 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Nov 28, 2023
In the realm of large multi-modal models (LMMs), efficient modality alignment is crucial yet often constrained by the scarcity of high-quality image-text data. To address this bottleneck, we introduce the ShareGPT4V dataset, a pioneering large-scale resource featuring 1.2 million highly descriptive captions, which surpasses existing datasets in diversity and information content, covering world knowledge, object properties, spatial relationships, and aesthetic evaluations. Specifically, ShareGPT4V originates from a curated 100K high-quality captions collected from advanced GPT4-Vision and has been expanded to 1.2M with a superb caption model trained on this subset. ShareGPT4V first demonstrates its effectiveness for the Supervised Fine-Tuning (SFT) phase, by substituting an equivalent quantity of detailed captions in existing SFT datasets with a subset of our high-quality captions, significantly enhancing the LMMs like LLaVA-7B, LLaVA-1.5-13B, and Qwen-VL-Chat-7B on the MME and MMBench benchmarks, with respective gains of 222.8/22.0/22.3 and 2.7/1.3/1.5. We further incorporate ShareGPT4V data into both the pre-training and SFT phases, obtaining ShareGPT4V-7B, a superior LMM based on a simple architecture that has remarkable performance across a majority of the multi-modal benchmarks. This project is available at https://ShareGPT4V.github.io to serve as a pivotal resource for advancing the LMMs community.
ID-like Prompt Learning for Few-Shot Out-of-Distribution Detection
Nov 28, 2023
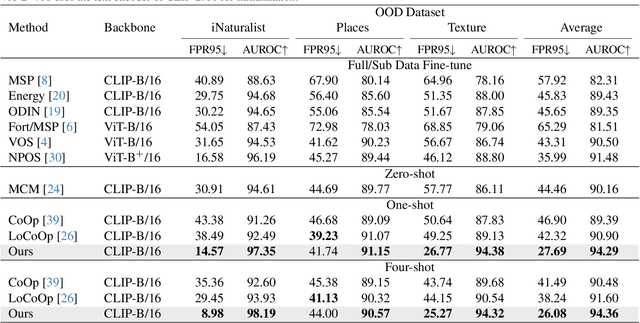
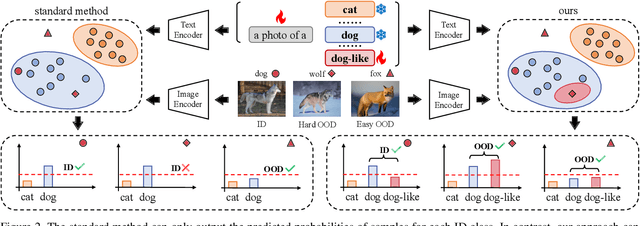

Out-of-distribution (OOD) detection methods often exploit auxiliary outliers to train model identifying OOD samples, especially discovering challenging outliers from auxiliary outliers dataset to improve OOD detection. However, they may still face limitations in effectively distinguishing between the most challenging OOD samples that are much like in-distribution (ID) data, i.e., ID-like samples. To this end, we propose a novel OOD detection framework that discovers ID-like outliers using CLIP from the vicinity space of the ID samples, thus helping to identify these most challenging OOD samples. Then a prompt learning framework is proposed that utilizes the identified ID-like outliers to further leverage the capabilities of CLIP for OOD detection. Benefiting from the powerful CLIP, we only need a small number of ID samples to learn the prompts of the model without exposing other auxiliary outlier datasets. By focusing on the most challenging ID-like OOD samples and elegantly exploiting the capabilities of CLIP, our method achieves superior few-shot learning performance on various real-world image datasets (e.g., in 4-shot OOD detection on the ImageNet-1k dataset, our method reduces the average FPR95 by 12.16% and improves the average AUROC by 2.76%, compared to state-of-the-art methods).
