 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Addressing Weak Decision Boundaries in Image Classification by Leveraging Web Search and Generative Models
Oct 30, 2023
Machine learning (ML) technologies are known to be riddled with ethical and operational problems, however, we are witnessing an increasing thrust by businesses to deploy them in sensitive applications. One major issue among many is that ML models do not perform equally well for underrepresented groups. This puts vulnerable populations in an even disadvantaged and unfavorable position. We propose an approach that leverages the power of web search and generative models to alleviate some of the shortcomings of discriminative models. We demonstrate our method on an image classification problem using ImageNet's People Subtree subset, and show that it is effective in enhancing robustness and mitigating bias in certain classes that represent vulnerable populations (e.g., female doctor of color). Our new method is able to (1) identify weak decision boundaries for such classes; (2) construct search queries for Google as well as text for generating images through DALL-E 2 and Stable Diffusion; and (3) show how these newly captured training samples could alleviate population bias issue. While still improving the model's overall performance considerably, we achieve a significant reduction (77.30\%) in the model's gender accuracy disparity. In addition to these improvements, we observed a notable enhancement in the classifier's decision boundary, as it is characterized by fewer weakspots and an increased separation between classes. Although we showcase our method on vulnerable populations in this study, the proposed technique is extendable to a wide range of problems and domains.
Are foundation models efficient for medical image segmentation?
Nov 08, 2023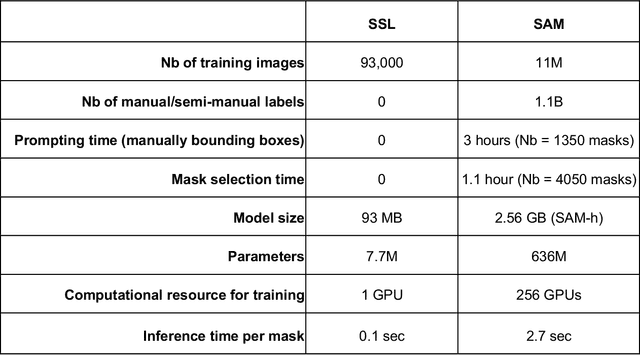

Foundation models are experiencing a surge in popularity. The Segment Anything model (SAM) asserts an ability to segment a wide spectrum of objects but required supervised training at unprecedented scale. We compared SAM's performance (against clinical ground truth) and resources (labeling time, compute) to a modality-specific, label-free self-supervised learning (SSL) method on 25 measurements for 100 cardiac ultrasounds. SAM performed poorly and required significantly more labeling and computing resources, demonstrating worse efficiency than SSL.
GeoTop: Advancing Image Classification with Geometric-Topological Analysis
Nov 08, 2023In this study, we explore the application of Topological Data Analysis (TDA) and Lipschitz-Killing Curvatures (LKCs) as powerful tools for feature extraction and classification in the context of biomedical multiomics problems. TDA allows us to capture topological features and patterns within complex datasets, while LKCs provide essential geometric insights. We investigate the potential of combining both methods to improve classification accuracy. Using a dataset of biomedical images, we demonstrate that TDA and LKCs can effectively extract topological and geometrical features, respectively. The combination of these features results in enhanced classification performance compared to using each method individually. This approach offers promising results and has the potential to advance our understanding of complex biological processes in various biomedical applications. Our findings highlight the value of integrating topological and geometrical information in biomedical data analysis. As we continue to delve into the intricacies of multiomics problems, the fusion of these insights holds great promise for unraveling the underlying biological complexities.
Automatic Report Generation for Histopathology images using pre-trained Vision Transformers
Nov 10, 2023Deep learning for histopathology has been successfully used for disease classification, image segmentation and more. However, combining image and text modalities using current state-of-the-art methods has been a challenge due to the high resolution of histopathology images. Automatic report generation for histopathology images is one such challenge. In this work, we show that using an existing pre-trained Vision Transformer in a two-step process of first using it to encode 4096x4096 sized patches of the Whole Slide Image (WSI) and then using it as the encoder and an LSTM decoder for report generation, we can build a fairly performant and portable report generation mechanism that takes into account the whole of the high resolution image, instead of just the patches. We are also able to use representations from an existing powerful pre-trained hierarchical vision transformer and show its usefulness in not just zero shot classification but also for report generation.
