 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A comprehensive survey on deep active learning and its applications in medical image analysis
Oct 22, 2023
Deep learning has achieved widespread success in medical image analysis, leading to an increasing demand for large-scale expert-annotated medical image datasets. Yet, the high cost of annotating medical images severely hampers the development of deep learning in this field. To reduce annotation costs, active learning aims to select the most informative samples for annotation and train high-performance models with as few labeled samples as possible. In this survey, we review the core methods of active learning, including the evaluation of informativeness and sampling strategy. For the first time, we provide a detailed summary of the integration of active learning with other label-efficient techniques, such as semi-supervised, self-supervised learning, and so on. Additionally, we also highlight active learning works that are specifically tailored to medical image analysis. In the end, we offer our perspectives on the future trends and challenges of active learning and its applications in medical image analysis.
Dual-Domain Multi-Contrast MRI Reconstruction with Synthesis-based Fusion Network
Dec 01, 2023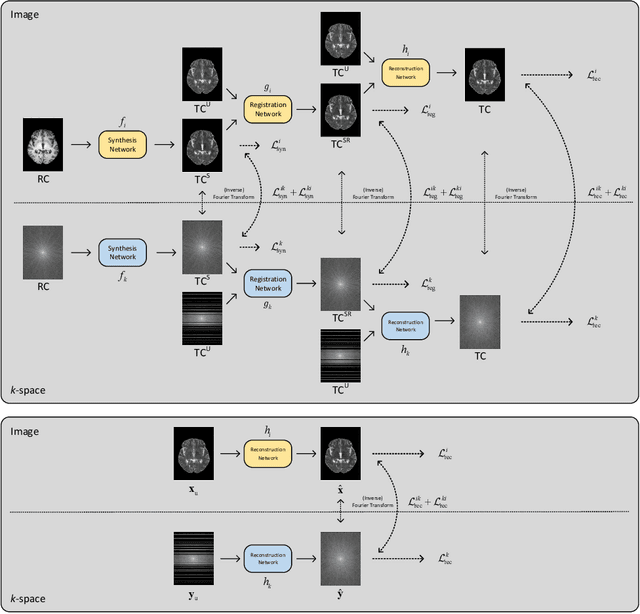

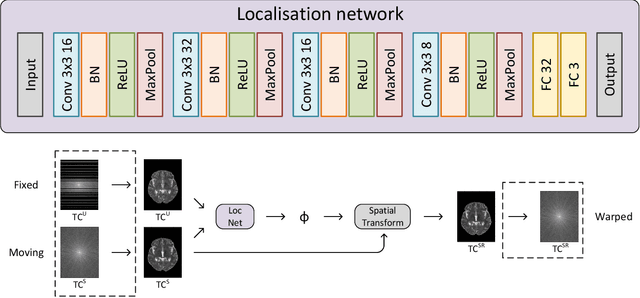

Purpose: To develop an efficient dual-domain reconstruction framework for multi-contrast MRI, with the focus on minimising cross-contrast misalignment in both the image and the frequency domains to enhance optimisation. Theory and Methods: Our proposed framework, based on deep learning, facilitates the optimisation for under-sampled target contrast using fully-sampled reference contrast that is quicker to acquire. The method consists of three key steps: 1) Learning to synthesise data resembling the target contrast from the reference contrast; 2) Registering the multi-contrast data to reduce inter-scan motion; and 3) Utilising the registered data for reconstructing the target contrast. These steps involve learning in both domains with regularisation applied to ensure their consistency. We also compare the reconstruction performance with existing deep learning-based methods using a dataset of brain MRI scans. Results: Extensive experiments demonstrate the superiority of our proposed framework, for up to an 8-fold acceleration rate, compared to state-of-the-art algorithms. Comprehensive analysis and ablation studies further present the effectiveness of the proposed components. Conclusion:Our dual-domain framework offers a promising approach to multi-contrast MRI reconstruction. It can also be integrated with existing methods to further enhance the reconstruction.
