves the visual quality and exceeds the existing state-of-the-art fusion approaches with respect to various quantitative metrics.
Adversarial Reweighting Guided by Wasserstein Distance for Bias Mitigation
Nov 21, 2023The unequal representation of different groups in a sample population can lead to discrimination of minority groups when machine learning models make automated decisions. To address these issues, fairness-aware machine learning jointly optimizes two (or more) metrics aiming at predictive effectiveness and low unfairness. However, the inherent under-representation of minorities in the data makes the disparate treatment of subpopulations less noticeable and difficult to deal with during learning. In this paper, we propose a novel adversarial reweighting method to address such \emph{representation bias}. To balance the data distribution between the majority and the minority groups, our approach deemphasizes samples from the majority group. To minimize empirical risk, our method prefers samples from the majority group that are close to the minority group as evaluated by the Wasserstein distance. Our theoretical analysis shows the effectiveness of our adversarial reweighting approach. Experiments demonstrate that our approach mitigates bias without sacrificing classification accuracy, outperforming related state-of-the-art methods on image and tabular benchmark datasets.
On the Out-of-Distribution Coverage of Combining Split Conformal Prediction and Bayesian Deep Learning
Nov 21, 2023Bayesian deep learning and conformal prediction are two methods that have been used to convey uncertainty and increase safety in machine learning systems. We focus on combining Bayesian deep learning with split conformal prediction and how this combination effects out-of-distribution coverage; particularly in the case of multiclass image classification. We suggest that if the model is generally underconfident on the calibration set, then the resultant conformal sets may exhibit worse out-of-distribution coverage compared to simple predictive credible sets. Conversely, if the model is overconfident on the calibration set, the use of conformal prediction may improve out-of-distribution coverage. We evaluate prediction sets as a result of combining split conformal methods and neural networks trained with (i) stochastic gradient descent, (ii) deep ensembles, and (iii) mean-field variational inference. Our results suggest that combining Bayesian deep learning models with split conformal prediction can, in some cases, cause unintended consequences such as reducing out-of-distribution coverage.
HiPose: Hierarchical Binary Surface Encoding and Correspondence Pruning for RGB-D 6DoF Object Pose Estimation
Nov 21, 2023In this work, we present a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. While many existing data-driven methods achieve impressive performance, they tend to be time-consuming due to their reliance on rendering-based refinement approaches. To circumvent this limitation, we present HiPose, which establishes 3D-3D correspondences in a coarse-to-fine manner with a hierarchical binary surface encoding. Unlike previous dense-correspondence methods, we estimate the correspondence surface by employing point-to-surface matching and iteratively constricting the surface until it becomes a correspondence point while gradually removing outliers. Extensive experiments on public benchmarks LM-O, YCB-V, and T-Less demonstrate that our method surpasses all refinement-free methods and is even on par with expensive refinement-based approaches. Crucially, our approach is computationally efficient and enables real-time critical applications with high accuracy requirements. Code and models will be released.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 21, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Generative Machine Learning for Multivariate Equity Returns
Nov 21, 2023The use of machine learning to generate synthetic data has grown in popularity with the proliferation of text-to-image models and especially large language models. The core methodology these models use is to learn the distribution of the underlying data, similar to the classical methods common in finance of fitting statistical models to data. In this work, we explore the efficacy of using modern machine learning methods, specifically conditional importance weighted autoencoders (a variant of variational autoencoders) and conditional normalizing flows, for the task of modeling the returns of equities. The main problem we work to address is modeling the joint distribution of all the members of the S&P 500, or, in other words, learning a 500-dimensional joint distribution. We show that this generative model has a broad range of applications in finance, including generating realistic synthetic data, volatility and correlation estimation, risk analysis (e.g., value at risk, or VaR, of portfolios), and portfolio optimization.
Image Classification using Combination of Topological Features and Neural Networks
Nov 10, 2023In this work we use the persistent homology method, a technique in topological data analysis (TDA), to extract essential topological features from the data space and combine them with deep learning features for classification tasks. In TDA, the concepts of complexes and filtration are building blocks. Firstly, a filtration is constructed from some complex. Then, persistent homology classes are computed, and their evolution along the filtration is visualized through the persistence diagram. Additionally, we applied vectorization techniques to the persistence diagram to make this topological information compatible with machine learning algorithms. This was carried out with the aim of classifying images from multiple classes in the MNIST dataset. Our approach inserts topological features into deep learning approaches composed by single and two-streams neural networks architectures based on a multi-layer perceptron (MLP) and a convolutional neral network (CNN) taylored for multi-class classification in the MNIST dataset. In our analysis, we evaluated the obtained results and compared them with the outcomes achieved through the baselines that are available in the TensorFlow library. The main conclusion is that topological information may increase neural network accuracy in multi-class classification tasks with the price of computational complexity of persistent homology calculation. Up to the best of our knowledge, it is the first work that combines deep learning features and the combination of topological features for multi-class classification tasks.
