 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Dataset Distillation via Minimax Diffusion
Nov 27, 2023
Dataset distillation reduces the storage and computational consumption of training a network by generating a small surrogate dataset that encapsulates rich information of the original large-scale one. However, previous distillation methods heavily rely on the sample-wise iterative optimization scheme. As the images-per-class (IPC) setting or image resolution grows larger, the necessary computation will demand overwhelming time and resources. In this work, we intend to incorporate generative diffusion techniques for computing the surrogate dataset. Observing that key factors for constructing an effective surrogate dataset are representativeness and diversity, we design additional minimax criteria in the generative training to enhance these facets for the generated images of diffusion models. We present a theoretical model of the process as hierarchical diffusion control demonstrating the flexibility of the diffusion process to target these criteria without jeopardizing the faithfulness of the sample to the desired distribution. The proposed method achieves state-of-the-art validation performance while demanding much less computational resources. Under the 100-IPC setting on ImageWoof, our method requires less than one-twentieth the distillation time of previous methods, yet yields even better performance. Source code available in https://github.com/vimar-gu/MinimaxDiffusion.
Group-wise Sparse and Explainable Adversarial Attacks
Nov 29, 2023Sparse adversarial attacks fool deep neural networks (DNNs) through minimal pixel perturbations, typically regularized by the $\ell_0$ norm. Recent efforts have replaced this norm with a structural sparsity regularizer, such as the nuclear group norm, to craft group-wise sparse adversarial attacks. The resulting perturbations are thus explainable and hold significant practical relevance, shedding light on an even greater vulnerability of DNNs than previously anticipated. However, crafting such attacks poses an optimization challenge, as it involves computing norms for groups of pixels within a non-convex objective. In this paper, we tackle this challenge by presenting an algorithm that simultaneously generates group-wise sparse attacks within semantically meaningful areas of an image. In each iteration, the core operation of our algorithm involves the optimization of a quasinorm adversarial loss. This optimization is achieved by employing the $1/2$-quasinorm proximal operator for some iterations, a method tailored for nonconvex programming. Subsequently, the algorithm transitions to a projected Nesterov's accelerated gradient descent with $2$-norm regularization applied to perturbation magnitudes. We rigorously evaluate the efficacy of our novel attack in both targeted and non-targeted attack scenarios, on CIFAR-10 and ImageNet datasets. When compared to state-of-the-art methods, our attack consistently results in a remarkable increase in group-wise sparsity, e.g., an increase of $48.12\%$ on CIFAR-10 and $40.78\%$ on ImageNet (average case, targeted attack), all while maintaining lower perturbation magnitudes. Notably, this performance is complemented by a significantly faster computation time and a $100\%$ attack success rate.
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model
Nov 29, 2023Identity-consistent video generation seeks to synthesize videos that are guided by both textual prompts and reference images of entities. Current approaches typically utilize cross-attention layers to integrate the appearance of the entity, which predominantly captures semantic attributes, resulting in compromised fidelity of entities. Moreover, these methods necessitate iterative fine-tuning for each new entity encountered, thereby limiting their applicability. To address these challenges, we introduce VideoAssembler, a novel end-to-end framework for identity-consistent video generation that can conduct inference directly when encountering new entities. VideoAssembler is adept at producing videos that are not only flexible with respect to the input reference entities but also responsive to textual conditions. Additionally, by modulating the quantity of input images for the entity, VideoAssembler enables the execution of tasks ranging from image-to-video generation to sophisticated video editing. VideoAssembler comprises two principal components: the Reference Entity Pyramid (REP) encoder and the Entity-Prompt Attention Fusion (EPAF) module. The REP encoder is designed to infuse comprehensive appearance details into the denoising stages of the stable diffusion model. Concurrently, the EPAF module is utilized to integrate text-aligned features effectively. Furthermore, to mitigate the challenge of scarce data, we present a methodology for the preprocessing of training data. Our evaluation of the VideoAssembler framework on the UCF-101, MSR-VTT, and DAVIS datasets indicates that it achieves good performances in both quantitative and qualitative analyses (346.84 in FVD and 48.01 in IS on UCF-101). Our project page is at https://videoassembler.github.io/videoassembler.