Masked Autoencoders Are Robust Neural Architecture Search Learners
Nov 20, 2023Neural Architecture Search (NAS) currently relies heavily on labeled data, which is both expensive and time-consuming to acquire. In this paper, we propose a novel NAS framework based on Masked Autoencoders (MAE) that eliminates the need for labeled data during the search process. By replacing the supervised learning objective with an image reconstruction task, our approach enables the robust discovery of network architectures without compromising performance and generalization ability. Additionally, we address the problem of performance collapse encountered in the widely-used Differentiable Architecture Search (DARTS) method in the unsupervised paradigm by introducing a multi-scale decoder. Through extensive experiments conducted on various search spaces and datasets, we demonstrate the effectiveness and robustness of the proposed method, providing empirical evidence of its superiority over baseline approaches.
Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation
Oct 12, 2023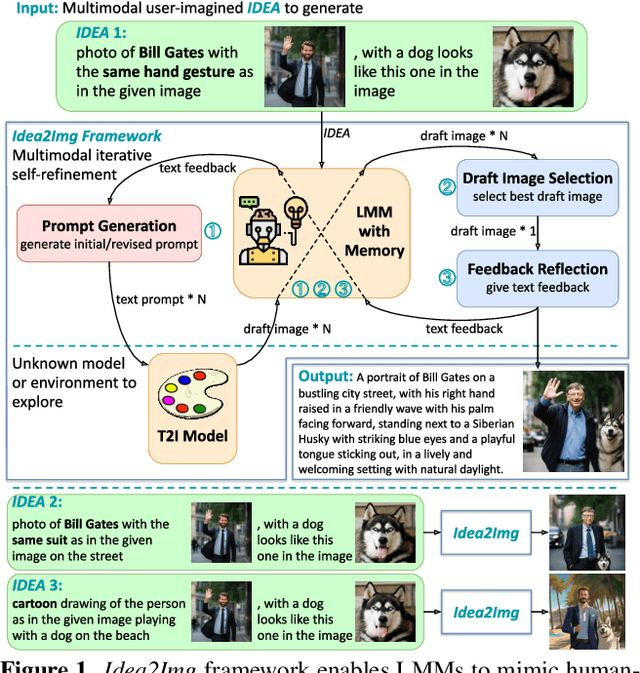


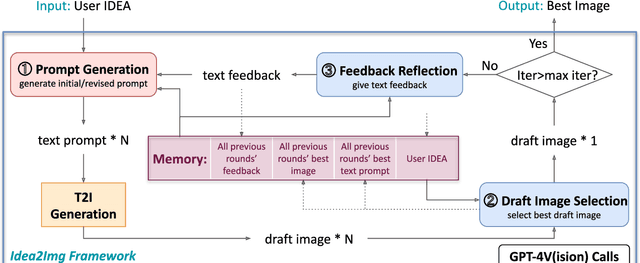
We introduce ``Idea to Image,'' a system that enables multimodal iterative self-refinement with GPT-4V(ision) for automatic image design and generation. Humans can quickly identify the characteristics of different text-to-image (T2I) models via iterative explorations. This enables them to efficiently convert their high-level generation ideas into effective T2I prompts that can produce good images. We investigate if systems based on large multimodal models (LMMs) can develop analogous multimodal self-refinement abilities that enable exploring unknown models or environments via self-refining tries. Idea2Img cyclically generates revised T2I prompts to synthesize draft images, and provides directional feedback for prompt revision, both conditioned on its memory of the probed T2I model's characteristics. The iterative self-refinement brings Idea2Img various advantages over vanilla T2I models. Notably, Idea2Img can process input ideas with interleaved image-text sequences, follow ideas with design instructions, and generate images of better semantic and visual qualities. The user preference study validates the efficacy of multimodal iterative self-refinement on automatic image design and generation.