Rethinking Directional Integration in Neural Radiance Fields
Nov 28, 2023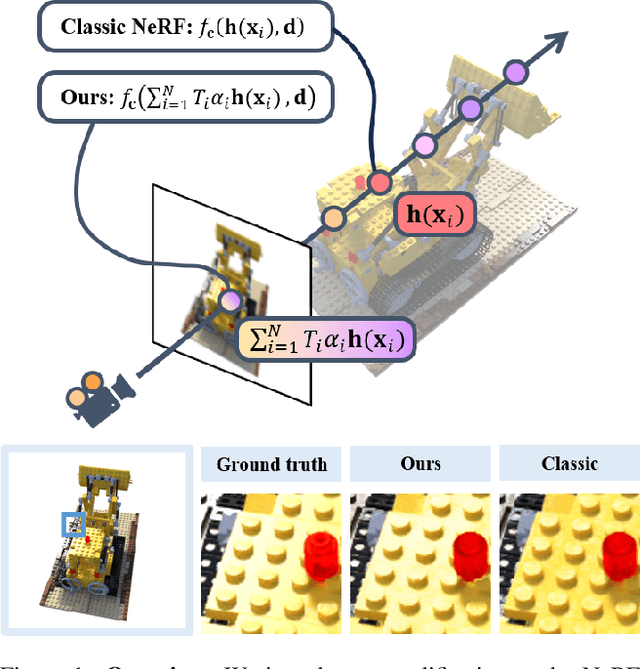
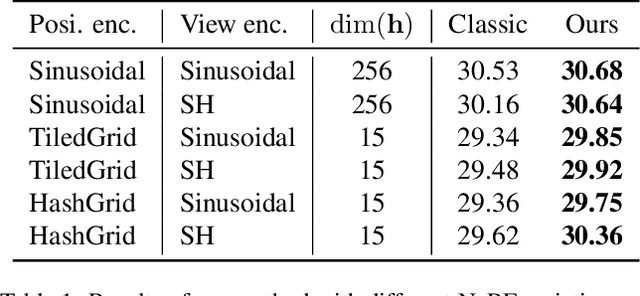

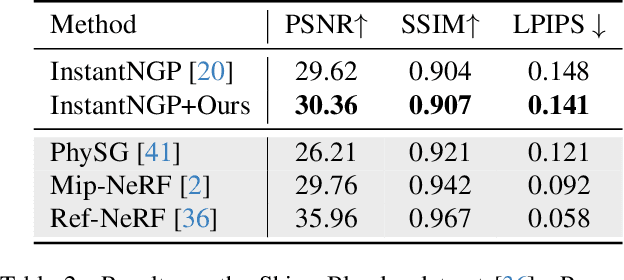
Recent works use the Neural radiance field (NeRF) to perform multi-view 3D reconstruction, providing a significant leap in rendering photorealistic scenes. However, despite its efficacy, NeRF exhibits limited capability of learning view-dependent effects compared to light field rendering or image-based view synthesis. To that end, we introduce a modification to the NeRF rendering equation which is as simple as a few lines of code change for any NeRF variations, while greatly improving the rendering quality of view-dependent effects. By swapping the integration operator and the direction decoder network, we only integrate the positional features along the ray and move the directional terms out of the integration, resulting in a disentanglement of the view-dependent and independent components. The modified equation is equivalent to the classical volumetric rendering in ideal cases on object surfaces with Dirac densities. Furthermore, we prove that with the errors caused by network approximation and numerical integration, our rendering equation exhibits better convergence properties with lower error accumulations compared to the classical NeRF. We also show that the modified equation can be interpreted as light field rendering with learned ray embeddings. Experiments on different NeRF variations show consistent improvements in the quality of view-dependent effects with our simple modification.
Exploring Straighter Trajectories of Flow Matching with Diffusion Guidance
Nov 28, 2023Flow matching as a paradigm of generative model achieves notable success across various domains. However, existing methods use either multi-round training or knowledge within minibatches, posing challenges in finding a favorable coupling strategy for straight trajectories. To address this issue, we propose a novel approach, Straighter trajectories of Flow Matching (StraightFM). It straightens trajectories with the coupling strategy guided by diffusion model from entire distribution level. First, we propose a coupling strategy to straighten trajectories, creating couplings between image and noise samples under diffusion model guidance. Second, StraightFM also integrates real data to enhance training, employing a neural network to parameterize another coupling process from images to noise samples. StraightFM is jointly optimized with couplings from above two mutually complementary directions, resulting in straighter trajectories and enabling both one-step and few-step generation. Extensive experiments demonstrate that StraightFM yields high quality samples with fewer step. StraightFM generates visually appealing images with a lower FID among diffusion and traditional flow matching methods within 5 sampling steps when trained on pixel space. In the latent space (i.e., Latent Diffusion), StraightFM achieves a lower KID value compared to existing methods on the CelebA-HQ 256 dataset in fewer than 10 sampling steps.
