 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld
Nov 28, 2023
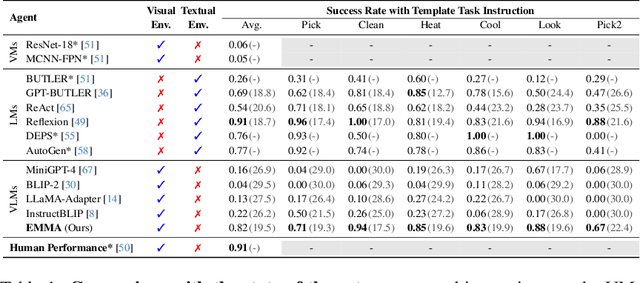
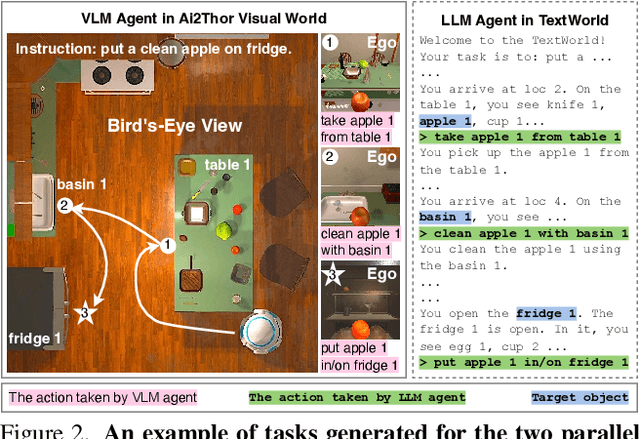
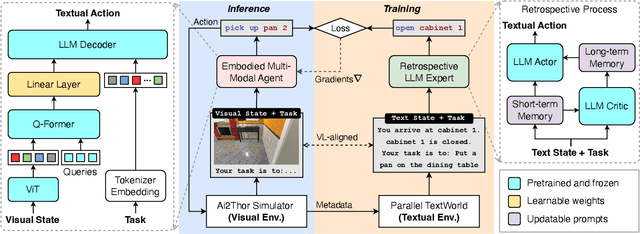
While large language models (LLMs) excel in a simulated world of texts, they struggle to interact with the more realistic world without perceptions of other modalities such as visual or audio signals. Although vision-language models (VLMs) integrate LLM modules (1) aligned with static image features, and (2) may possess prior knowledge of world dynamics (as demonstrated in the text world), they have not been trained in an embodied visual world and thus cannot align with its dynamics. On the other hand, training an embodied agent in a noisy visual world without expert guidance is often challenging and inefficient. In this paper, we train a VLM agent living in a visual world using an LLM agent excelling in a parallel text world (but inapplicable to the visual world). Specifically, we distill LLM's reflection outcomes (improved actions by analyzing mistakes) in a text world's tasks to finetune the VLM on the same tasks of the visual world, resulting in an Embodied Multi-Modal Agent (EMMA) quickly adapting to the visual world dynamics. Such cross-modality imitation learning between the two parallel worlds enables EMMA to generalize to a broad scope of new tasks without any further guidance from the LLM expert. Extensive evaluations on the ALFWorld benchmark highlight EMMA's superior performance to SOTA VLM-based agents across diverse tasks, e.g., 20%-70% improvement in the success rate.
Spiking Neural Networks with Dynamic Time Steps for Vision Transformers
Nov 28, 2023Spiking Neural Networks (SNNs) have emerged as a popular spatio-temporal computing paradigm for complex vision tasks. Recently proposed SNN training algorithms have significantly reduced the number of time steps (down to 1) for improved latency and energy efficiency, however, they target only convolutional neural networks (CNN). These algorithms, when applied on the recently spotlighted vision transformers (ViT), either require a large number of time steps or fail to converge. Based on analysis of the histograms of the ANN and SNN activation maps, we hypothesize that each ViT block has a different sensitivity to the number of time steps. We propose a novel training framework that dynamically allocates the number of time steps to each ViT module depending on a trainable score assigned to each timestep. In particular, we generate a scalar binary time step mask that filters spikes emitted by each neuron in a leaky-integrate-and-fire (LIF) layer. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), except for the input embedding layer, in contrast to expensive multiply-and-accumulates (MAC) needed in traditional ViTs. This yields significant improvements in energy efficiency. We evaluate our training framework and resulting SNNs on image recognition tasks including CIFAR10, CIFAR100, and ImageNet with different ViT architectures. We obtain a test accuracy of 95.97% with 4.97 time steps with direct encoding on CIFAR10.