Image Denoising via Style Disentanglement
Sep 26, 2023
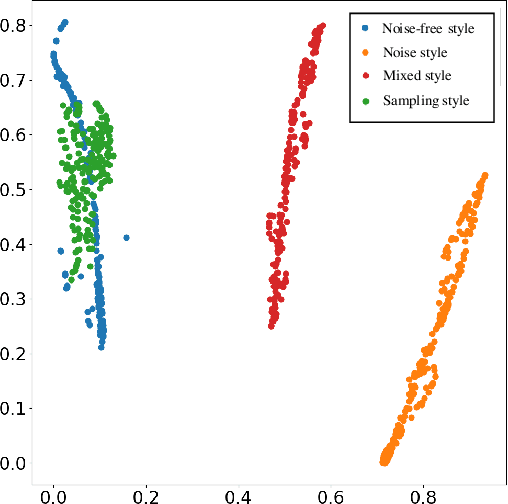

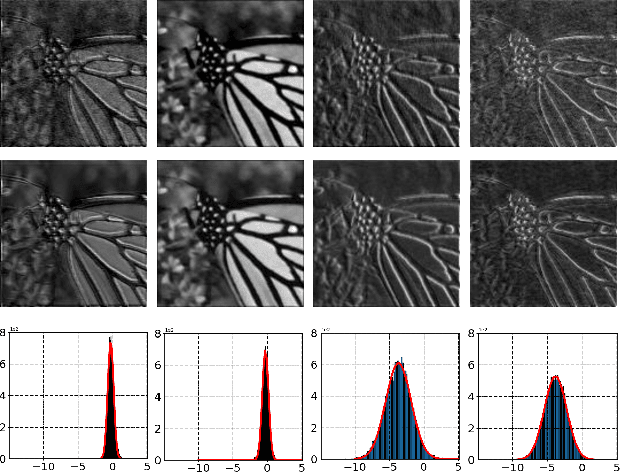
Image denoising is a fundamental task in low-level computer vision. While recent deep learning-based image denoising methods have achieved impressive performance, they are black-box models and the underlying denoising principle remains unclear. In this paper, we propose a novel approach to image denoising that offers both clear denoising mechanism and good performance. We view noise as a type of image style and remove it by incorporating noise-free styles derived from clean images. To achieve this, we design novel losses and network modules to extract noisy styles from noisy images and noise-free styles from clean images. The noise-free style induces low-response activations for noise features and high-response activations for content features in the feature space. This leads to the separation of clean contents from noise, effectively denoising the image. Unlike disentanglement-based image editing tasks that edit semantic-level attributes using styles, our main contribution lies in editing pixel-level attributes through global noise-free styles. We conduct extensive experiments on synthetic noise removal and real-world image denoising datasets (SIDD and DND), demonstrating the effectiveness of our method in terms of both PSNR and SSIM metrics. Moreover, we experimentally validate that our method offers good interpretability.
