 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey on Monocular Re-Localization: From the Perspective of Scene Map Representation
Nov 27, 2023
Monocular Re-Localization (MRL) is a critical component in numerous autonomous applications, which estimates 6 degree-of-freedom poses with regards to the scene map based on a single monocular image. In recent decades, significant progress has been made in the development of MRL techniques. Numerous landmark algorithms have accomplished extraordinary success in terms of localization accuracy and robustness against visual interference. In MRL research, scene maps are represented in various forms, and they determine how MRL methods work and even how MRL methods perform. However, to the best of our knowledge, existing surveys do not provide systematic reviews of MRL from the respective of map. This survey fills the gap by comprehensively reviewing MRL methods employing monocular cameras as main sensors, promoting further research. 1) We commence by delving into the problem definition of MRL and exploring current challenges, while also comparing ours with with previous published surveys. 2) MRL methods are then categorized into five classes according to the representation forms of utilized map, i.e., geo-tagged frames, visual landmarks, point clouds, and vectorized semantic map, and we review the milestone MRL works of each category. 3) To quantitatively and fairly compare MRL methods with various map, we also review some public datasets and provide the performances of some typical MRL methods. The strengths and weakness of different types of MRL methods are analyzed. 4) We finally introduce some topics of interest in this field and give personal opinions. This survey can serve as a valuable referenced materials for newcomers and researchers interested in MRL, and a continuously updated summary of this survey, including reviewed papers and datasets, is publicly available to the community at: https://github.com/jinyummiao/map-in-mono-reloc.
Geometric Data Augmentations to Mitigate Distribution Shifts in Pollen Classification from Microscopic Images
Nov 18, 2023Distribution shifts are characterized by differences between the training and test data distributions. They can significantly reduce the accuracy of machine learning models deployed in real-world scenarios. This paper explores the distribution shift problem when classifying pollen grains from microscopic images collected in the wild with a low-cost camera sensor. We leverage the domain knowledge that geometric features are highly important for accurate pollen identification and introduce two novel geometric image augmentation techniques to significantly narrow the accuracy gap between the model performance on the train and test datasets. In particular, we show that Tenengrad and ImageToSketch filters are highly effective to balance the shape and texture information while leaving out unimportant details that may confuse the model. Extensive evaluations on various model architectures demonstrate a consistent improvement of the model generalization to field data of up to 14% achieved by the geometric augmentation techniques when compared to a wide range of standard image augmentations. The approach is validated through an ablation study using pollen hydration tests to recover the shape of dry pollen grains. The proposed geometric augmentations also receive the highest scores according to the affinity and diversity measures from the literature.
Beyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Nov 18, 2023Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.
Bayesian Methods for Media Mix Modelling with shape and funnel effects
Nov 21, 2023In recent years, significant progress in generative AI has highlighted the important role of physics-inspired models that utilize advanced mathematical concepts based on fundamental physics principles to enhance artificial intelligence capabilities. Among these models, those based on diffusion equations have greatly improved image quality. This study aims to explore the potential uses of Maxwell-Boltzmann equation, which forms the basis of the kinetic theory of gases, and the Michaelis-Menten model in Marketing Mix Modelling (MMM) applications. We propose incorporating these equations into Hierarchical Bayesian models to analyse consumer behaviour in the context of advertising. These equation sets excel in accurately describing the random dynamics in complex systems like social interactions and consumer-advertising interactions.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 20, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
Energy efficiency in Edge TPU vs. embedded GPU for computer-aided medical imaging segmentation and classification
Nov 20, 2023In this work, we evaluate the energy usage of fully embedded medical diagnosis aids based on both segmentation and classification of medical images implemented on Edge TPU and embedded GPU processors. We use glaucoma diagnosis based on color fundus images as an example to show the possibility of performing segmentation and classification in real time on embedded boards and to highlight the different energy requirements of the studied implementations. Several other works develop the use of segmentation and feature extraction techniques to detect glaucoma, among many other pathologies, with deep neural networks. Memory limitations and low processing capabilities of embedded accelerated systems (EAS) limit their use for deep network-based system training. However, including specific acceleration hardware, such as NVIDIA's Maxwell GPU or Google's Edge TPU, enables them to perform inferences using complex pre-trained networks in very reasonable times. In this study, we evaluate the timing and energy performance of two EAS equipped with Machine Learning (ML) accelerators executing an example diagnostic tool developed in a previous work. For optic disc (OD) and cup (OC) segmentation, the obtained prediction times per image are under 29 and 43 ms using Edge TPUs and Maxwell GPUs, respectively. Prediction times for the classification subsystem are lower than 10 and 14 ms for Edge TPUs and Maxwell GPUs, respectively. Regarding energy usage, in approximate terms, for OD segmentation Edge TPUs and Maxwell GPUs use 38 and 190 mJ per image, respectively. For fundus classification, Edge TPUs and Maxwell GPUs use 45 and 70 mJ, respectively.
