 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Training Image Derivatives: Increased Accuracy and Universal Robustness
Oct 21, 2023
Derivative training is a well-known method to improve the accuracy of neural networks. In the forward pass, not only the output values are computed, but also their derivatives, and their deviations from the target derivatives are included in the cost function, which is minimized with respect to the weights by a gradient-based algorithm. So far, this method has been implemented for relatively low-dimensional tasks. In this study, we apply the approach to the problem of image analysis. We consider the task of reconstructing the vertices of a cube based on its image. By training the derivatives with respect to the 6 degrees of freedom of the cube, we obtain 25 times more accurate results for noiseless inputs. The derivatives also provide important insights into the robustness problem, which is currently understood in terms of two types of network vulnerabilities. The first type is small perturbations that dramatically change the output, and the second type is substantial image changes that the network erroneously ignores. They are currently considered as conflicting goals, since conventional training methods produce a trade-off. The first type can be analyzed via the gradient of the network, but the second type requires human evaluation of the inputs, which is an oracle substitute. For the task at hand, the nearest neighbor oracle can be defined, and the knowledge of derivatives allows it to be expanded into Taylor series. This allows to perform the first-order robustness analysis that unifies both types of vulnerabilities, and to implement robust training that eliminates any trade-offs, so that accuracy and robustness are limited only by network capacity.
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Dec 03, 2023

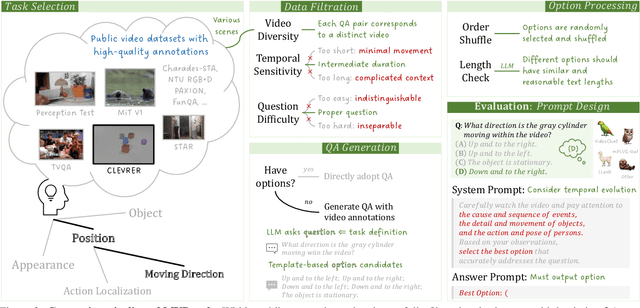

With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
Joint Diffusion: Mutual Consistency-Driven Diffusion Model for PET-MRI Co-Reconstruction
Nov 24, 2023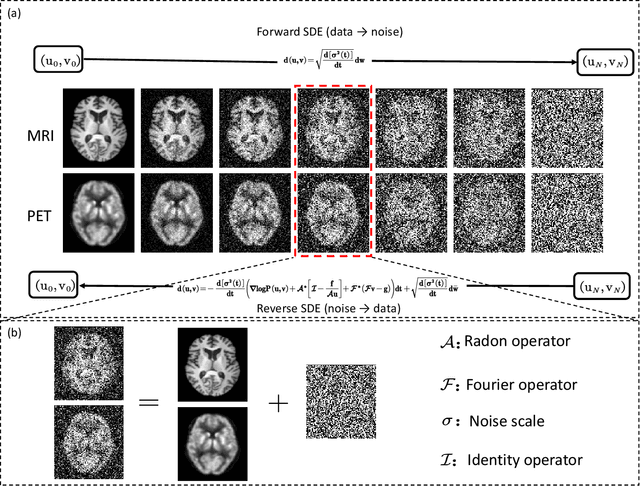
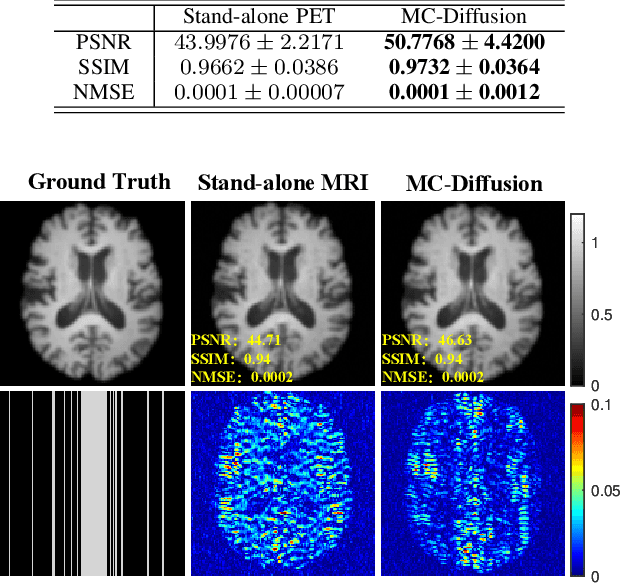
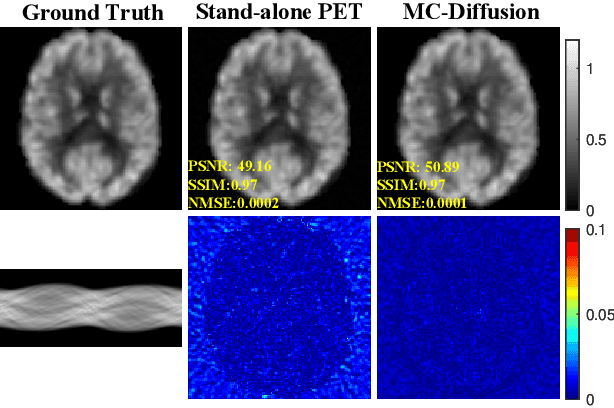
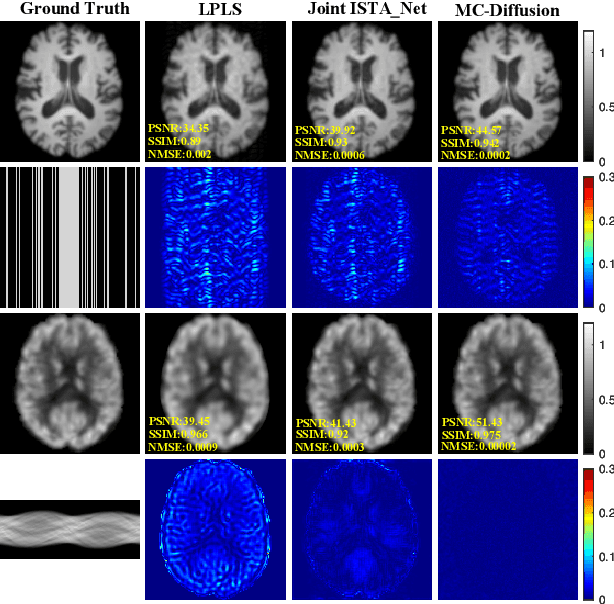
Positron Emission Tomography and Magnetic Resonance Imaging (PET-MRI) systems can obtain functional and anatomical scans. PET suffers from a low signal-to-noise ratio. Meanwhile, the k-space data acquisition process in MRI is time-consuming. The study aims to accelerate MRI and enhance PET image quality. Conventional approaches involve the separate reconstruction of each modality within PET-MRI systems. However, there exists