 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 23, 2023


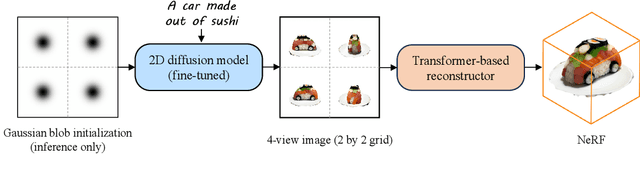
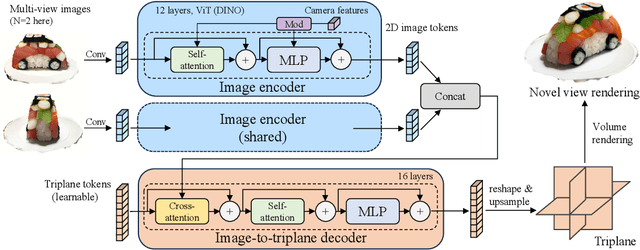
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate diverse 3D assets of high visual quality within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
Addressing Weak Decision Boundaries in Image Classification by Leveraging Web Search and Generative Models
Oct 30, 2023Machine learning (ML) technologies are known to be riddled with ethical and operational problems, however, we are witnessing an increasing thrust by businesses to deploy them in sensitive applications. One major issue among many is that ML models do not perform equally well for underrepresented groups. This puts vulnerable populations in an even disadvantaged and unfavorable position. We propose an approach that leverages the power of web search and generative models to alleviate some of the shortcomings of discriminative models. We demonstrate our method on an image classification problem using ImageNet's People Subtree subset, and show that it is effective in enhancing robustness and mitigating bias in certain classes that represent vulnerable populations (e.g., female doctor of color). Our new method is able to (1) identify weak decision boundaries for such classes; (2) construct search queries for Google as well as text for generating images through DALL-E 2 and Stable Diffusion; and (3) show how these newly captured training samples could alleviate population bias issue. While still improving the model's overall performance considerably, we achieve a significant reduction (77.30\%) in the model's gender accuracy disparity. In addition to these improvements, we observed a notable enhancement in the classifier's decision boundary, as it is characterized by fewer weakspots and an increased separation between classes. Although we showcase our method on vulnerable populations in this study, the proposed technique is extendable to a wide range of problems and domains.
Frequency-Aware Re-Parameterization for Over-Fitting Based Image Compression
Oct 12, 2023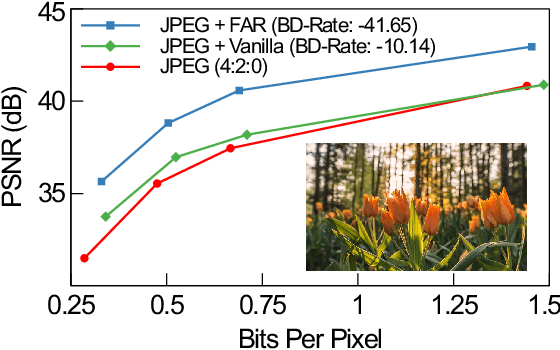
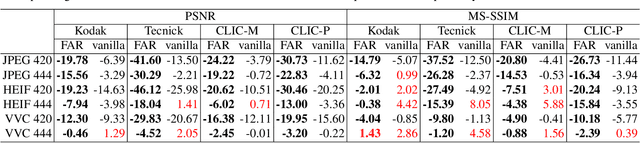

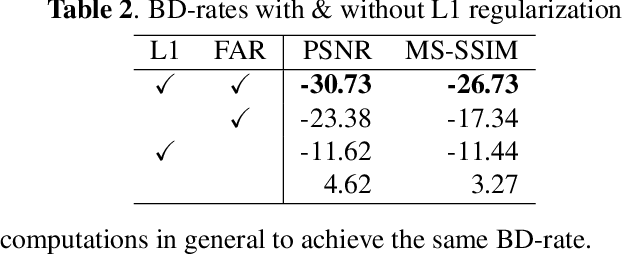
Over-fitting-based image compression requires weights compactness for compression and fast convergence for practical use, posing challenges for deep convolutional neural networks (CNNs) based methods. This paper presents a simple re-parameterization method to train CNNs with reduced weights storage and accelerated convergence. The convolution kernels are re-parameterized as a weighted sum of discrete cosine transform (DCT) kernels enabling direct optimization in the frequency domain. Combined with L1 regularization, the proposed method surpasses vanilla convolutions by achieving a significantly improved rate-distortion with low computational cost. The proposed method is verified with extensive experiments of over-fitting-based image restoration on various datasets, achieving up to -46.12% BD-rate on top of HEIF with only 200 iterations.