* 37 pages, 20 figures. Accepted manuscript. Published in "Engineering Applications of Artificial Intelligence" (Elsevier), ISSN 0952-1976
DiffSCI: Zero-Shot Snapshot Compressive Imaging via Iterative Spectral Diffusion Model
Nov 19, 2023
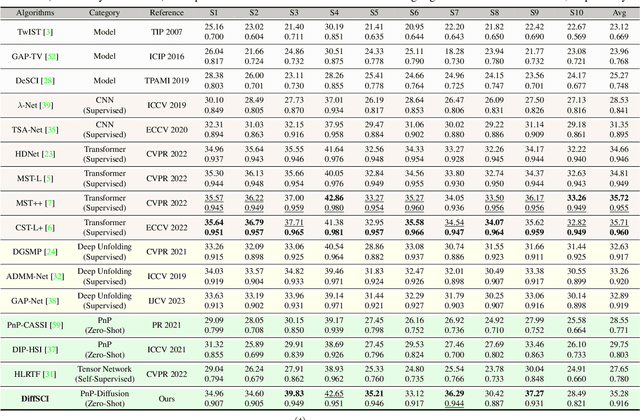
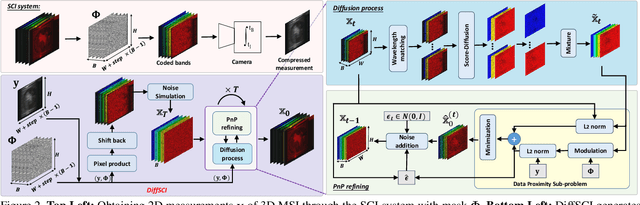
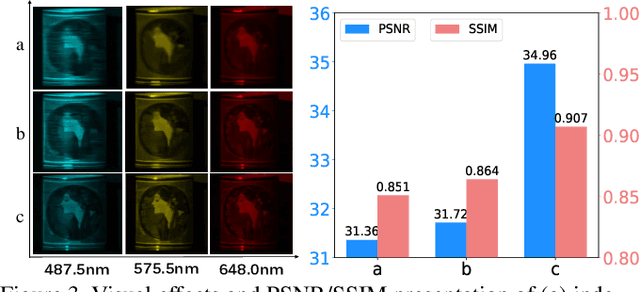
This paper endeavors to advance the precision of snapshot compressive imaging (SCI) reconstruction for multispectral image (MSI). To achieve this, we integrate the advantageous attributes of established SCI techniques and an image generative model, propose a novel structured zero-shot diffusion model, dubbed DiffSCI. DiffSCI leverages the structural insights from the deep prior and optimization-based methodologies, complemented by the generative capabilities offered by the contemporary denoising diffusion model. Specifically, firstly, we employ a pre-trained diffusion model, which has been trained on a substantial corpus of RGB images, as the generative denoiser within the Plug-and-Play framework for the first time. This integration allows for the successful completion of SCI reconstruction, especially in the case that current methods struggle to address effectively. Secondly, we systematically account for spectral band correlations and introduce a robust methodology to mitigate wavelength mismatch, thus enabling seamless adaptation of the RGB diffusion model to MSIs. Thirdly, an accelerated algorithm is implemented to expedite the resolution of the data subproblem. This augmentation not only accelerates the convergence rate but also elevates the quality of the reconstruction process. We present extensive testing to show that DiffSCI exhibits discernible performance enhancements over prevailing self-supervised and zero-shot approaches, surpassing even supervised transformer counterparts across both simulated and real datasets. Our code will be available.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 19, 2023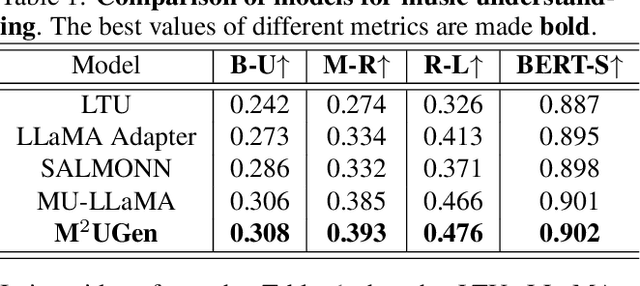
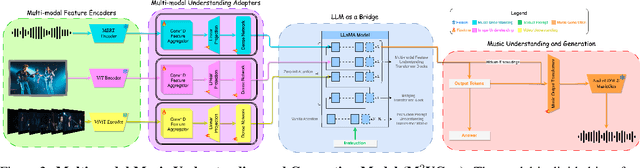
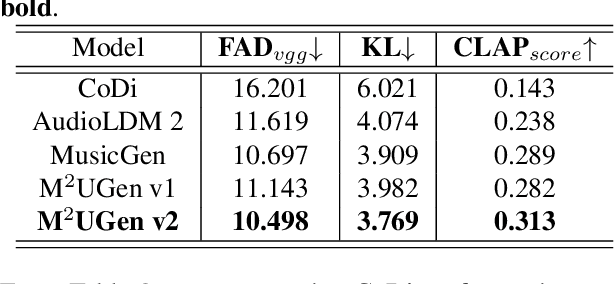
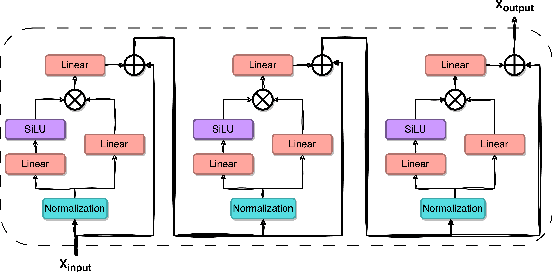
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
Asynchronous Bioplausible Neuron for Spiking Neural Networks for Event-Based Vision
Nov 20, 2023Spiking Neural Networks (SNNs) offer a biologically inspired approach to computer vision that can lead to more efficient processing of visual data with reduced energy consumption. However, maintaining homeostasis within these networks is challenging, as it requires continuous adjustment of neural responses to preserve equilibrium and optimal processing efficiency amidst diverse and often unpredictable input signals. In response to these challenges, we propose the Asynchronous Bioplausible Neuron (ABN), a dynamic spike firing mechanism to auto-adjust the variations in the input signal. Comprehensive evaluation across various datasets demonstrates ABN's enhanced performance in image classification and segmentation, maintenance of neural equilibrium, and energy efficiency.
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Oct 23, 2023In this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images.Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details.To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.