LuminanceL1Loss: A loss function which measures percieved brightness and colour differences
Nov 08, 2023
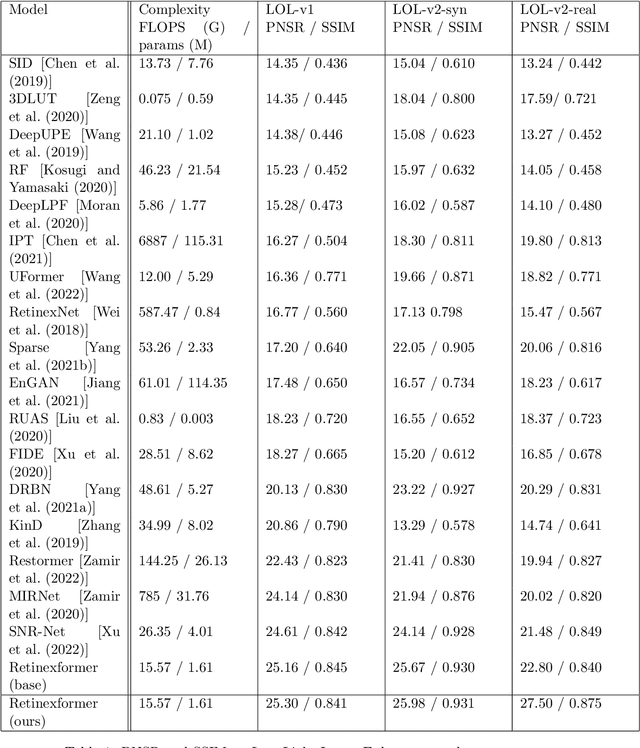
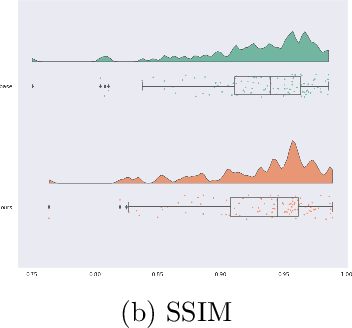
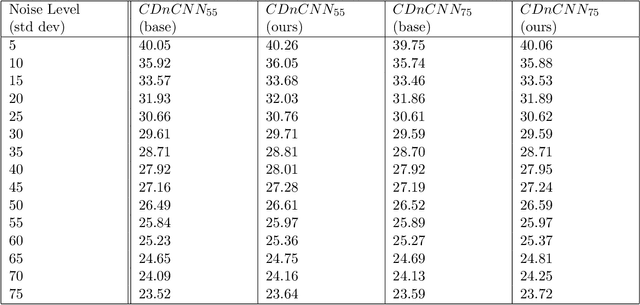
We introduce LuminanceL1Loss, a novel loss function designed to enhance the performance of image restoration tasks. We demonstrate its superiority over MSE when applied to the Retinexformer, BUIFD and DnCNN architectures. Our proposed LuminanceL1Loss leverages a unique approach by transforming images into grayscale and subsequently computing the MSE loss for both grayscale and color channels. Experimental results demonstrate that this innovative loss function consistently outperforms traditional methods, showcasing its potential in image denoising and other related tasks in image reconstruction. It demonstrates gains up to 4.7dB. The results presented in this study highlight the efficacy of LuminanceL1Loss for various image restoration tasks.
What do larger image classifiers memorise?
Oct 09, 2023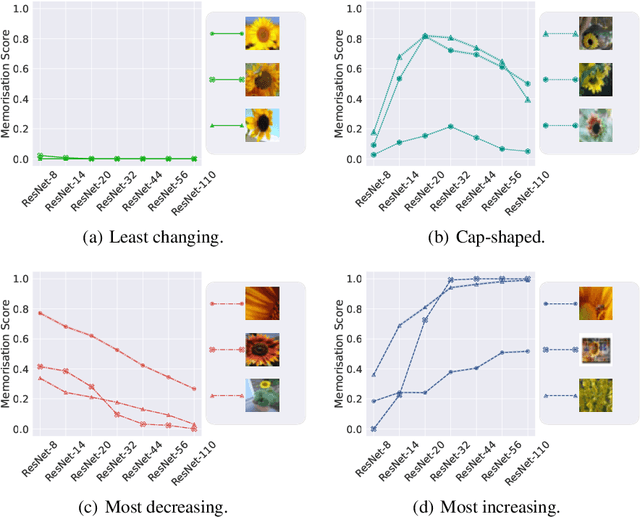

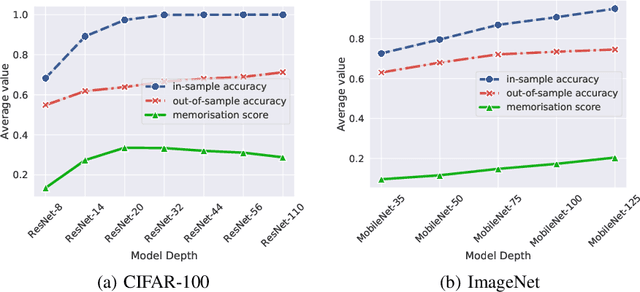
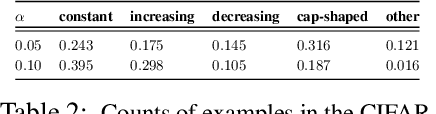
The success of modern neural networks has prompted study of the connection between memorisation and generalisation: overparameterised models generalise well, despite being able to perfectly fit (memorise) completely random labels. To carefully study this issue, Feldman proposed a metric to quantify the degree of memorisation of individual training examples, and empirically computed the corresponding memorisation profile of a ResNet on image classification bench-marks. While an exciting first glimpse into what real-world models memorise, this leaves open a fundamental question: do larger neural models memorise more? We present a comprehensive empirical analysis of this question on image classification benchmarks. We find that training examples exhibit an unexpectedly diverse set of memorisation trajectories across model sizes: most samples experience decreased memorisation under larger models, while the rest exhibit cap-shaped or increasing memorisation. We show that various proxies for the Feldman memorization score fail to capture these fundamental trends. Lastly, we find that knowledge distillation, an effective and popular model compression technique, tends to inhibit memorisation, while also improving generalisation. Specifically, memorisation is mostly inhibited on examples with increasing memorisation trajectories, thus pointing at how distillation improves generalisation.
