 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Oct 16, 2023


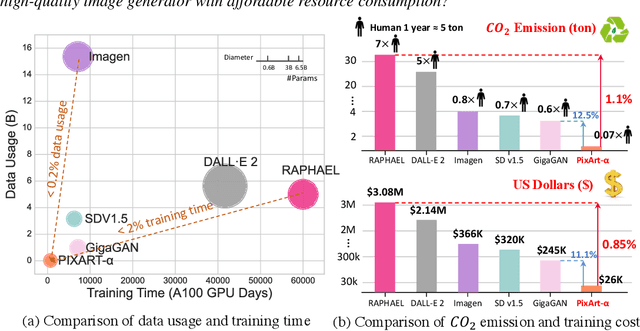
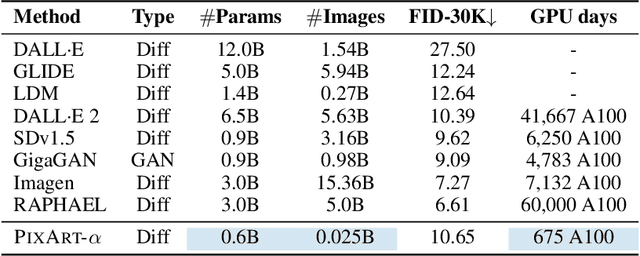
The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PIXART-$\alpha$, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost, as shown in Figure 1 and 2. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PIXART-$\alpha$'s training speed markedly surpasses existing large-scale T2I models, e.g., PIXART-$\alpha$ only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly \$300,000 (\$26,000 vs. \$320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PIXART-$\alpha$ excels in image quality, artistry, and semantic control. We hope PIXART-$\alpha$ will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.
Deep Learning based CNN Model for Classification and Detection of Individuals Wearing Face Mask
Nov 17, 2023In response to the global COVID-19 pandemic, there has been a critical demand for protective measures, with face masks emerging as a primary safeguard. The approach involves a two-fold strategy: first, recognizing the presence of a face by detecting faces, and second, identifying masks on those faces. This project utilizes deep learning to create a model that can detect face masks in real-time streaming video as well as images. Face detection, a facet of object detection, finds applications in diverse fields such as security, biometrics, and law enforcement. Various detector systems worldwide have been developed and implemented, with convolutional neural networks chosen for their superior performance accuracy and speed in object detection. Experimental results attest to the model's excellent accuracy on test data. The primary focus of this research is to enhance security, particularly in sensitive areas. The research paper proposes a rapid image pre-processing method with masks centred on faces. Employing feature extraction and Convolutional Neural Network, the system classifies and detects individuals wearing masks. The research unfolds in three stages: image pre-processing, image cropping, and image classification, collectively contributing to the identification of masked faces. Continuous surveillance through webcams or CCTV cameras ensures constant monitoring, triggering a security alert if a person is detected without a mask.
SafeSea: Synthetic Data Generation for Adverse & Low Probability Maritime Conditions
Nov 24, 2023High-quality training data is essential for enhancing the robustness of object detection models. Within the maritime domain, obtaining a diverse real image dataset is particularly challenging due to the difficulty of capturing sea images with the presence of maritime objects , especially in stormy conditions. These challenges arise due to resource limitations, in addition to the unpredictable appearance of maritime objects. Nevertheless, acquiring data from stormy conditions is essential for training effective maritime detection models, particularly for search and rescue, where real-world conditions can be unpredictable. In this work, we introduce SafeSea, which is a stepping stone towards transforming actual sea images with various Sea State backgrounds while retaining maritime objects. Compared to existing generative methods such as Stable Diffusion Inpainting~\cite{stableDiffusion}, this approach reduces the time and effort required to create synthetic datasets for training maritime object detection models. The proposed method uses two automated filters to only pass generated images that meet the criteria. In particular, these filters will first classify the sea condition according to its Sea State level and then it will check whether the objects from the input image are still preserved. This method enabled the creation of the SafeSea dataset, offering diverse weather condition backgrounds to supplement the training of maritime models. Lastly, we observed that a maritime object detection model faced challenges in detecting objects in stormy sea backgrounds, emphasizing the impact of weather conditions on detection accuracy. The code, and dataset are available at https://github.com/martin-3240/SafeSea.