complementary information among multi-modal images. The complementary information can contribute to image reconstruction. In this study, we propose a novel PET-MRI joint reconstruction model employing a mutual consistency-driven diffusion mode, namely MC-Diffusion. MC-Diffusion learns the joint probability distribution of PET and MRI for utilizing complementary information. We conducted a series of contrast experiments about LPLS, Joint ISAT-net and MC-Diffusion by the ADNI dataset. The results underscore the qualitative and quantitative improvements achieved by MC-Diffusion, surpassing the state-of-the-art method.
Evaluation of a measurement system for PET imaging studies
Nov 29, 2023Positron Emission Tomography (PET) enables functional imaging of deep brain structures, but the bulk and weight of current systems preclude their use during many natural human activities, such as locomotion. The proposed long-term solution is to construct a robotic system that can support an imaging system surrounding the subject's head, and then move the system to accommodate natural motion. This requires a system to measure the motion of the head with respect to the imaging ring, for use by both the robotic system and the image reconstruction software. We report here the design and experimental evaluation of a parallel string encoder mechanism for sensing this motion. Our preliminary results indicate that the measurement system may achieve accuracy within 0.5 mm, especially for small motions, with improved accuracy possible through kinematic calibration.
Attention based Dual-Branch Complex Feature Fusion Network for Hyperspectral Image Classification
Nov 02, 2023This research work presents a novel dual-branch model for hyperspectral image classification that combines two streams: one for processing standard hyperspectral patches using Real-Valued Neural Network (RVNN) and the other for processing their corresponding Fourier transforms using Complex-Valued Neural Network (CVNN). The proposed model is evaluated on the Pavia University and Salinas datasets. Results show that the proposed model outperforms state-of-the-art methods in terms of overall accuracy, average accuracy, and Kappa. Through the incorporation of Fourier transforms in the second stream, the model is able to extract frequency information, which complements the spatial information extracted by the first stream. The combination of these two streams improves the overall performance of the model. Furthermore, to enhance the model performance, the Squeeze and Excitation (SE) mechanism has been utilized. Experimental evidence show that SE block improves the models overall accuracy by almost 1\%.
