 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comparative Study of Image Restoration Networks for General Backbone Network Design
Oct 18, 2023
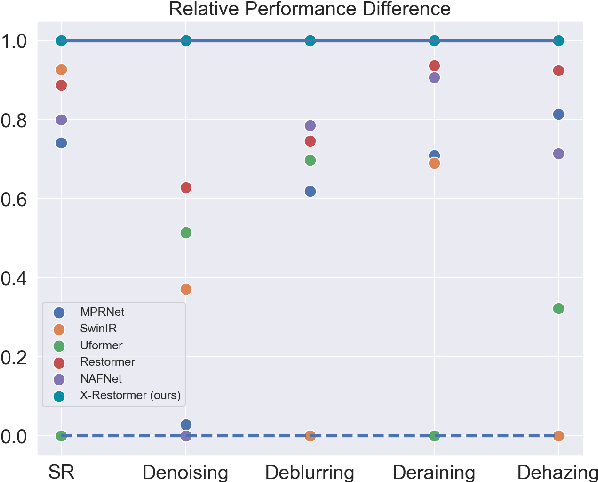
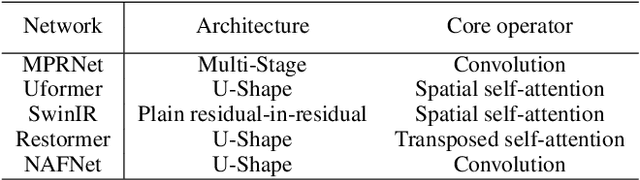


Despite the significant progress made by deep models in various image restoration tasks, existing image restoration networks still face challenges in terms of task generality. An intuitive manifestation is that networks which excel in certain tasks often fail to deliver satisfactory results in others. To illustrate this point, we select five representative image restoration networks and conduct a comparative study on five classic image restoration tasks. First, we provide a detailed explanation of the characteristics of different image restoration tasks and backbone networks. Following this, we present the benchmark results and analyze the reasons behind the performance disparity of different models across various tasks. Drawing from this comparative study, we propose that a general image restoration backbone network needs to meet the functional requirements of diverse tasks. Based on this principle, we design a new general image restoration backbone network, X-Restormer. Extensive experiments demonstrate that X-Restormer possesses good task generality and achieves state-of-the-art performance across a variety of tasks.
SingleInsert: Inserting New Concepts from a Single Image into Text-to-Image Models for Flexible Editing
Oct 12, 2023
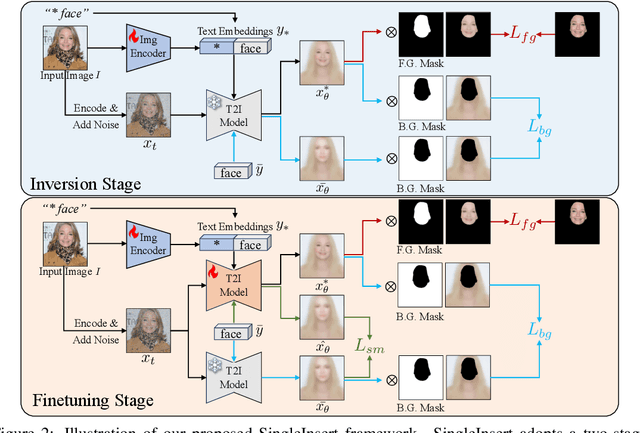


Recent progress in text-to-image (T2I) models enables high-quality image generation with flexible textual control. To utilize the abundant visual priors in the off-the-shelf T2I models, a series of methods try to invert an image to proper embedding that aligns with the semantic space of the T2I model. However, these image-to-text (I2T) inversion methods typically need multiple source images containing the same concept or struggle with the imbalance between editing flexibility and visual fidelity. In this work, we point out that the critical problem lies in the foreground-background entanglement when learning an intended concept, and propose a simple and effective baseline for single-image I2T inversion, named SingleInsert. SingleInsert adopts a two-stage scheme. In the first stage, we regulate the learned embedding to concentrate on the foreground area without being associated with the irrelevant background. In the second stage, we finetune the T2I model for better visual resemblance and devise a semantic loss to prevent the language drift problem. With the proposed techniques, SingleInsert excels in single concept generation with high visual fidelity while allowing flexible editing. Additionally, SingleInsert can perform single-image novel view synthesis and multiple concepts composition without requiring joint training. To facilitate evaluation, we design an editing prompt list and introduce a metric named Editing Success Rate (ESR) for quantitative assessment of editing flexibility. Our project page is: https://jarrentwu1031.github.io/SingleInsert-web/
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023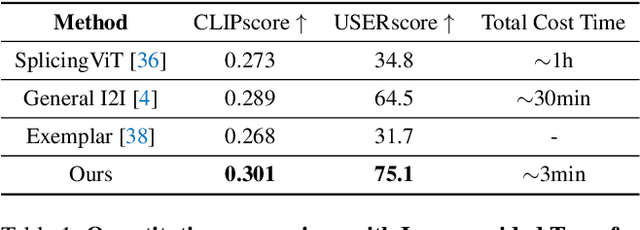