Federated Learning with Diffusion Models for Privacy-Sensitive Vision Tasks
Nov 28, 2023Diffusion models have shown great potential for vision-related tasks, particularly for image generation. However, their training is typically conducted in a centralized manner, relying on data collected from publicly available sources. This approach may not be feasible or practical in many domains, such as the medical field, which involves privacy concerns over data collection. Despite the challenges associated with privacy-sensitive data, such domains could still benefit from valuable vision services provided by diffusion models. Federated learning (FL) plays a crucial role in enabling decentralized model training without compromising data privacy. Instead of collecting data, an FL system gathers model parameters, effectively safeguarding the private data of different parties involved. This makes FL systems vital for managing decentralized learning tasks, especially in scenarios where privacy-sensitive data is distributed across a network of clients. Nonetheless, FL presents its own set of challenges due to its distributed nature and privacy-preserving properties. Therefore, in this study, we explore the FL strategy to train diffusion models, paving the way for the development of federated diffusion models. We conduct experiments on various FL scenarios, and our findings demonstrate that federated diffusion models have great potential to deliver vision services to privacy-sensitive domains.
Typhoon Intensity Prediction with Vision Transformer
Nov 28, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
Multi-delay arterial spin-labeled perfusion estimation with biophysics simulation and deep learning
Nov 17, 2023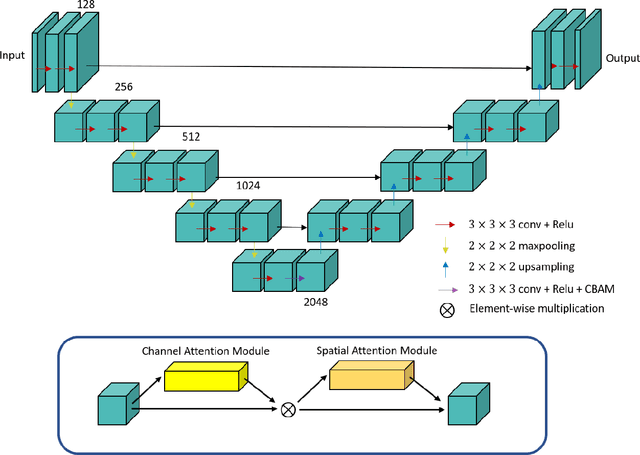
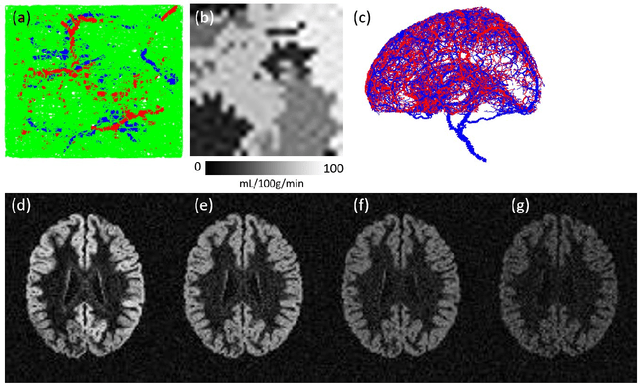
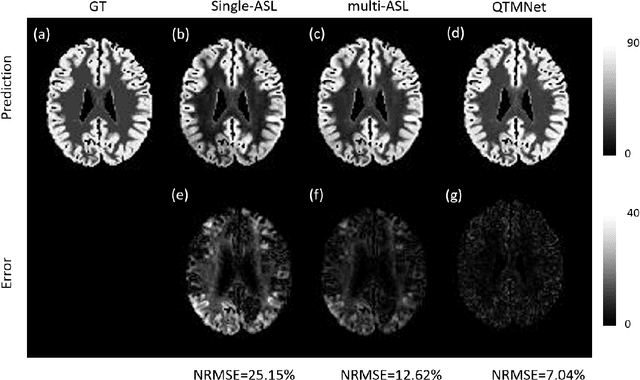
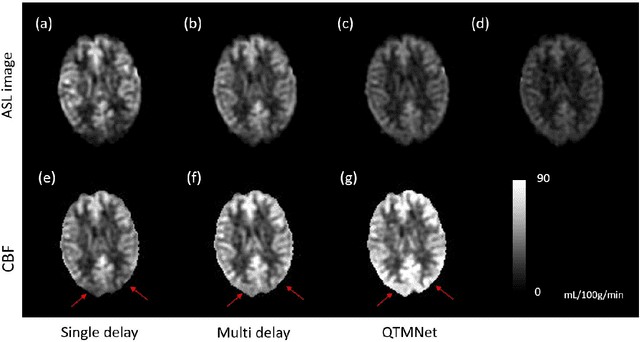
Purpose: To develop biophysics-based method for estimating perfusion Q from arterial spin labeling (ASL) images using deep learning. Methods: A 3D U-Net (QTMnet) was trained to estimate perfusion from 4D tracer propagation images. The network was trained and tested on simulated 4D tracer concentration data based on artificial vasculature structure generated by constrained constructive optimization (CCO) method. The trained network was further tested in a synthetic brain ASL image based on vasculature network extracted from magnetic resonance (MR) angiography. The estimations from both trained network and a conventional kinetic model were compared in ASL images acquired from eight healthy volunteers. Results: QTMnet accurately reconstructed perfusion Q from concentration data. Relative error of the synthetic brain ASL image was 7.04% for perfusion Q, lower than the error using single-delay ASL model: 25.15% for Q, and multi-delay ASL model: 12.62% for perfusion Q. Conclusion: QTMnet provides accurate estimation on perfusion parameters and is a promising approach as a clinical ASL MRI image processing pipeline.