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment
Oct 17, 2023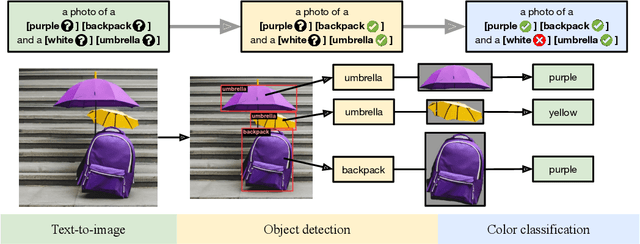
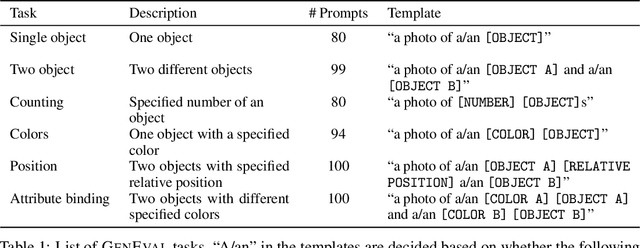
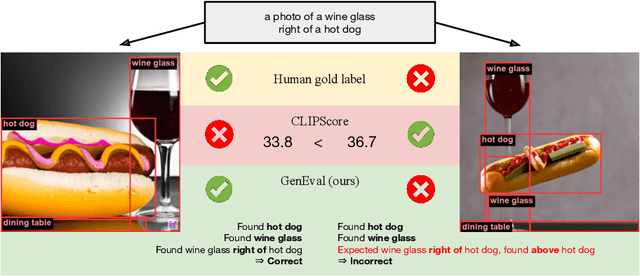

Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models. Given human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models. However, most current automated evaluation metrics like FID or CLIPScore only offer a holistic measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis. In this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color. We show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color. We then evaluate several open-source text-to-image models and analyze their relative generative capabilities on our benchmark. We find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding. Finally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation of text-to-image models. Our code to run the GenEval framework is publicly available at https://github.com/djghosh13/geneval.
Match me if you can: Semantic Correspondence Learning with Unpaired Images
Nov 30, 2023Recent approaches for semantic correspondence have focused on obtaining high-quality correspondences using a complicated network, refining the ambiguous or noisy matching points. Despite their performance improvements, they remain constrained by the limited training pairs due to costly point-level annotations. This paper proposes a simple yet effective method that performs training with unlabeled pairs to complement both limited image pairs and sparse point pairs, requiring neither extra labeled keypoints nor trainable modules. We fundamentally extend the data quantity and variety by augmenting new unannotated pairs not primitively provided as training pairs in benchmarks. Using a simple teacher-student framework, we offer reliable pseudo correspondences to the student network via machine supervision. Finally, the performance of our network is steadily improved by the proposed iterative training, putting back the student as a teacher to generate refined labels and train a new student repeatedly. Our models outperform the milestone baselines, including state-of-the-art methods on semantic correspondence benchmarks.
LLaFS: When Large-Language Models Meet Few-Shot Segmentation
Nov 30, 2023This paper proposes LLaFS, the first attempt to leverage large language models (LLMs) in few-shot segmentation. In contrast to the conventional few-shot segmentation methods that only rely on the limited and biased information from the annotated support images, LLaFS leverages the vast prior knowledge gained by LLM as an effective supplement and directly uses the LLM to segment images in a few-shot manner. To enable the text-based LLM to handle image-related tasks, we carefully design an input instruction that allows the LLM to produce segmentation results represented as polygons, and propose a region-attribute table to simulate the human visual mechanism and provide multi-modal guidance. We also synthesize pseudo samples and use curriculum learning for pretraining to augment data and achieve better optimization. LLaFS achieves state-of-the-art results on multiple datasets, showing the potential of using LLMs for few-shot computer vision tasks. Code will be available at https://github.com/lanyunzhu99/LLaFS.
ZeST-NeRF: Using temporal aggregation for Zero-Shot Temporal NeRFs
Nov 30, 2023In the field of media production, video editing techniques play a pivotal role. Recent approaches have had great success at performing novel view image synthesis of static scenes. But adding temporal information adds an extra layer of complexity. Previous models have focused on implicitly representing static and dynamic scenes using NeRF. These models achieve impressive results but are costly at training and inference time. They overfit an MLP to describe the scene implicitly as a function of position. This paper proposes ZeST-NeRF, a new approach that can produce temporal NeRFs for new scenes without retraining. We can accurately reconstruct novel views using multi-view synthesis techniques and scene flow-field estimation, trained only with unrelated scenes. We demonstrate how existing state-of-the-art approaches from a range of fields cannot adequately solve this new task and demonstrate the efficacy of our solution. The resulting network improves quantitatively by 15% and produces significantly better visual results.
Towards Comparable Active Learning
Nov 30, 2023Active Learning has received significant attention in the field of machine learning for its potential in selecting the most informative samples for labeling, thereby reducing data annotation costs. However, we show that the reported lifts in recent literature generalize poorly to other domains leading to an inconclusive landscape in Active Learning research. Furthermore, we highlight overlooked problems for reproducing AL experiments that can lead to unfair comparisons and increased variance in the results. This paper addresses these issues by providing an Active Learning framework for a fair comparison of algorithms across different tasks and domains, as well as a fast and performant oracle algorithm for evaluation. To the best of our knowledge, we propose the first AL benchmark that tests algorithms in 3 major domains: Tabular, Image, and Text. We report empirical results for 6 widely used algorithms on 7 real-world and 2 synthetic datasets and aggregate them into a domain-specific ranking of AL algorithms.