Towards Machine Learning-based Quantitative Hyperspectral Image Guidance for Brain Tumor Resection
Nov 17, 2023Complete resection of malignant gliomas is hampered by the difficulty in distinguishing tumor cells at the infiltration zone. Fluorescence guidance with 5-ALA assists in reaching this goal. Using hyperspectral imaging, previous work characterized five fluorophores' emission spectra in most human brain tumors. In this paper, the effectiveness of these five spectra was explored for different tumor and tissue classification tasks in 184 patients (891 hyperspectral measurements) harboring low- (n=30) and high-grade gliomas (n=115), non-glial primary brain tumors (n=19), radiation necrosis (n=2), miscellaneous (n=10) and metastases (n=8). Four machine learning models were trained to classify tumor type, grade, glioma margins and IDH mutation. Using random forests and multi-layer perceptrons, the classifiers achieved average test accuracies of 74-82%, 79%, 81%, and 93% respectively. All five fluorophore abundances varied between tumor margin types and tumor grades (p < 0.01). For tissue type, at least four of the five fluorophore abundances were found to be significantly different (p < 0.01) between all classes. These results demonstrate the fluorophores' differing abundances in different tissue classes, as well as the value of the five fluorophores as potential optical biomarkers, opening new opportunities for intraoperative classification systems in fluorescence-guided neurosurgery.
Spiking Neural Networks with Dynamic Time Steps for Vision Transformers
Nov 28, 2023Spiking Neural Networks (SNNs) have emerged as a popular spatio-temporal computing paradigm for complex vision tasks. Recently proposed SNN training algorithms have significantly reduced the number of time steps (down to 1) for improved latency and energy efficiency, however, they target only convolutional neural networks (CNN). These algorithms, when applied on the recently spotlighted vision transformers (ViT), either require a large number of time steps or fail to converge. Based on analysis of the histograms of the ANN and SNN activation maps, we hypothesize that each ViT block has a different sensitivity to the number of time steps. We propose a novel training framework that dynamically allocates the number of time steps to each ViT module depending on a trainable score assigned to each timestep. In particular, we generate a scalar binary time step mask that filters spikes emitted by each neuron in a leaky-integrate-and-fire (LIF) layer. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), except for the input embedding layer, in contrast to expensive multiply-and-accumulates (MAC) needed in traditional ViTs. This yields significant improvements in energy efficiency. We evaluate our training framework and resulting SNNs on image recognition tasks including CIFAR10, CIFAR100, and ImageNet with different ViT architectures. We obtain a test accuracy of 95.97% with 4.97 time steps with direct encoding on CIFAR10.
Active Open-Vocabulary Recognition: Let Intelligent Moving Mitigate CLIP Limitations
Nov 28, 2023Active recognition, which allows intelligent agents to explore observations for better recognition performance, serves as a prerequisite for various embodied AI tasks, such as grasping, navigation and room arrangements. Given the evolving environment and the multitude of object classes, it is impractical to include all possible classes during the training stage. In this paper, we aim at advancing active open-vocabulary recognition, empowering embodied agents to actively perceive and classify arbitrary objects. However, directly adopting recent open-vocabulary classification models, like Contrastive Language Image Pretraining (CLIP), poses its unique challenges. Specifically, we observe that CLIP's performance is heavily affected by the viewpoint and occlusions, compromising its reliability in unconstrained embodied perception scenarios. Further, the sequential nature of observations in agent-environment interactions necessitates an effective method for integrating features that maintains discriminative strength for open-vocabulary classification. To address these issues, we introduce a novel agent for active open-vocabulary recognition. The proposed method leverages inter-frame and inter-concept similarities to navigate agent movements and to fuse features, without relying on class-specific knowledge. Compared to baseline CLIP model with 29.6% accuracy on ShapeNet dataset, the proposed agent could achieve 53.3% accuracy for open-vocabulary recognition, without any fine-tuning to the equipped CLIP model. Additional experiments conducted with the Habitat simulator further affirm the efficacy of our method.
Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld
Nov 28, 2023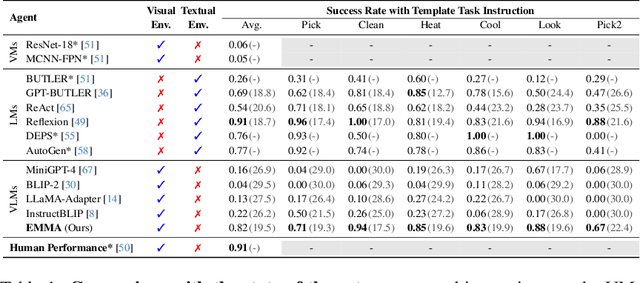
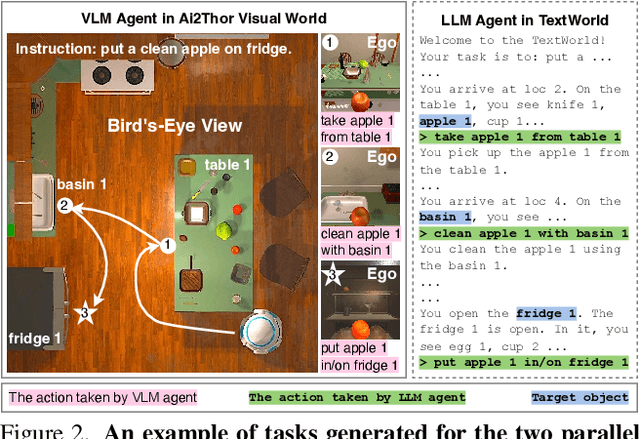
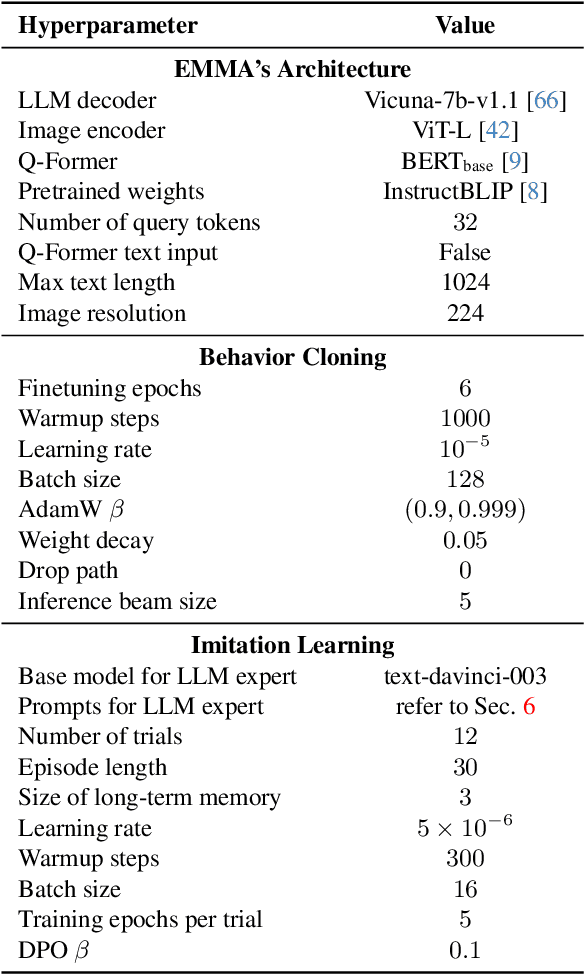
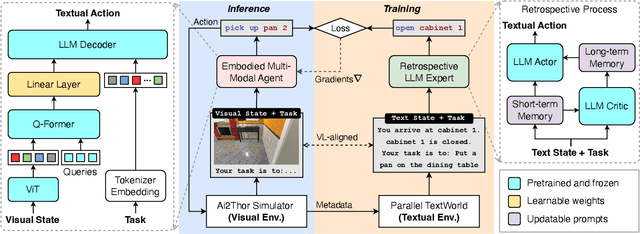
While large language models (LLMs) excel in a simulated world of texts, they struggle to interact with the more realistic world without perceptions of other modalities such as visual or audio signals. Although vision-language models (VLMs) integrate LLM modules (1) aligned with static image features, and (2) may possess prior knowledge of world dynamics (as demonstrated in the text world), they have not been trained in an embodied visual world and thus cannot align with its dynamics. On the other hand, training an embodied agent in a noisy visual world without expert guidance is often challenging and inefficient. In this paper, we train a VLM agent living in a visual world using an LLM agent excelling in a parallel text world (but inapplicable to the visual world). Specifically, we distill LLM's reflection outcomes (improved actions by analyzing mistakes) in a text world's tasks to finetune the VLM on the same tasks of the visual world, resulting in an Embodied Multi-Modal Agent (EMMA) quickly adapting to the visual world dynamics. Such cross-modality imitation learning between the two parallel worlds enables EMMA to generalize to a broad scope of new tasks without any further guidance from the LLM expert. Extensive evaluations on the ALFWorld benchmark highlight EMMA's superior performance to SOTA VLM-based agents across diverse tasks, e.g., 20%-70% improvement in the success rate.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Nov 20, 2023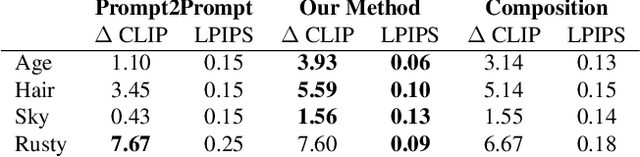
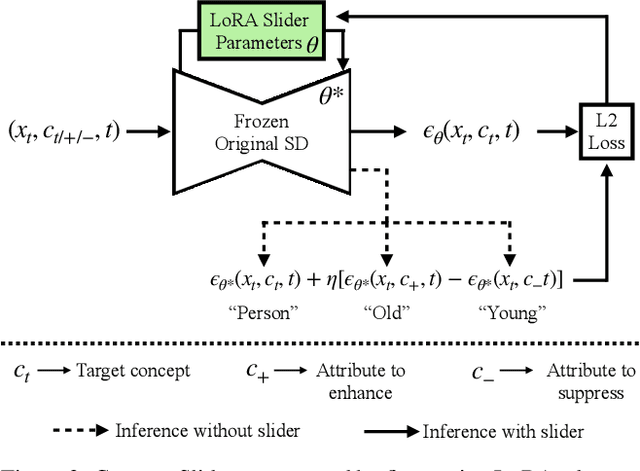


We present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. Our approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes. A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments comparing to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference. We showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at https://sliders.baulab.info/
DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation
Oct 19, 2023Great progress has been made in automatic medical image segmentation due to powerful deep representation learning. The influence of transformer has led to research into its variants, and large-scale replacement of traditional CNN modules. However, such trend often overlooks the intrinsic feature extraction capabilities of the transformer and potential refinements to both the model