Physics Inspired Criterion for Pruning-Quantization Joint Learning
Dec 01, 2023Pruning-quantization joint learning always facilitates the deployment of deep neural networks (DNNs) on resource-constrained edge devices. However, most existing methods do not jointly learn a global criterion for pruning and quantization in an interpretable way. In this paper, we propose a novel physics inspired criterion for pruning-quantization joint learning (PIC-PQ), which is explored from an analogy we first draw between elasticity dynamics (ED) and model compression (MC). Specifically, derived from Hooke's law in ED, we establish a linear relationship between the filters' importance distribution and the filter property (FP) by a learnable deformation scale in the physics inspired criterion (PIC). Furthermore, we extend PIC with a relative shift variable for a global view. To ensure feasibility and flexibility, available maximum bitwidth and penalty factor are introduced in quantization bitwidth assignment. Experiments on benchmarks of image classification demonstrate that PIC-PQ yields a good trade-off between accuracy and bit-operations (BOPs) compression ratio e.g., 54.96X BOPs compression ratio in ResNet56 on CIFAR10 with 0.10% accuracy drop and 53.24X in ResNet18 on ImageNet with 0.61% accuracy drop). The code will be available at https://github.com/fanxxxxyi/PIC-PQ.
Target-agnostic Source-free Domain Adaptation for Regression Tasks
Dec 01, 2023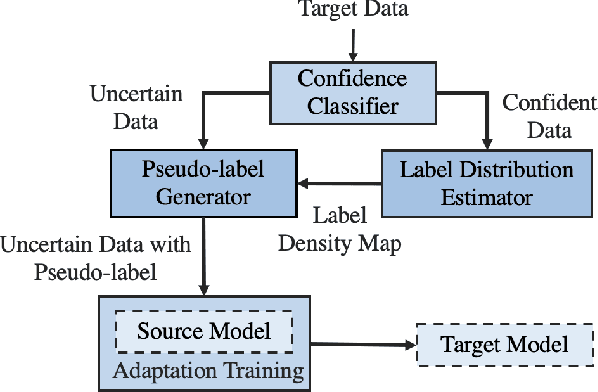
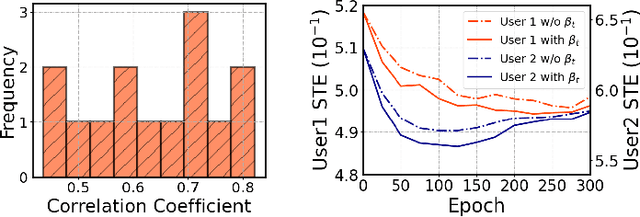
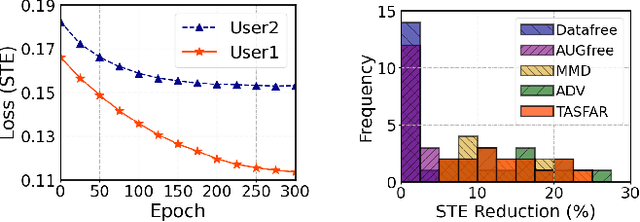
Unsupervised domain adaptation (UDA) seeks to bridge the domain gap between the target and source using unlabeled target data. Source-free UDA removes the requirement for labeled source data at the target to preserve data privacy and storage. However, work on source-free UDA assumes knowledge of domain gap distribution, and hence is limited to either target-aware or classification task. To overcome it, we propose TASFAR, a novel target-agnostic source-free domain adaptation approach for regression tasks. Using prediction confidence, TASFAR estimates a label density map as the target label distribution, which is then used to calibrate the source model on the target domain. We have conducted extensive experiments on four regression tasks with various domain gaps, namely, pedestrian dead reckoning for different users, image-based people counting in different scenes, housing-price prediction at different districts, and taxi-trip duration prediction from different departure points. TASFAR is shown to substantially outperform the state-of-the-art source-free UDA approaches by averagely reducing 22% errors for the four tasks and achieve notably comparable accuracy as source-based UDA without using source data.
