 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Bidirectional Variational Autoencoder for Image Domain Translation of Dotted Arabic Expiration
Oct 21, 2023
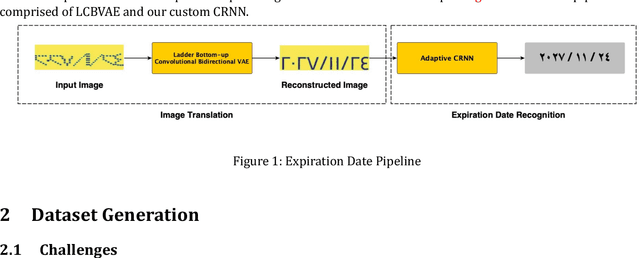
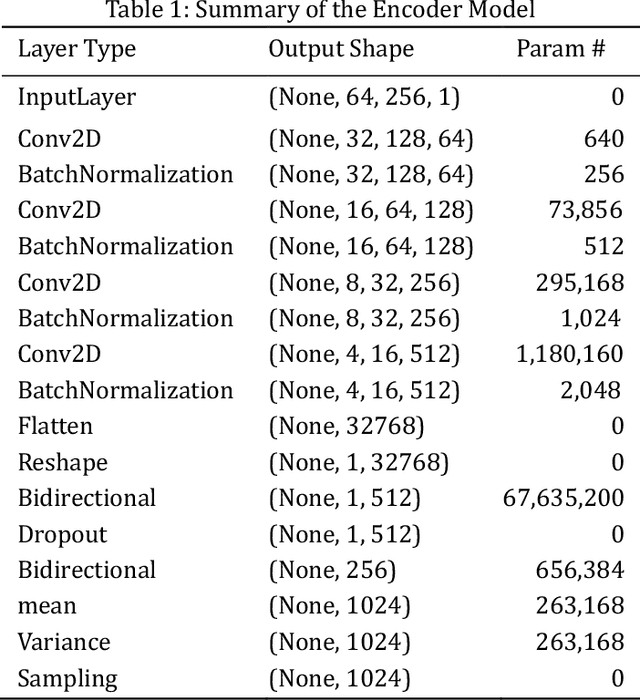
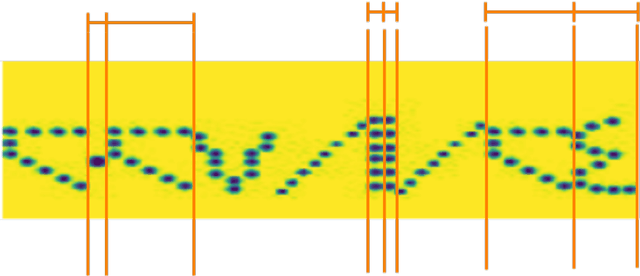
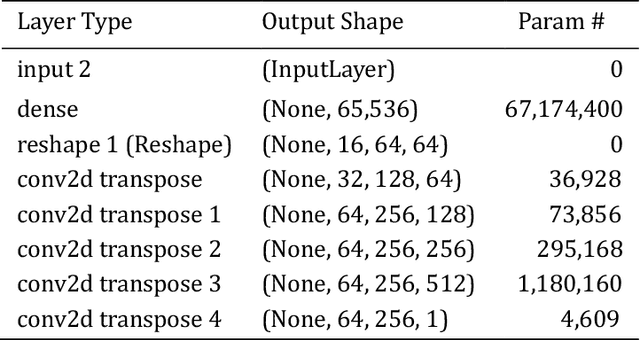
THIS paper proposes an approach of Ladder Bottom-up Convolutional Bidirectional Variational Autoencoder (LCBVAE) architecture for the encoder and decoder, which is trained on the image translation of the dotted Arabic expiration dates by reconstructing the Arabic dotted expiration dates into filled-in expiration dates. We employed a customized and adapted version of Convolutional Recurrent Neural Network CRNN model to meet our specific requirements and enhance its performance in our context, and then trained the custom CRNN model with the filled-in images from the year of 2019 to 2027 to extract the expiration dates and assess the model performance of LCBVAE on the expiration date recognition. The pipeline of (LCBVAE+CRNN) can be then integrated into an automated sorting systems for extracting the expiry dates and sorting the products accordingly during the manufacture stage. Additionally, it can overcome the manual entry of expiration dates that can be time-consuming and inefficient at the merchants. Due to the lack of the availability of the dotted Arabic expiration date images, we created an Arabic dot-matrix True Type Font (TTF) for the generation of the synthetic images. We trained the model with unrealistic synthetic dates of 59902 images and performed the testing on a realistic synthetic date of 3287 images from the year of 2019 to 2027, represented as yyyy/mm/dd. In our study, we demonstrated the significance of latent bottleneck layer with improving the generalization when the size is increased up to 1024 in downstream transfer learning tasks as for image translation. The proposed approach achieved an accuracy of 97% on the image translation with using the LCBVAE architecture that can be generalized for any downstream learning tasks as for image translation and reconstruction.