Medical Image Segmentation via Sparse Coding Decoder
Oct 17, 2023Transformers have achieved significant success in medical image segmentation, owing to its capability to capture long-range dependencies. Previous works incorporate convolutional layers into the encoder module of transformers, thereby enhancing their ability to learn local relationships among pixels. However, transformers may suffer from limited generalization capabilities and reduced robustness, attributed to the insufficient spatial recovery ability of their decoders. To address this issue, A convolution sparse vector coding based decoder is proposed , namely CAScaded multi-layer Convolutional Sparse vector Coding DEcoder (CASCSCDE), which represents features extracted by the encoder using sparse vectors. To prove the effectiveness of our CASCSCDE, The widely-used TransUNet model is chosen for the demonstration purpose, and the CASCSCDE is incorporated with TransUNet to establish the TransCASCSCDE architecture. Our experiments demonstrate that TransUNet with CASCSCDE significantly enhances performance on the Synapse benchmark, obtaining up to 3.15\% and 1.16\% improvements in DICE and mIoU scores, respectively. CASCSCDE opens new ways for constructing decoders based on convolutional sparse vector coding.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
Alpha Zero for Physics: Application of Symbolic Regression with Alpha Zero to find the analytical methods in physics
Nov 21, 2023Machine learning with neural networks is now becoming a more and more powerful tool for various tasks, such as natural language processing, image recognition, winning the game, and even for the issues of physics. Although there are many studies on the application of machine learning to numerical calculation and the assistance of experimental detection, the methods of applying machine learning to find the analytical method are poorly studied. In this paper, we propose the frameworks of developing analytical methods in physics by using the symbolic regression with the Alpha Zero algorithm, that is Alpha Zero for physics (AZfP). As a demonstration, we show that AZfP can derive the high-frequency expansion in the Floquet systems. AZfP may have the possibility of developing a new theoretical framework in physics.
Unsupervised Multimodal Surface Registration with Geometric Deep Learning
Nov 21, 2023This paper introduces GeoMorph, a novel geometric deep-learning framework designed for image registration of cortical surfaces. The registration process consists of two main steps. First, independent feature extraction is performed on each input surface using graph convolutions, generating low-dimensional feature representations that capture important cortical surface characteristics. Subsequently, features are registered in a deep-discrete manner to optimize the overlap of common structures across surfaces by learning displacements of a set of control points. To ensure smooth and biologically plausible deformations, we implement regularization through a deep conditional random field implemented with a recurrent neural network. Experimental results demonstrate that GeoMorph surpasses existing deep-learning methods by achieving improved alignment with smoother deformations. Furthermore, GeoMorph exhibits competitive performance compared to classical frameworks. Such versatility and robustness suggest strong potential for various neuroscience applications.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 15, 2023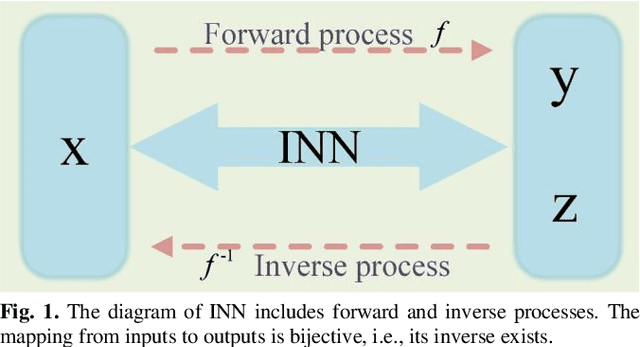
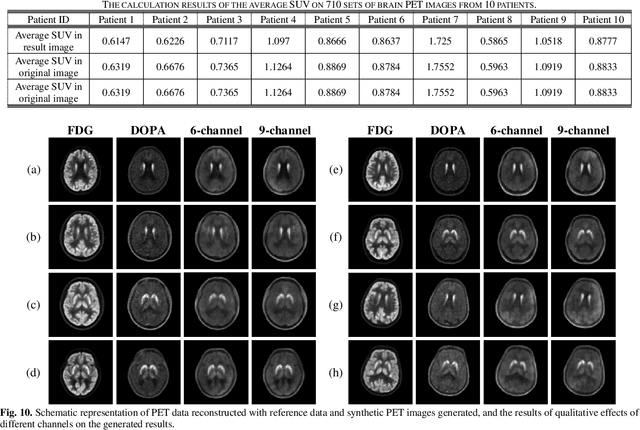