Dolphins: Multimodal Language Model for Driving
Dec 01, 2023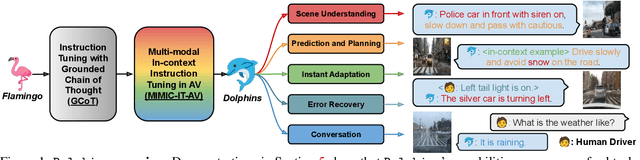


The quest for fully autonomous vehicles (AVs) capable of navigating complex real-world scenarios with human-like understanding and responsiveness. In this paper, we introduce Dolphins, a novel vision-language model architected to imbibe human-like abilities as a conversational driving assistant. Dolphins is adept at processing multimodal inputs comprising video (or image) data, text instructions, and historical control signals to generate informed outputs corresponding to the provided instructions. Building upon the open-sourced pretrained Vision-Language Model, OpenFlamingo, we first enhance Dolphins's reasoning capabilities through an innovative Grounded Chain of Thought (GCoT) process. Then we tailored Dolphins to the driving domain by constructing driving-specific instruction data and conducting instruction tuning. Through the utilization of the BDD-X dataset, we designed and consolidated four distinct AV tasks into Dolphins to foster a holistic understanding of intricate driving scenarios. As a result, the distinctive features of Dolphins are characterized into two dimensions: (1) the ability to provide a comprehensive understanding of complex and long-tailed open-world driving scenarios and solve a spectrum of AV tasks, and (2) the emergence of human-like capabilities including gradient-free instant adaptation via in-context learning and error recovery via reflection.
Text-Guided 3D Face Synthesis -- From Generation to Editing
Dec 01, 2023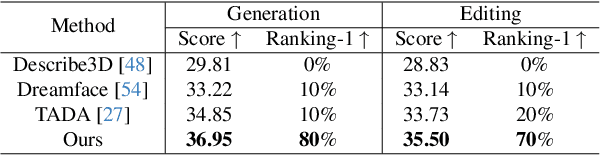
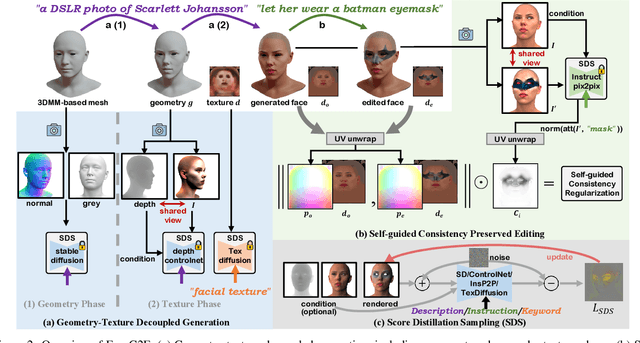
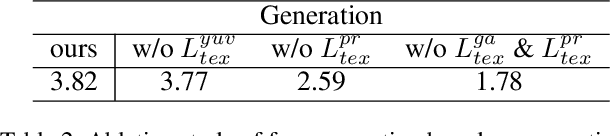
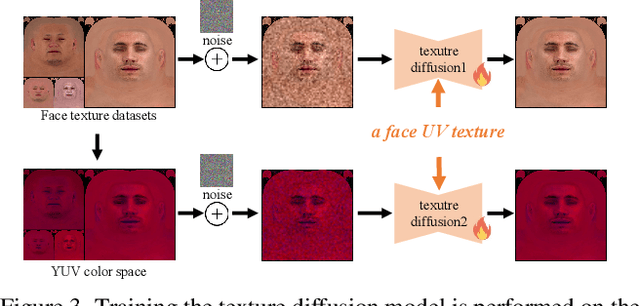
Text-guided 3D face synthesis has achieved remarkable results by leveraging text-to-image (T2I) diffusion models. However, most existing works focus solely on the direct generation, ignoring the editing, restricting them from synthesizing customized 3D faces through iterative adjustments. In this paper, we propose a unified text-guided framework from face generation to editing. In the generation stage, we propose a geometry-texture decoupled generation to mitigate the loss of geometric details caused by coupling. Besides, decoupling enables us to utilize the generated geometry as a condition for texture generation, yielding highly geometry-texture aligned results. We further employ a fine-tuned texture diffusion model to enhance texture quality in both RGB and YUV space. In the editing stage, we first employ a pre-trained diffusion model to update facial geometry or texture based on the texts. To enable sequential editing, we introduce a UV domain consistency preservation regularization, preventing unintentional changes to irrelevant facial attributes. Besides, we propose a self-guided consistency weight strategy to improve editing efficacy while preserving consistency. Through comprehensive experiments, we showcase our method's superiority in face synthesis. Project page: https://faceg2e.github.io/.