Generalizing Medical Image Representations via Quaternion Wavelet Networks
Oct 16, 2023Neural network generalizability is becoming a broad research field due to the increasing availability of datasets from different sources and for various tasks. This issue is even wider when processing medical data, where a lack of methodological standards causes large variations being provided by different imaging centers or acquired with various devices and cofactors. To overcome these limitations, we introduce a novel, generalizable, data- and task-agnostic framework able to extract salient features from medical images. The proposed quaternion wavelet network (QUAVE) can be easily integrated with any pre-existing medical image analysis or synthesis task, and it can be involved with real, quaternion, or hypercomplex-valued models, generalizing their adoption to single-channel data. QUAVE first extracts different sub-bands through the quaternion wavelet transform, resulting in both low-frequency/approximation bands and high-frequency/fine-grained features. Then, it weighs the most representative set of sub-bands to be involved as input to any other neural model for image processing, replacing standard data samples. We conduct an extensive experimental evaluation comprising different datasets, diverse image analysis, and synthesis tasks including reconstruction, segmentation, and modality translation. We also evaluate QUAVE in combination with both real and quaternion-valued models. Results demonstrate the effectiveness and the generalizability of the proposed framework that improves network performance while being flexible to be adopted in manifold scenarios.
Shadow: A Novel Loss Function for Efficient Training in Siamese Networks
Nov 23, 2023Despite significant recent advances in similarity detection tasks, existing approaches pose substantial challenges under memory constraints. One of the primary reasons for this is the use of computationally expensive metric learning loss functions such as Triplet Loss in Siamese networks. In this paper, we present a novel loss function called Shadow Loss that compresses the dimensions of an embedding space during loss calculation without loss of performance. The distance between the projections of the embeddings is learned from inputs on a compact projection space where distances directly correspond to a measure of class similarity. Projecting on a lower-dimension projection space, our loss function converges faster, and the resulting classified image clusters have higher inter-class and smaller intra-class distances. Shadow Loss not only reduces embedding dimensions favoring memory constraint devices but also consistently performs better than the state-of-the-art Triplet Margin Loss by an accuracy of 5\%-10\% across diverse datasets. The proposed loss function is also model agnostic, upholding its performance across several tested models. Its effectiveness and robustness across balanced, imbalanced, medical, and non-medical image datasets suggests that it is not specific to a particular model or dataset but demonstrates superior performance consistently while using less memory and computation.
Point2RBox: Combine Knowledge from Synthetic Visual Patterns for End-to-end Oriented Object Detection with Single Point Supervision
Nov 23, 2023With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning rotated box (RBox) from the horizontal box (HBox) has attracted more and more attention. In this paper, we explore a more challenging yet label-efficient setting, namely single point-supervised OOD, and present our approach called Point2RBox. Specifically, we propose to leverage two principles: 1) Synthetic pattern knowledge combination: By sampling around each labelled point on the image, we transfer the object feature to synthetic visual patterns with the known bounding box to provide the knowledge for box regression. 2) Transform self-supervision: With a transformed input image (e.g. scaled/rotated), the output RBoxes are trained to follow the same transformation so that the network can perceive the relative size/rotation between objects. The detector is further enhanced by a few devised techniques to cope with peripheral issues, e.g. the anchor/layer assignment as the size of the object is not available in our point supervision setting. To our best knowledge, Point2RBox is the first end-to-end solution for point-supervised OOD. In particular, our method uses a lightweight paradigm, yet it achieves a competitive performance among point-supervised alternatives, 41.05%/27.62%/80.01% on DOTA/DIOR/HRSC datasets.
