 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey on Deep Learning for Polyp Segmentation: Techniques, Challenges and Future Trends
Nov 30, 2023
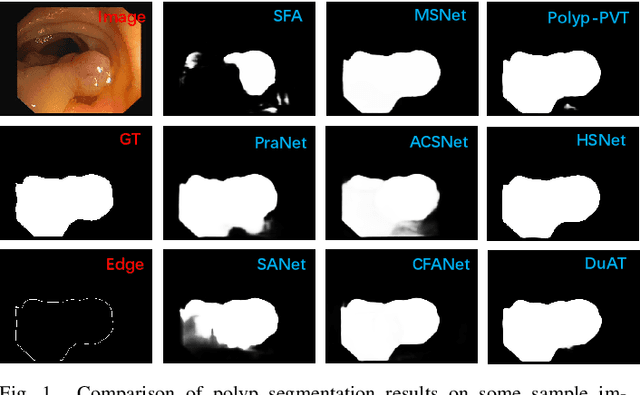
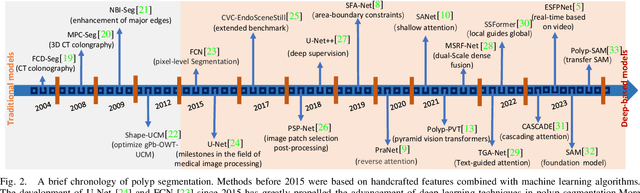
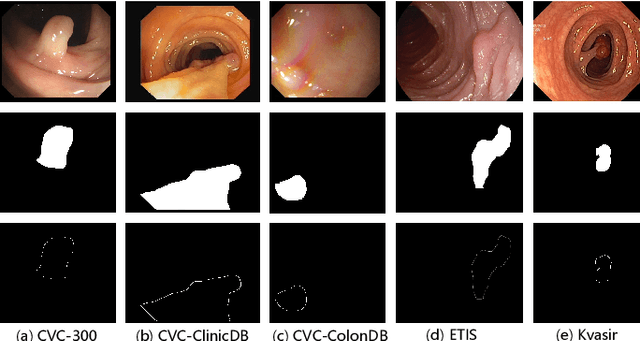

Early detection and assessment of polyps play a crucial role in the prevention and treatment of colorectal cancer (CRC). Polyp segmentation provides an effective solution to assist clinicians in accurately locating and segmenting polyp regions. In the past, people often relied on manually extracted lower-level features such as color, texture, and shape, which often had issues capturing global context and lacked robustness to complex scenarios. With the advent of deep learning, more and more outstanding medical image segmentation algorithms based on deep learning networks have emerged, making significant progress in this field. This paper provides a comprehensive review of polyp segmentation algorithms. We first review some traditional algorithms based on manually extracted features and deep segmentation algorithms, then detail benchmark datasets related to the topic. Specifically, we carry out a comprehensive evaluation of recent deep learning models and results based on polyp sizes, considering the pain points of research topics and differences in network structures. Finally, we discuss the challenges of polyp segmentation and future trends in this field. The models, benchmark datasets, and source code links we collected are all published at https://github.com/taozh2017/Awesome-Polyp-Segmentation.
HKUST at SemEval-2023 Task 1: Visual Word Sense Disambiguation with Context Augmentation and Visual Assistance
Nov 30, 2023Visual Word Sense Disambiguation (VWSD) is a multi-modal task that aims to select, among a batch of candidate images, the one that best entails the target word's meaning within a limited context. In this paper, we propose a multi-modal retrieval framework that maximally leverages pretrained Vision-Language models, as well as open knowledge bases and datasets. Our system consists of the following key components: (1) Gloss matching: a pretrained bi-encoder model is used to match contexts with proper senses of the target words; (2) Prompting: matched glosses and other textual information, such as synonyms, are incorporated using a prompting template; (3) Image retrieval: semantically matching images are retrieved from large open datasets using prompts as queries; (4) Modality fusion: contextual information from different modalities are fused and used for prediction. Although our system does not produce the most competitive results at SemEval-2023 Task 1, we are still able to beat nearly half of the teams. More importantly, our experiments reveal acute insights for the field of Word Sense Disambiguation (WSD) and multi-modal learning. Our code is available on GitHub.