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .
SimulFlow: Simultaneously Extracting Feature and Identifying Target for Unsupervised Video Object Segmentation
Nov 30, 2023Unsupervised video object segmentation (UVOS) aims at detecting the primary objects in a given video sequence without any human interposing. Most existing methods rely on two-stream architectures that separately encode the appearance and motion information before fusing them to identify the target and generate object masks. However, this pipeline is computationally expensive and can lead to suboptimal performance due to the difficulty of fusing the two modalities properly. In this paper, we propose a novel UVOS model called SimulFlow that simultaneously performs feature extraction and target identification, enabling efficient and effective unsupervised video object segmentation. Concretely, we design a novel SimulFlow Attention mechanism to bridege the image and motion by utilizing the flexibility of attention operation, where coarse masks predicted from fused feature at each stage are used to constrain the attention operation within the mask area and exclude the impact of noise. Because of the bidirectional information flow between visual and optical flow features in SimulFlow Attention, no extra hand-designed fusing module is required and we only adopt a light decoder to obtain the final prediction. We evaluate our method on several benchmark datasets and achieve state-of-the-art results. Our proposed approach not only outperforms existing methods but also addresses the computational complexity and fusion difficulties caused by two-stream architectures. Our models achieve 87.4% J & F on DAVIS-16 with the highest speed (63.7 FPS on a 3090) and the lowest parameters (13.7 M). Our SimulFlow also obtains competitive results on video salient object detection datasets.
Scene Summarization: Clustering Scene Videos into Spatially Diverse Frames
Nov 28, 2023We propose scene summarization as a new video-based scene understanding task. It aims to summarize a long video walkthrough of a scene into a small set of frames that are spatially diverse in the scene, which has many impotant applications, such as in surveillance, real estate, and robotics. It stems from video summarization but focuses on long and continuous videos from moving cameras, instead of user-edited fragmented video clips that are more commonly studied in existing video summarization works. Our solution to this task is a two-stage self-supervised pipeline named SceneSum. Its first stage uses clustering to segment the video sequence. Our key idea is to combine visual place recognition (VPR) into this clustering process to promote spatial diversity. Its second stage needs to select a representative keyframe from each cluster as the summary while respecting resource constraints such as memory and disk space limits. Additionally, if the ground truth image trajectory is available, our method can be easily augmented with a supervised loss to enhance the clustering and keyframe selection. Extensive experiments on both real-world and simulated datasets show our method outperforms common video summarization baselines by 50%
Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
Nov 28, 2023Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to the provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model.
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D
Nov 28, 2023Lifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is https://lingtengqiu.github.io/RichDreamer/.
SARA: Controllable Makeup Transfer with Spatial Alignment and Region-Adaptive Normalization
Nov 28, 2023Makeup transfer is a process of transferring the makeup style from a reference image to the source images, while preserving the source images' identities. This technique is highly desirable and finds many applications. However, existing methods lack fine-level control of the makeup style, making it challenging to achieve high-quality results when dealing with large spatial misalignments. To address this problem, we propose a novel Spatial Alignment and Region-Adaptive normalization method (SARA) in this paper. Our method generates detailed makeup transfer results that can handle large spatial misalignments and achieve part-specific and shade-controllable makeup transfer. Specifically, SARA comprises three modules: Firstly, a spatial alignment module that preserves the spatial context of makeup and provides a target semantic map for guiding the shape-independent style codes. Secondly, a region-adaptive normalization module that decouples shape and makeup style using per-region encoding and normalization, which facilitates the elimination of spatial misalignments. Lastly, a makeup fusion module blends identity features and makeup style by injecting learned scale and bias parameters. Experimental results show that our SARA method outperforms existing methods and achieves state-of-the-art performance on two public datasets.