Self-Supervised Learning of Whole and Component-Based Semantic Representations for Person Re-Identification
Dec 01, 2023Interactive Segmentation Models (ISMs) like the Segment Anything Model have significantly improved various computer vision tasks, yet their application to Person Re-identification (ReID) remains limited. On the other hand, existing semantic pre-training models for ReID often have limitations like predefined parsing ranges or coarse semantics. Additionally, ReID and Clothes-Changing ReID (CC-ReID) are usually treated separately due to their different domains. This paper investigates whether utilizing precise human-centric semantic representation can boost the ReID performance and improve the generalization among various ReID tasks. We propose SemReID, a self-supervised ReID model that leverages ISMs for adaptive part-based semantic extraction, contributing to the improvement of ReID performance. SemReID additionally refines its semantic representation through techniques such as image masking and KoLeo regularization. Evaluation across three types of ReID datasets -- standard ReID, CC-ReID, and unconstrained ReID -- demonstrates superior performance compared to state-of-the-art methods. In addition, recognizing the scarcity of large person datasets with fine-grained semantics, we introduce the novel LUPerson-Part dataset to assist ReID methods in acquiring the fine-grained part semantics for robust performance.
AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort
Nov 19, 2023
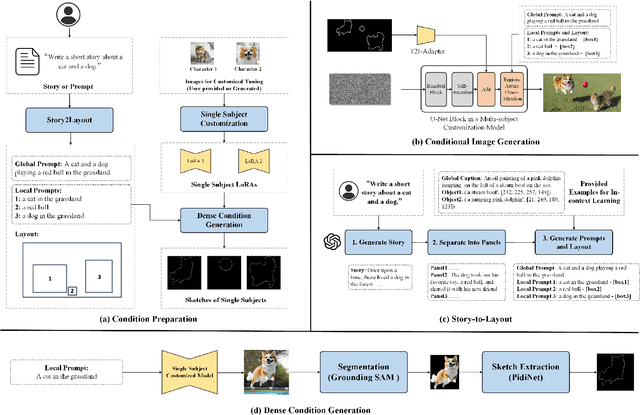

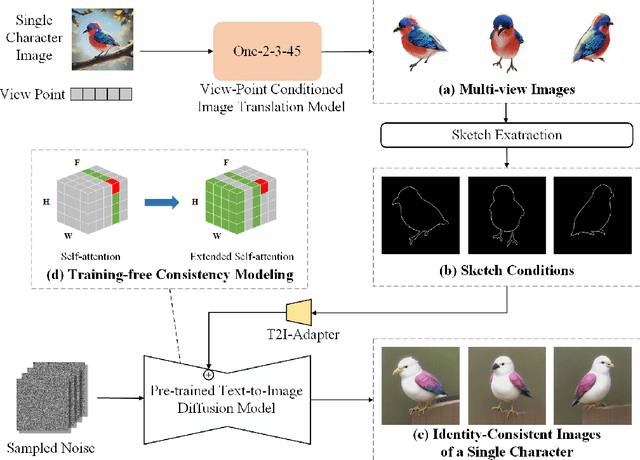
Story visualization aims to generate a series of images that match the story described in texts, and it requires the generated images to satisfy high quality, alignment with the text description, and consistency in character identities. Given the complexity of story visualization, existing methods drastically simplify the problem by considering only a few specific characters and scenarios, or requiring the users to provide per-image control conditions such as sketches. However, these simplifications render these methods incompetent for real applications. To this end, we propose an automated story visualization system that can effectively generate diverse, high-quality, and consistent sets of story images, with minimal human interactions. Specifically, we utilize the comprehension and planning capabilities of large language models for layout planning, and then leverage large-scale text-to-image models to generate sophisticated story images based on the layout. We empirically find that sparse control conditions, such as bounding boxes, are suitable for layout planning, while dense control conditions, e.g., sketches and keypoints, are suitable for generating high-quality image content. To obtain the best of both worlds, we devise a dense condition generation module to transform simple bounding box layouts into sketch or keypoint control conditions for final image generation, which not only improves the image quality but also allows easy and intuitive user interactions. In addition, we propose a simple yet effective method to generate multi-view consistent character images, eliminating the reliance on human labor to collect or draw character images.