Physics-guided Noise Neural Proxy for Low-light Raw Image Denoising
Oct 13, 2023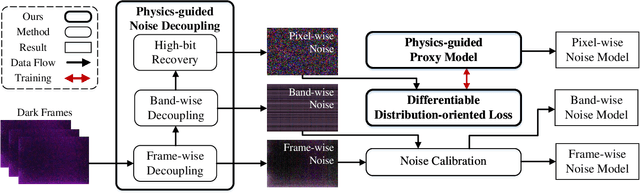
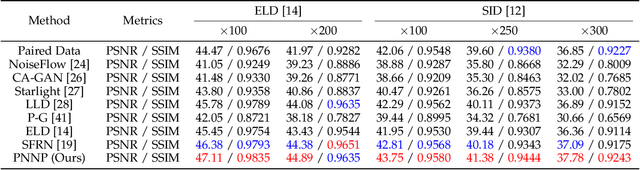
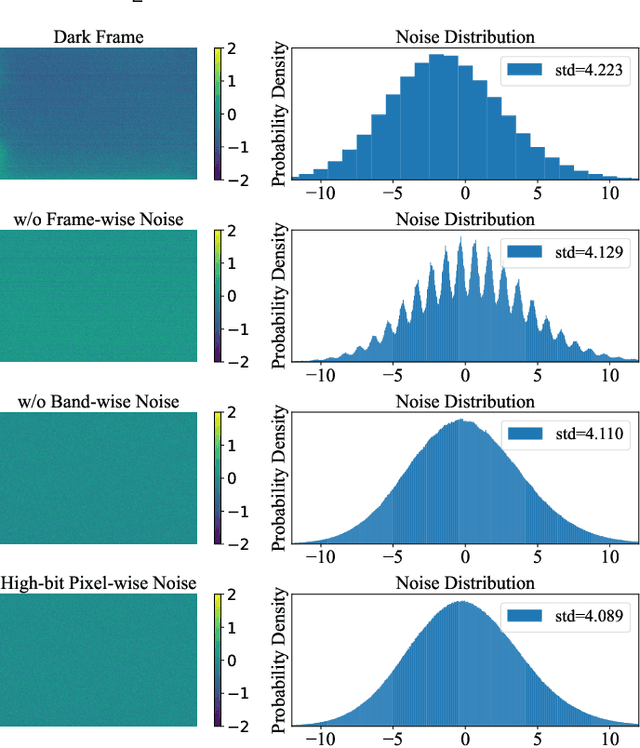
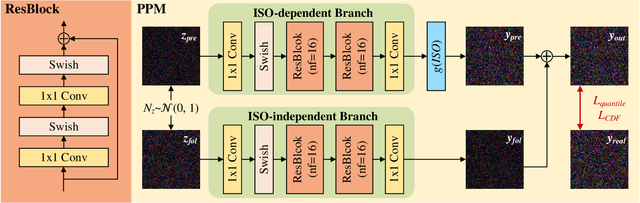
Low-light raw image denoising plays a crucial role in mobile photography, and learning-based methods have become the mainstream approach. Training the learning-based methods with synthetic data emerges as an efficient and practical alternative to paired real data. However, the quality of synthetic data is inherently limited by the low accuracy of the noise model, which decreases the performance of low-light raw image denoising. In this paper, we develop a novel framework for accurate noise modeling that learns a physics-guided noise neural proxy (PNNP) from dark frames. PNNP integrates three efficient techniques: physics-guided noise decoupling (PND), physics-guided proxy model (PPM), and differentiable distribution-oriented loss (DDL). The PND decouples the dark frame into different components and handles different levels of noise in a flexible manner, which reduces the complexity of the noise neural proxy. The PPM incorporates physical priors to effectively constrain the generated noise, which promotes the accuracy of the noise neural proxy. The DDL provides explicit and reliable supervision for noise modeling, which promotes the precision of the noise neural proxy. Extensive experiments on public low-light raw image denoising datasets and real low-light imaging scenarios demonstrate the superior performance of our PNNP framework.