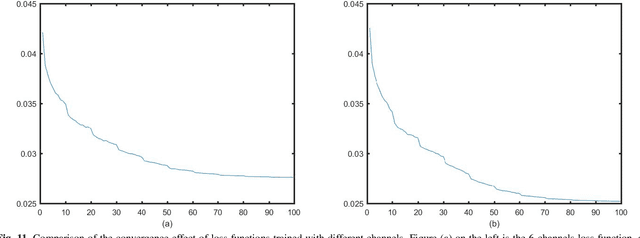
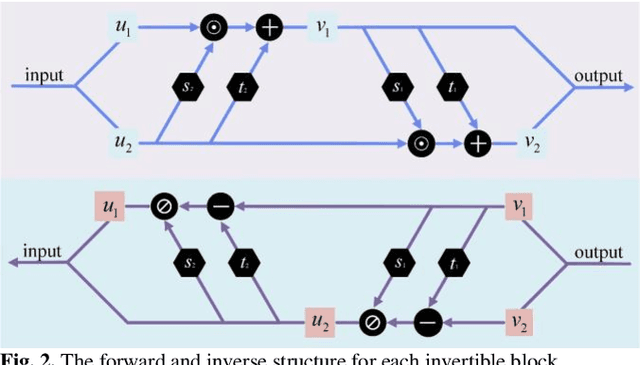
Positron emission tomography (PET) serves as an essential tool for diagnosis of encephalopathy and brain science research. However, it suffers from the limited choice of tracers. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in the field. Nevertheless, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training traceable data, the other for rebuilding new data. The reference DOPA PET image is used as a learning target for the corresponding network during the training process of tracer conversion. Meanwhile, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employs variable enhancement technique to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results exhibited excellent generation capability in mapping between FDG and DOPA, suggesting that PET tracer conversion has great potential in the case of limited tracer applications.
Act-VIT: A Representationally Robust Attention Architecture for Skeleton Based Action Recognition Using Vision Transformer
Nov 14, 2023Skeleton-based action recognition receives the attention of many researchers as it is robust to viewpoint and illumination changes, and its processing is much more efficient than video frames. With the emergence of deep learning models, it has become very popular to represent the skeleton data in pseudo-image form and apply Convolutional Neural Networks for action recognition. Thereafter, studies concentrated on finding effective methods for forming pseudo-images. Recently, attention networks, more specifically transformers have provided promising results in various vision problems. In this study, the effectiveness of vision transformers for skeleton-based action recognition is examined and its robustness on the pseudo-image representation scheme is investigated. To this end, a three-level architecture, Act-VIT is proposed, which forms a set of pseudo images apply a classifier on each of the representation and combine their results to find the final action class. The classifiers of Act-VIT are first realized by CNNs and then by VITs and their performances are compared. Experimental studies reveal that the vision transformer is less sensitive to the initial pseudo-image representation compared to CNN. Nevertheless, even with the vision transformer, the recognition performance can be further improved by consensus of classifiers.
Hessian-based Similarity Metric for Multimodal Medical Image Registration
Oct 06, 2023One of the fundamental elements of both traditional and certain deep learning medical image registration algorithms is measuring the similarity/dissimilarity between two images. In this work, we propose an analytical solution for measuring similarity between two different medical image modalities based on the Hessian of their intensities. First, assuming a functional dependence between the intensities of two perfectly corresponding patches, we investigate how their Hessians relate to each other. Secondly, we suggest a closed-form expression to quantify the deviation from this relationship, given arbitrary pairs of image patches. We propose a geometrical interpretation of the new similarity metric and an efficient implementation for registration. We demonstrate the robustness of the metric to intensity nonuniformities using synthetic bias fields. By integrating the new metric in an affine registration framework, we evaluate its performance for MRI and ultrasound registration in the context of image-guided neurosurgery using target registration error and computation time.