SENetV2: Aggregated dense layer for channelwise and global representations
Nov 17, 2023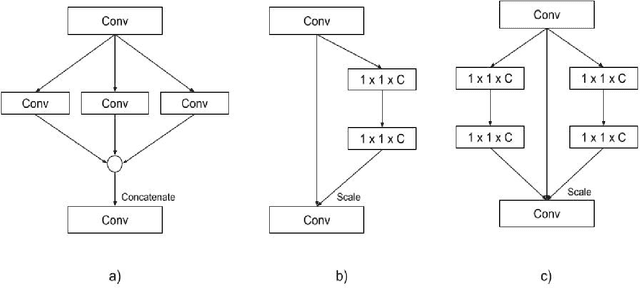
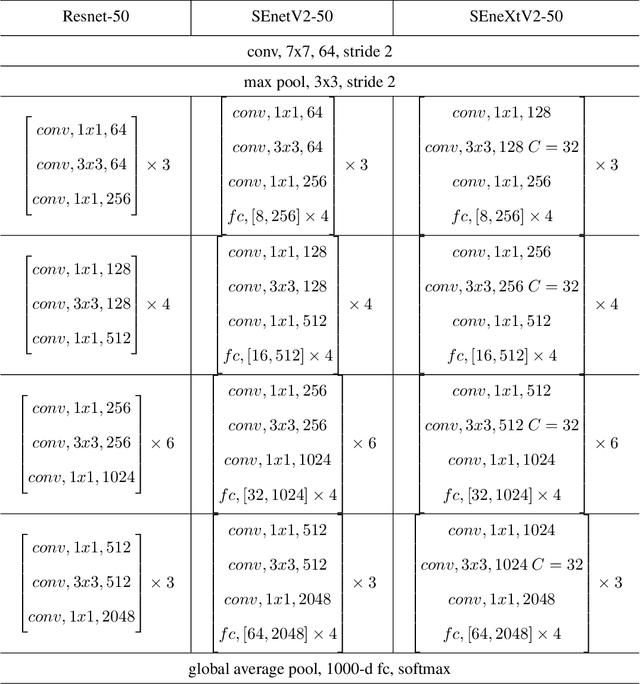
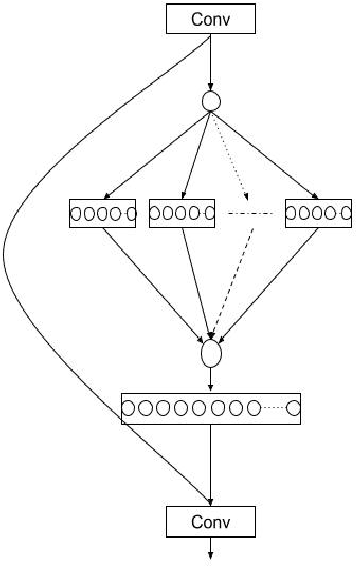
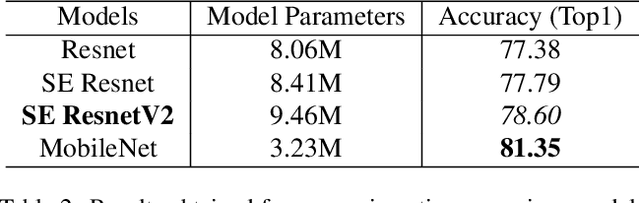
Convolutional Neural Networks (CNNs) have revolutionized image classification by extracting spatial features and enabling state-of-the-art accuracy in vision-based tasks. The squeeze and excitation network proposed module gathers channelwise representations of the input. Multilayer perceptrons (MLP) learn global representation from the data and in most image classification models used to learn extracted features of the image. In this paper, we introduce a novel aggregated multilayer perceptron, a multi-branch dense layer, within the Squeeze excitation residual module designed to surpass the performance of existing architectures. Our approach leverages a combination of squeeze excitation network module with dense layers. This fusion enhances the network's ability to capture channel-wise patterns and have global knowledge, leading to a better feature representation. This proposed model has a negligible increase in parameters when compared to SENet. We conduct extensive experiments on benchmark datasets to validate the model and compare them with established architectures. Experimental results demonstrate a remarkable increase in the classification accuracy of the proposed model.