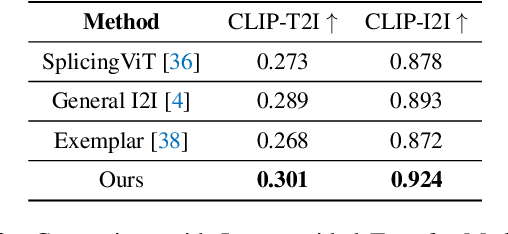
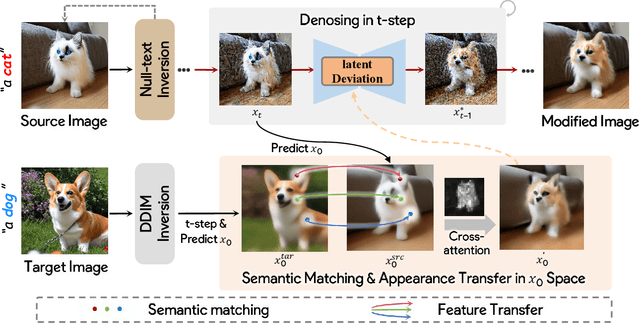
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer
SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
Nov 27, 2023In semi-supervised semantic segmentation, a model is trained with a limited number of labeled images along with a large corpus of unlabeled images to reduce the high annotation effort. While previous methods are able to learn good segmentation boundaries, they are prone to confuse classes with similar visual appearance due to the limited supervision. On the other hand, vision-language models (VLMs) are able to learn diverse semantic knowledge from image-caption datasets but produce noisy segmentation due to the image-level training. In SemiVL, we propose to integrate rich priors from VLM pre-training into semi-supervised semantic segmentation to learn better semantic decision boundaries. To adapt the VLM from global to local reasoning, we introduce a spatial fine-tuning strategy for label-efficient learning. Further, we design a language-guided decoder to jointly reason over vision and language. Finally, we propose to handle inherent ambiguities in class labels by providing the model with language guidance in the form of class definitions. We evaluate SemiVL on 4 semantic segmentation datasets, where it significantly outperforms previous semi-supervised methods. For instance, SemiVL improves the state-of-the-art by +13.5 mIoU on COCO with 232 annotated images and by +6.1 mIoU on Pascal VOC with 92 labels. Project page: https://github.com/google-research/semivl
Machine Learning-Based Jamun Leaf Disease Detection: A Comprehensive Review
Nov 27, 2023Jamun leaf diseases pose a significant threat to agricultural productivity, negatively impacting both yield and quality in the jamun industry. The advent of machine learning has opened up new avenues for tackling these diseases effectively. Early detection and diagnosis are essential for successful crop management. While no automated systems have yet been developed specifically for jamun leaf disease detection, various automated systems have been implemented for similar types of disease detection using image processing techniques. This paper presents a comprehensive review of machine learning methodologies employed for diagnosing plant leaf diseases through image classification, which can be adapted for jamun leaf disease detection. It meticulously assesses the strengths and limitations of various Vision Transformer models, including Transfer learning model and vision transformer (TLMViT), SLViT, SE-ViT, IterationViT, Tiny-LeViT, IEM-ViT, GreenViT, and PMViT. Additionally, the paper reviews models such as Dense Convolutional Network (DenseNet), Residual Neural Network (ResNet)-50V2, EfficientNet, Ensemble model, Convolutional Neural Network (CNN), and Locally Reversible Transformer. These machine-learning models have been evaluated on various datasets, demonstrating their real-world applicability. This review not only sheds light on current advancements in the field but also provides valuable insights for future research directions in machine learning-based jamun leaf disease detection and classification.