An Innovative Tool for Uploading/Scraping Large Image Datasets on Social Networks
Nov 01, 2023Nowadays, people can retrieve and share digital information in an increasingly easy and fast fashion through the well-known digital platforms, including sensitive data, inappropriate or illegal content, and, in general, information that might serve as probative evidence in court. Consequently, to assess forensics issues, we need to figure out how to trace back to the posting chain of a digital evidence (e.g., a picture, an audio) throughout the involved platforms -- this is what Digital (also Forensics) Ballistics basically deals with. With the entry of Machine Learning as a tool of the trade in many research areas, the need for vast amounts of data has been dramatically increasing over the last few years. However, collecting or simply find the "right" datasets that properly enables data-driven research studies can turn out to be not trivial in some cases, if not extremely challenging, especially when it comes with highly specialized tasks, such as creating datasets analyzed to detect the source media platform of a given digital media. In this paper we propose an automated approach by means of a digital tool that we created on purpose. The tool is capable of automatically uploading an entire image dataset to the desired digital platform and then downloading all the uploaded pictures, thus shortening the overall time required to output the final dataset to be analyzed.
A Principled Hierarchical Deep Learning Approach to Joint Image Compression and Classification
Oct 30, 2023Among applications of deep learning (DL) involving low cost sensors, remote image classification involves a physical channel that separates edge sensors and cloud classifiers. Traditional DL models must be divided between an encoder for the sensor and the decoder + classifier at the edge server. An important challenge is to effectively train such distributed models when the connecting channels have limited rate/capacity. Our goal is to optimize DL models such that the encoder latent requires low channel bandwidth while still delivers feature information for high classification accuracy. This work proposes a three-step joint learning strategy to guide encoders to extract features that are compact, discriminative, and amenable to common augmentations/transformations. We optimize latent dimension through an initial screening phase before end-to-end (E2E) training. To obtain an adjustable bit rate via a single pre-deployed encoder, we apply entropy-based quantization and/or manual truncation on the latent representations. Tests show that our proposed method achieves accuracy improvement of up to 1.5% on CIFAR-10 and 3% on CIFAR-100 over conventional E2E cross-entropy training.
Towards Machine Learning-based Quantitative Hyperspectral Image Guidance for Brain Tumor Resection
Nov 17, 2023Complete resection of malignant gliomas is hampered by the difficulty in distinguishing tumor cells at the infiltration zone. Fluorescence guidance with 5-ALA assists in reaching this goal. Using hyperspectral imaging, previous work characterized five fluorophores' emission spectra in most human brain tumors. In this paper, the effectiveness of these five spectra was explored for different tumor and tissue classification tasks in 184 patients (891 hyperspectral measurements) harboring low- (n=30) and high-grade gliomas (n=115), non-glial primary brain tumors (n=19), radiation necrosis (n=2), miscellaneous (n=10) and metastases (n=8). Four machine learning models were trained to classify tumor type, grade, glioma margins and IDH mutation. Using random forests and multi-layer perceptrons, the classifiers achieved average test accuracies of 74-82%, 79%, 81%, and 93% respectively. All five fluorophore abundances varied between tumor margin types and tumor grades (p < 0.01). For tissue type, at least four of the five fluorophore abundances were found to be significantly different (p < 0.01) between all classes. These results demonstrate the fluorophores' differing abundances in different tissue classes, as well as the value of the five fluorophores as potential optical biomarkers, opening new opportunities for intraoperative classification systems in fluorescence-guided neurosurgery.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Nov 20, 2023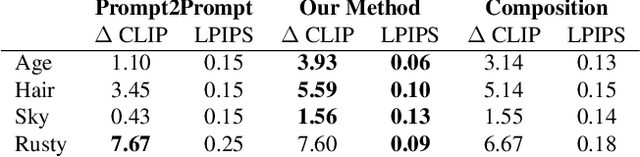
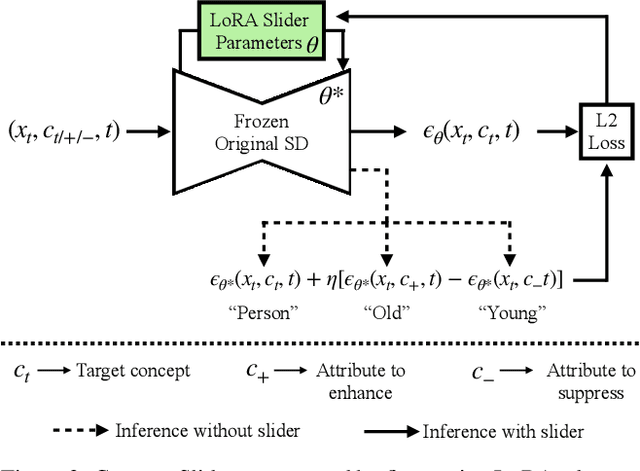


We present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. Our approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes. A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments comparing to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference. We showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at https://sliders.baulab.info/