Lesion Search with Self-supervised Learning
Nov 18, 2023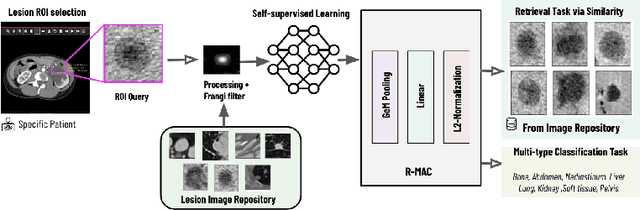
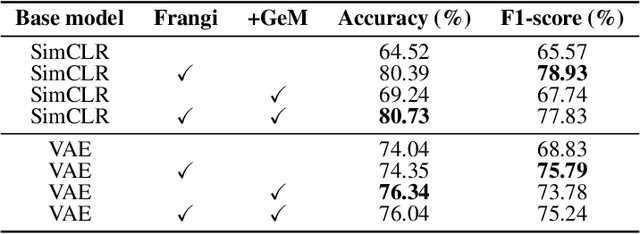
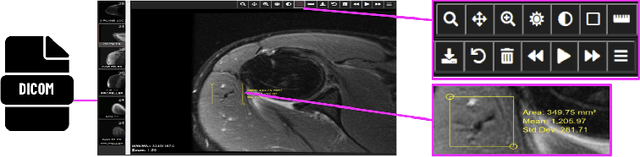
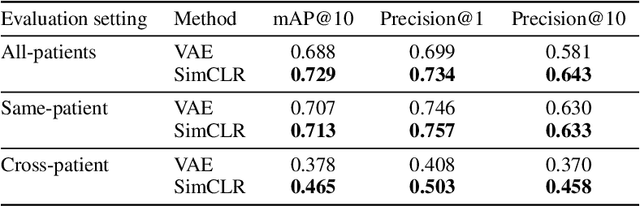
Content-based image retrieval (CBIR) with self-supervised learning (SSL) accelerates clinicians' interpretation of similar images without manual annotations. We develop a CBIR from the contrastive learning SimCLR and incorporate a generalized-mean (GeM) pooling followed by L2 normalization to classify lesion types and retrieve similar images before clinicians' analysis. Results have shown improved performance. We additionally build an open-source application for image analysis and retrieval. The application is easy to integrate, relieving manual efforts and suggesting the potential to support clinicians' everyday activities.
SenseAI: Real-Time Inpainting for Electron Microscopy
Nov 25, 2023Despite their proven success and broad applicability to Electron Microscopy (EM) data, joint dictionary-learning and sparse-coding based inpainting algorithms have so far remained impractical for real-time usage with an Electron Microscope. For many EM applications, the reconstruction time for a single frame is orders of magnitude longer than the data acquisition time, making it impossible to perform exclusively subsampled acquisition. This limitation has led to the development of SenseAI, a C++/CUDA library capable of extremely efficient dictionary-based inpainting. SenseAI provides N-dimensional dictionary learning, live reconstructions, dictionary transfer and visualization, as well as real-time plotting of statistics, parameters, and image quality metrics.
Weakly-Supervised 3D Reconstruction of Clothed Humans via Normal Maps
Nov 27, 2023We present a novel deep learning-based approach to the 3D reconstruction of clothed humans using weak supervision via 2D normal maps. Given a single RGB image or multiview images, our network infers a signed distance function (SDF) discretized on a tetrahedral mesh surrounding the body in a rest pose. Subsequently, inferred pose and camera parameters are used to generate a normal map from the SDF. A key aspect of our approach is the use of Marching Tetrahedra to (uniquely) compute a triangulated surface from the SDF on the tetrahedral mesh, facilitating straightforward differentiation (and thus backpropagation). Thus, given only ground truth normal maps (with no volumetric information ground truth information), we can train the network to produce SDF values from corresponding RGB images. Optionally, an additional multiview loss leads to improved results. We demonstrate the efficacy of our approach for both network inference and 3D reconstruction.
Tell2Design: A Dataset for Language-Guided Floor Plan Generation
Nov 27, 2023We consider the task of generating designs directly from natural language descriptions, and consider floor plan generation as the initial research area. Language conditional generative models have recently been very successful in generating high-quality artistic images. However, designs must satisfy different constraints that are not present in generating artistic images, particularly spatial and relational constraints. We make multiple contributions to initiate research on this task. First, we introduce a novel dataset, \textit{Tell2Design} (T2D), which contains more than $80k$ floor plan designs associated with natural language instructions. Second, we propose a Sequence-to-Sequence model that can serve as a strong baseline for future research. Third, we benchmark this task with several text-conditional image generation models. We conclude by conducting human evaluations on the generated samples and providing an analysis of human performance. We hope our contributions will propel the research on language-guided design generation forward.
Model-based reconstructions for quantitative imaging in photoacoustic tomography
Nov 27, 2023The reconstruction task in photoacoustic tomography can vary a lot depending on measured targets, geometry, and especially the quantity we want to recover. Specifically, as the signal is generated due to the coupling of light and sound by the photoacoustic effect, we have the possibility to recover acoustic as well as optical tissue parameters. This is referred to as quantitative imaging, i.e, correct recovery of physical parameters and not just a qualitative image. In this chapter, we aim to give an overview on established reconstruction techniques in photoacoustic tomography. We start with modelling of the optical and acoustic phenomena, necessary for a reliable recovery of quantitative values. Furthermore, we give an overview of approaches for the tomographic reconstruction problem with an emphasis on the recovery of quantitative values, from direct and fast analytic approaches to computationally involved optimisation based techniques and recent data-driven approaches.
Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.