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
DreamCreature: Crafting Photorealistic Virtual Creatures from Imagination
Nov 27, 2023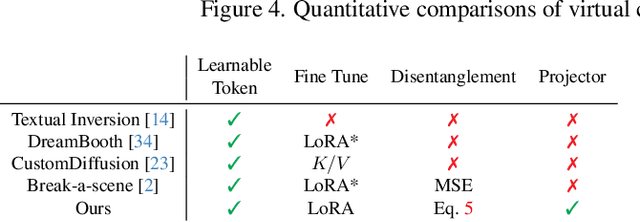

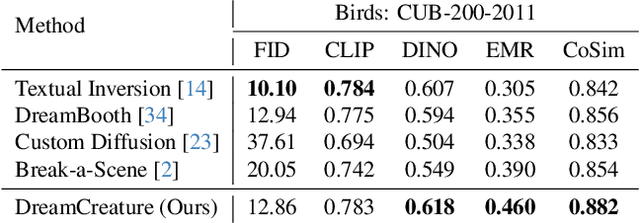
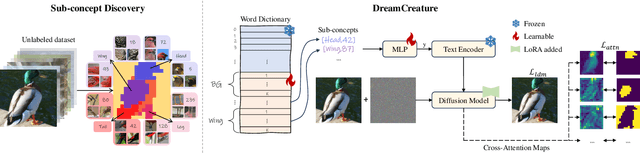
Recent text-to-image (T2I) generative models allow for high-quality synthesis following either text instructions or visual examples. Despite their capabilities, these models face limitations in creating new, detailed creatures within specific categories (e.g., virtual dog or bird species), which are valuable in digital asset creation and biodiversity analysis. To bridge this gap, we introduce a novel task, Virtual Creatures Generation: Given a set of unlabeled images of the target concepts (e.g., 200 bird species), we aim to train a T2I model capable of creating new, hybrid concepts within diverse backgrounds and contexts. We propose a new method called DreamCreature, which identifies and extracts the underlying sub-concepts (e.g., body parts of a specific species) in an unsupervised manner. The T2I thus adapts to generate novel concepts (e.g., new bird species) with faithful structures and photorealistic appearance by seamlessly and flexibly composing learned sub-concepts. To enhance sub-concept fidelity and disentanglement, we extend the textual inversion technique by incorporating an additional projector and tailored attention loss regularization. Extensive experiments on two fine-grained image benchmarks demonstrate the superiority of DreamCreature over prior methods in both qualitative and quantitative evaluation. Ultimately, the learned sub-concepts facilitate diverse creative applications, including innovative consumer product designs and nuanced property modifications.
Volumetric Rendering with Baked Quadrature Fields
Dec 02, 2023We propose a novel Neural Radiance Field (NeRF) representation for non-opaque scenes that allows fast inference by utilizing textured polygons. Despite the high-quality novel view rendering that NeRF provides, a critical limitation is that it relies on volume rendering that can be computationally expensive and does not utilize the advancements in modern graphics hardware. Existing methods for this problem fall short when it comes to modelling volumetric effects as they rely purely on surface rendering. We thus propose to model the scene with polygons, which can then be used to obtain the quadrature points required to model volumetric effects, and also their opacity and colour from the texture. To obtain such polygonal mesh, we train a specialized field whose zero-crossings would correspond to the quadrature points when volume rendering, and perform marching cubes on this field. We then rasterize the polygons and utilize the fragment shaders to obtain the final colour image. Our method allows rendering on various devices and easy integration with existing graphics frameworks while keeping the benefits of volume rendering alive.
SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer
Dec 02, 2023Self-supervised learning relies heavily on data augmentation to extract meaningful representations from unlabeled images. While existing state-of-the-art augmentation pipelines incorporate a wide range of primitive transformations, these often disregard natural image structure. Thus, augmented samples can exhibit degraded semantic information and low stylistic diversity, affecting downstream performance of self-supervised representations. To overcome this, we propose SASSL: Style Augmentations for Self Supervised Learning, a novel augmentation technique based on Neural Style Transfer. The method decouples semantic and stylistic attributes in images and applies transformations exclusively to the style while preserving content, generating diverse augmented samples that better retain their semantic properties. Experimental results show our technique achieves a top-1 classification performance improvement of more than 2% on ImageNet compared to the well-established MoCo v2. We also measure transfer learning performance across five diverse datasets, observing significant improvements of up to 3.75%. Our experiments indicate that decoupling style from content information and transferring style across datasets to diversify augmentations can significantly improve downstream performance of self-supervised representations.
Token Fusion: Bridging the Gap between Token Pruning and Token Merging
Dec 02, 2023Vision Transformers (ViTs) have emerged as powerful backbones in computer vision, outperforming many traditional CNNs. However, their computational overhead, largely attributed to the self-attention mechanism, makes deployment on resource-constrained edge devices challenging. Multiple solutions rely on token pruning or token merging. In this paper, we introduce "Token Fusion" (ToFu), a method that amalgamates the benefits of both token pruning and token merging. Token pruning proves advantageous when the model exhibits sensitivity to input interpolations, while token merging is effective when the model manifests close to linear responses to inputs. We combine this to propose a new scheme called Token Fusion. Moreover, we tackle the limitations of average merging, which doesn't preserve the intrinsic feature norm, resulting in distributional shifts. To mitigate this, we introduce MLERP merging, a variant of the SLERP technique, tailored to merge multiple tokens while maintaining the norm distribution. ToFu is versatile, applicable to ViTs with or without additional training. Our empirical evaluations indicate that ToFu establishes new benchmarks in both classification and image generation tasks concerning computational efficiency and model accuracy.