TCP:Textual-based Class-aware Prompt tuning for Visual-Language Model
Nov 30, 2023Prompt tuning represents a valuable technique for adapting pre-trained visual-language models (VLM) to various downstream tasks. Recent advancements in CoOp-based methods propose a set of learnable domain-shared or image-conditional textual tokens to facilitate the generation of task-specific textual classifiers. However, those textual tokens have a limited generalization ability regarding unseen domains, as they cannot dynamically adjust to the distribution of testing classes. To tackle this issue, we present a novel Textual-based Class-aware Prompt tuning(TCP) that explicitly incorporates prior knowledge about classes to enhance their discriminability. The critical concept of TCP involves leveraging Textual Knowledge Embedding (TKE) to map the high generalizability of class-level textual knowledge into class-aware textual tokens. By seamlessly integrating these class-aware prompts into the Text Encoder, a dynamic class-aware classifier is generated to enhance discriminability for unseen domains. During inference, TKE dynamically generates class-aware prompts related to the unseen classes. Comprehensive evaluations demonstrate that TKE serves as a plug-and-play module effortlessly combinable with existing methods. Furthermore, TCP consistently achieves superior performance while demanding less training time.
DNS SLAM: Dense Neural Semantic-Informed SLAM
Nov 30, 2023

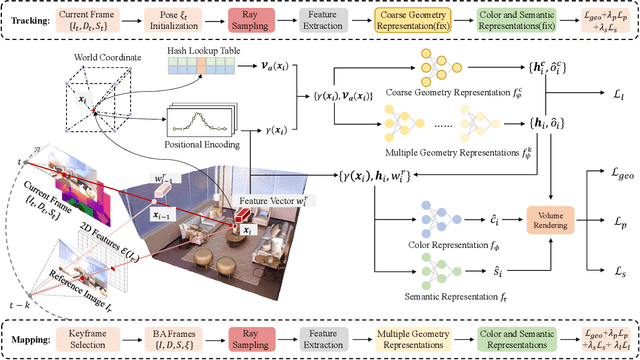
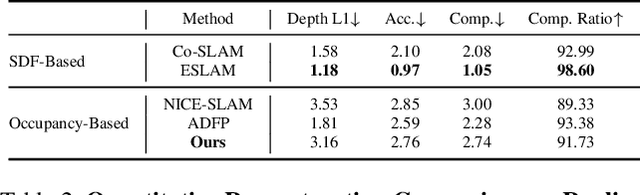
In recent years, coordinate-based neural implicit representations have shown promising results for the task of Simultaneous Localization and Mapping (SLAM). While achieving impressive performance on small synthetic scenes, these methods often suffer from oversmoothed reconstructions, especially for complex real-world scenes. In this work, we introduce DNS SLAM, a novel neural RGB-D semantic SLAM approach featuring a hybrid representation. Relying only on 2D semantic priors, we propose the first semantic neural SLAM method that trains class-wise scene representations while providing stable camera tracking at the same time. Our method integrates multi-view geometry constraints with image-based feature extraction to improve appearance details and to output color, density, and semantic class information, enabling many downstream applications. To further enable real-time tracking, we introduce a lightweight coarse scene representation which is trained in a self-supervised manner in latent space. Our experimental results achieve state-of-the-art performance on both synthetic data and real-world data tracking while maintaining a commendable operational speed on off-the-shelf hardware. Further, our method outputs class-wise decomposed reconstructions with better texture capturing appearance and geometric details.
OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
Nov 30, 2023Due to the resource-intensive nature of training vision-language models on expansive video data, a majority of studies have centered on adapting pre-trained image-language models to the video domain. Dominant pipelines propose to tackle the visual discrepancies with additional temporal learners while overlooking the substantial discrepancy for web-scaled descriptive narratives and concise action category names, leading to less distinct semantic space and potential performance limitations. In this work, we prioritize the refinement of text knowledge to facilitate generalizable video recognition. To address the limitations of the less distinct semantic space of category names, we prompt a large language model (LLM) to augment action class names into Spatio-Temporal Descriptors thus bridging the textual discrepancy and serving as a knowledge base for general recognition. Moreover, to assign the best descriptors with different video instances, we propose Optimal Descriptor Solver, forming the video recognition problem as solving the optimal matching flow across frame-level representations and descriptors. Comprehensive evaluations in zero-shot, few-shot, and fully supervised video recognition highlight the effectiveness of our approach. Our best model achieves a state-of-the-art zero-shot accuracy of 75.1% on Kinetics-600.
Fast ODE-based Sampling for Diffusion Models in Around 5 Steps
Nov 30, 2023Sampling from diffusion models can be treated as solving the corresponding ordinary differential equations (ODEs), with the aim of obtaining an accurate solution with as few number of function evaluations (NFE) as possible. Recently, various fast samplers utilizing higher-order ODE solvers have emerged and achieved better performance than the initial first-order one. However, these numerical methods inherently result in certain approximation errors, which significantly degrades sample quality with extremely small NFE (e.g., around 5). In contrast, based on the geometric observation that each sampling trajectory almost lies in a two-dimensional subspace embedded in the ambient space, we propose Approximate MEan-Direction Solver (AMED-Solver) that eliminates truncation errors by directly learning the mean direction for fast diffusion sampling. Besides, our method can be easily used as a plugin to further improve existing ODE-based samplers. Extensive experiments on image synthesis with the resolution ranging from 32 to 256 demonstrate the effectiveness of our method. With only 5 NFE, we achieve 7.14 FID on CIFAR-10, 13.75 FID on ImageNet 64$\times$64, and 12.79 FID on LSUN Bedroom. Our code is available at https://github.com/zhyzhouu/amed-solver.
CHIP: Contrastive Hierarchical Image Pretraining
Oct 12, 2023Few-shot object classification is the task of classifying objects in an image with limited number of examples as supervision. We propose a one-shot/few-shot classification model that can classify an object of any unseen class into a relatively general category in an hierarchically based classification. Our model uses a three-level hierarchical contrastive loss based ResNet152 classifier for classifying an object based on its features extracted from Image embedding, not used during the training phase. For our experimentation, we have used a subset of the ImageNet (ILSVRC-12) dataset that contains only the animal classes for training our model and created our own dataset of unseen classes for evaluating our trained model. Our model provides satisfactory results in classifying the unknown objects into a generic category which has been later discussed in greater detail.