Computer Vision for Increased Operative Efficiency via Identification of Instruments in the Neurosurgical Operating Room: A Proof-of-Concept Study
Dec 03, 2023Objectives Computer vision (CV) is a field of artificial intelligence that enables machines to interpret and understand images and videos. CV has the potential to be of assistance in the operating room (OR) to track surgical instruments. We built a CV algorithm for identifying surgical instruments in the neurosurgical operating room as a potential solution for surgical instrument tracking and management to decrease surgical waste and opening of unnecessary tools. Methods We collected 1660 images of 27 commonly used neurosurgical instruments. Images were labeled using the VGG Image Annotator and split into 80% training and 20% testing sets in order to train a U-Net Convolutional Neural Network using 5-fold cross validation. Results Our U-Net achieved a tool identification accuracy of 80-100% when distinguishing 25 classes of instruments, with 19/25 classes having accuracy over 90%. The model performance was not adequate for sub classifying Adson, Gerald, and Debakey forceps, which had accuracies of 60-80%. Conclusions We demonstrated the viability of using machine learning to accurately identify surgical instruments. Instrument identification could help optimize surgical tray packing, decrease tool usage and waste, decrease incidence of instrument misplacement events, and assist in timing of routine instrument maintenance. More training data will be needed to increase accuracy across all surgical instruments that would appear in a neurosurgical operating room. Such technology has the potential to be used as a method to be used for proving what tools are truly needed in each type of operation allowing surgeons across the world to do more with less.
A Probabilistic Method to Predict Classifier Accuracy on Larger Datasets given Small Pilot Data
Nov 29, 2023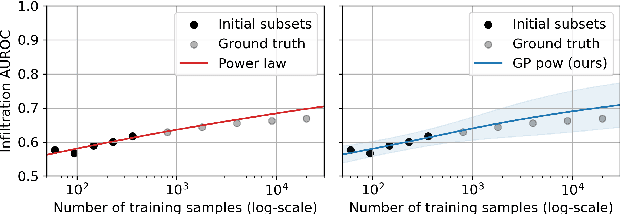

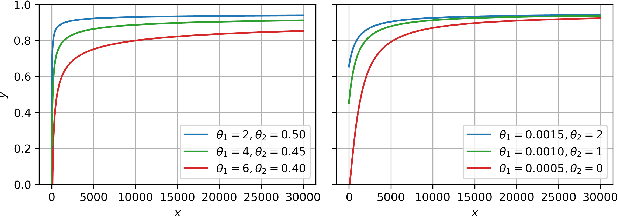
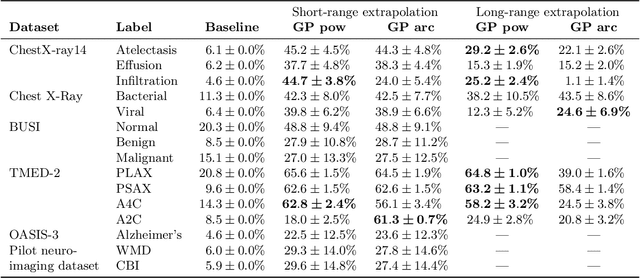
Practitioners building classifiers often start with a smaller pilot dataset and plan to grow to larger data in the near future. Such projects need a toolkit for extrapolating how much classifier accuracy may improve from a 2x, 10x, or 50x increase in data size. While existing work has focused on finding a single "best-fit" curve using various functional forms like power laws, we argue that modeling and assessing the uncertainty of predictions is critical yet has seen less attention. In this paper, we propose a Gaussian process model to obtain probabilistic extrapolations of accuracy or similar performance metrics as dataset size increases. We evaluate our approach in terms of error, likelihood, and coverage across six datasets. Though we focus on medical tasks and image modalities, our open source approach generalizes to any kind of classifier.