The Solution for the CVPR2023 NICE Image Captioning Challenge
Oct 10, 2023

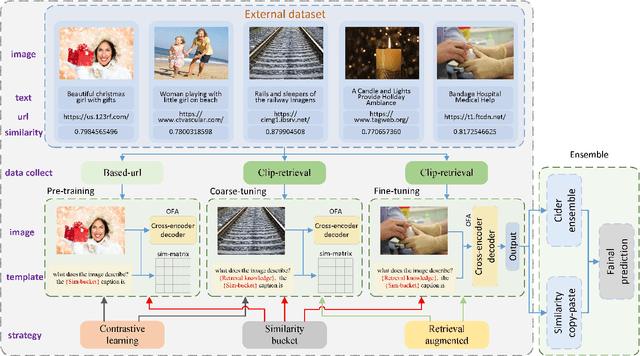
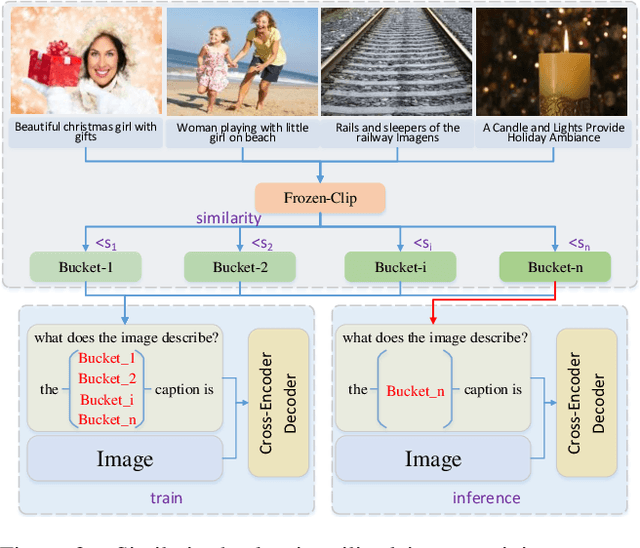
In this paper, we present our solution to the New frontiers for Zero-shot Image Captioning Challenge. Different from the traditional image captioning datasets, this challenge includes a larger new variety of visual concepts from many domains (such as COVID-19) as well as various image types (photographs, illustrations, graphics). For the data level, we collect external training data from Laion-5B, a large-scale CLIP-filtered image-text dataset. For the model level, we use OFA, a large-scale visual-language pre-training model based on handcrafted templates, to perform the image captioning task. In addition, we introduce contrastive learning to align image-text pairs to learn new visual concepts in the pre-training stage. Then, we propose a similarity-bucket strategy and incorporate this strategy into the template to force the model to generate higher quality and more matching captions. Finally, by retrieval-augmented strategy, we construct a content-rich template, containing the most relevant top-k captions from other image-text pairs, to guide the model in generating semantic-rich captions. Our method ranks first on the leaderboard, achieving 105.17 and 325.72 Cider-Score in the validation and test phase, respectively.
Generalizing Medical Image Representations via Quaternion Wavelet Networks
Oct 16, 2023Neural network generalizability is becoming a broad research field due to the increasing availability of datasets from different sources and for various tasks. This issue is even wider when processing medical data, where a lack of methodological standards causes large variations being provided by different imaging centers or acquired with various devices and cofactors. To overcome these limitations, we introduce a novel, generalizable, data- and task-agnostic framework able to extract salient features from medical images. The proposed quaternion wavelet network (QUAVE) can be easily integrated with any pre-existing medical image analysis or synthesis task, and it can be involved with real, quaternion, or hypercomplex-valued models, generalizing their adoption to single-channel data. QUAVE first extracts different sub-bands through the quaternion wavelet transform, resulting in both low-frequency/approximation bands and high-frequency/fine-grained features. Then, it weighs the most representative set of sub-bands to be involved as input to any other neural model for image processing, replacing standard data samples. We conduct an extensive experimental evaluation comprising different datasets, diverse image analysis, and synthesis tasks including reconstruction, segmentation, and modality translation. We also evaluate QUAVE in combination with both real and quaternion-valued models. Results demonstrate the effectiveness and the generalizability of the proposed framework that improves network performance while being flexible to be adopted in manifold scenarios.