Robust Diffusion GAN using Semi-Unbalanced Optimal Transport
Nov 28, 2023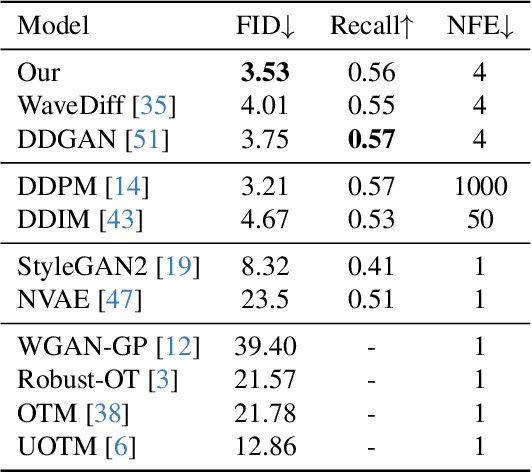

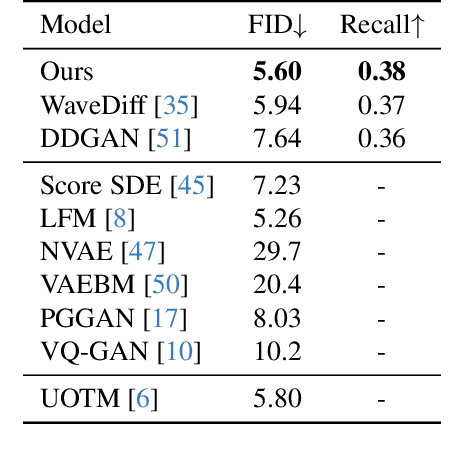
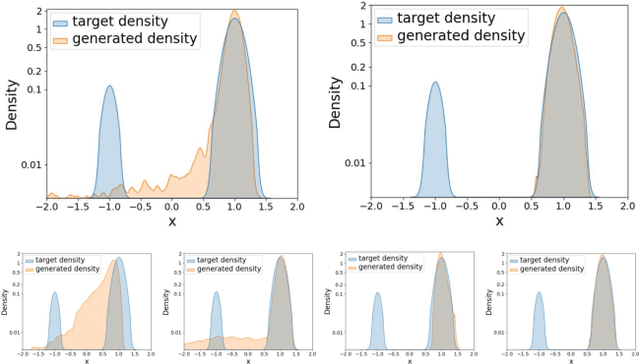
Diffusion models, a type of generative model, have demonstrated great potential for synthesizing highly detailed images. By integrating with GAN, advanced diffusion models like DDGAN \citep{xiao2022DDGAN} could approach real-time performance for expansive practical applications. While DDGAN has effectively addressed the challenges of generative modeling, namely producing high-quality samples, covering different data modes, and achieving faster sampling, it remains susceptible to performance drops caused by datasets that are corrupted with outlier samples. This work introduces a robust training technique based on semi-unbalanced optimal transport to mitigate the impact of outliers effectively. Through comprehensive evaluations, we demonstrate that our robust diffusion GAN (RDGAN) outperforms vanilla DDGAN in terms of the aforementioned generative modeling criteria, i.e., image quality, mode coverage of distribution, and inference speed, and exhibits improved robustness when dealing with both clean and corrupted datasets.
Infrared image identification method of substation equipment fault under weak supervision
Nov 19, 2023This study presents a weakly supervised method for identifying faults in infrared images of substation equipment. It utilizes the Faster RCNN model for equipment identification, enhancing detection accuracy through modifications to the model's network structure and parameters. The method is exemplified through the analysis of infrared images captured by inspection robots at substations. Performance is validated against manually marked results, demonstrating that the proposed algorithm significantly enhances the accuracy of fault identification across various equipment types.
Leveraging Unlabeled Data for 3D Medical Image Segmentation through Self-Supervised Contrastive Learning
Nov 21, 2023Current 3D semi-supervised segmentation methods face significant challenges such as limited consideration of contextual information and the inability to generate reliable pseudo-labels for effective unsupervised data use. To address these challenges, we introduce two distinct subnetworks designed to explore and exploit the discrepancies between them, ultimately correcting the erroneous prediction results. More specifically, we identify regions of inconsistent predictions and initiate a targeted verification training process. This procedure strategically fine-tunes and harmonizes the predictions of the subnetworks, leading to enhanced utilization of contextual information. Furthermore, to adaptively fine-tune the network's representational capacity and reduce prediction uncertainty, we employ a self-supervised contrastive learning paradigm. For this, we use the network's confidence to distinguish between reliable and unreliable predictions. The model is then trained to effectively minimize unreliable predictions. Our experimental results for organ segmentation, obtained from clinical MRI and CT scans, demonstrate the effectiveness of our approach when compared to state-of-the-art methods. The codebase is accessible on \href{https://github.com/xmindflow/SSL-contrastive}{GitHub}.