and the transformer module through minor adjustments. This study proposes a novel deep medical image segmentation framework, called DA-TransUNet, aiming to introduce the Transformer and dual attention block into the encoder and decoder of the traditional U-shaped architecture. Unlike prior transformer-based solutions, our DA-TransUNet utilizes attention mechanism of transformer and multifaceted feature extraction of DA-Block, which can efficiently combine global, local, and multi-scale features to enhance medical image segmentation. Meanwhile, experimental results show that a dual attention block is added before the Transformer layer to facilitate feature extraction in the U-net structure. Furthermore, incorporating dual attention blocks in skip connections can enhance feature transfer to the decoder, thereby improving image segmentation performance. Experimental results across various benchmark of medical image segmentation reveal that DA-TransUNet significantly outperforms the state-of-the-art methods. The codes and parameters of our model will be publicly available at https://github.com/SUN-1024/DA-TransUnet.
PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
Oct 16, 2023Although supervised image denoising networks have shown remarkable performance on synthesized noisy images, they often fail in practice due to the difference between real and synthesized noise. Since clean-noisy image pairs from the real world are extremely costly to gather, self-supervised learning, which utilizes noisy input itself as a target, has been studied. To prevent a self-supervised denoising model from learning identical mapping, each output pixel should not be influenced by its corresponding input pixel; This requirement is known as J-invariance. Blind-spot networks (BSNs) have been a prevalent choice to ensure J-invariance in self-supervised image denoising. However, constructing variations of BSNs by injecting additional operations such as downsampling can expose blinded information, thereby violating J-invariance. Consequently, convolutions designed specifically for BSNs have been allowed only, limiting architectural flexibility. To overcome this limitation, we propose PUCA, a novel J-invariant U-Net architecture, for self-supervised denoising. PUCA leverages patch-unshuffle/shuffle to dramatically expand receptive fields while maintaining J-invariance and dilated attention blocks (DABs) for global context incorporation. Experimental results demonstrate that PUCA achieves state-of-the-art performance, outperforming existing methods in self-supervised image denoising.