Nighttime Thermal Infrared Image Colorization with Feedback-based Object Appearance Learning
Oct 24, 2023Stable imaging in adverse environments (e.g., total darkness) makes thermal infrared (TIR) cameras a prevalent option for night scene perception. However, the low contrast and lack of chromaticity of TIR images are detrimental to human interpretation and subsequent deployment of RGB-based vision algorithms. Therefore, it makes sense to colorize the nighttime TIR images by translating them into the corresponding daytime color images (NTIR2DC). Despite the impressive progress made in the NTIR2DC task, how to improve the translation performance of small object classes is under-explored. To address this problem, we propose a generative adversarial network incorporating feedback-based object appearance learning (FoalGAN). Specifically, an occlusion-aware mixup module and corresponding appearance consistency loss are proposed to reduce the context dependence of object translation. As a representative example of small objects in nighttime street scenes, we illustrate how to enhance the realism of traffic light by designing a traffic light appearance loss. To further improve the appearance learning of small objects, we devise a dual feedback learning strategy to selectively adjust the learning frequency of different samples. In addition, we provide pixel-level annotation for a subset of the Brno dataset, which can facilitate the research of NTIR image understanding under multiple weather conditions. Extensive experiments illustrate that the proposed FoalGAN is not only effective for appearance learning of small objects, but also outperforms other image translation methods in terms of semantic preservation and edge consistency for the NTIR2DC task.
Generating Human-Centric Visual Cues for Human-Object Interaction Detection via Large Vision-Language Models
Nov 26, 2023Human-object interaction (HOI) detection aims at detecting human-object pairs and predicting their interactions. However, the complexity of human behavior and the diverse contexts in which these interactions occur make it challenging. Intuitively, human-centric visual cues, such as the involved participants, the body language, and the surrounding environment, play crucial roles in shaping these interactions. These cues are particularly vital in interpreting unseen interactions. In this paper, we propose three prompts with VLM to generate human-centric visual cues within an image from multiple perspectives of humans. To capitalize on these rich Human-Centric Visual Cues, we propose a novel approach named HCVC for HOI detection. Particularly, we develop a transformer-based multimodal fusion module with multitower architecture to integrate visual cue features into the instance and interaction decoders. Our extensive experiments and analysis validate the efficacy of leveraging the generated human-centric visual cues for HOI detection. Notably, the experimental results indicate the superiority of the proposed model over the existing state-of-the-art methods on two widely used datasets.
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 26, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
Image-Based Soil Organic Carbon Remote Sensing from Satellite Images with Fourier Neural Operator and Structural Similarity
Nov 21, 2023Soil organic carbon (SOC) sequestration is the transfer and storage of atmospheric carbon dioxide in soils, which plays an important role in climate change mitigation. SOC concentration can be improved by proper land use, thus it is beneficial if SOC can be estimated at a regional or global scale. As multispectral satellite data can provide SOC-related information such as vegetation and soil properties at a global scale, estimation of SOC through satellite data has been explored as an alternative to manual soil sampling. Although existing studies show promising results, they are mainly based on pixel-based approaches with traditional machine learning methods, and convolutional neural networks (CNNs) are uncommon. To study the use of CNNs on SOC remote sensing, here we propose the FNO-DenseNet based on the Fourier neural operator (FNO). By combining the advantages of the FNO and DenseNet, the FNO-DenseNet outperformed the FNO in our experiments with hundreds of times fewer parameters. The FNO-DenseNet also outperformed a pixel-based random forest by 18% in the mean absolute percentage error.