Enhancing Transformer-Based Segmentation for Breast Cancer Diagnosis using Auto-Augmentation and Search Optimisation Techniques
Nov 18, 2023
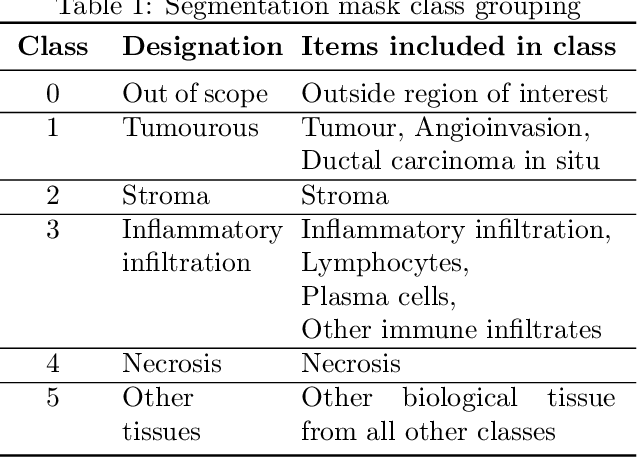


Breast cancer remains a critical global health challenge, necessitating early and accurate detection for effective treatment. This paper introduces a methodology that combines automated image augmentation selection (RandAugment) with search optimisation strategies (Tree-based Parzen Estimator) to identify optimal values for the number of image augmentations and the magnitude of their associated augmentation parameters, leading to enhanced segmentation performance. We empirically validate our approach on breast cancer histology slides, focusing on the segmentation of cancer cells. A comparative analysis of state-of-the-art transformer-based segmentation models is conducted, including SegFormer, PoolFormer, and MaskFormer models, to establish a comprehensive baseline, before applying the augmentation methodology. Our results show that the proposed methodology leads to segmentation models that are more resilient to variations in histology slides whilst maintaining high levels of segmentation performance, and show improved segmentation of the tumour class when compared to previous research. Our best result after applying the augmentations is a Dice Score of 84.08 and an IoU score of 72.54 when segmenting the tumour class. The primary contribution of this paper is the development of a methodology that enhances segmentation performance while ensuring model robustness to data variances. This has significant implications for medical practitioners, enabling the development of more effective machine learning models for clinical applications to identify breast cancer cells from histology slides. Furthermore, the codebase accompanying this research will be released upon publication. This will facilitate further research and application development based on our methodology, thereby amplifying its impact.