 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Gradient Estimation via Adaptive Sampling and Importance Sampling
Nov 27, 2023
Machine learning problems rely heavily on stochastic gradient descent (SGD) for optimization. The effectiveness of SGD is contingent upon accurately estimating gradients from a mini-batch of data samples. Instead of the commonly used uniform sampling, adaptive or importance sampling reduces noise in gradient estimation by forming mini-batches that prioritize crucial data points. Previous research has suggested that data points should be selected with probabilities proportional to their gradient norm. Nevertheless, existing algorithms have struggled to efficiently integrate importance sampling into machine learning frameworks. In this work, we make two contributions. First, we present an algorithm that can incorporate existing importance functions into our framework. Second, we propose a simplified importance function that relies solely on the loss gradient of the output layer. By leveraging our proposed gradient estimation techniques, we observe improved convergence in classification and regression tasks with minimal computational overhead. We validate the effectiveness of our adaptive and importance-sampling approach on image and point-cloud datasets.
A Region of Interest Focused Triple UNet Architecture for Skin Lesion Segmentation
Nov 21, 2023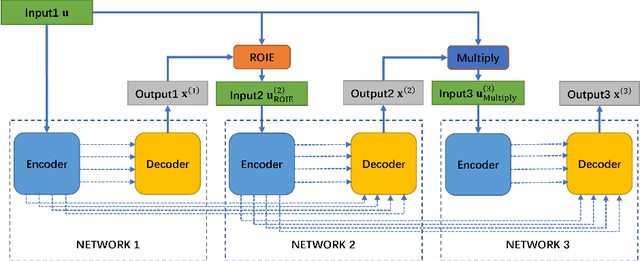
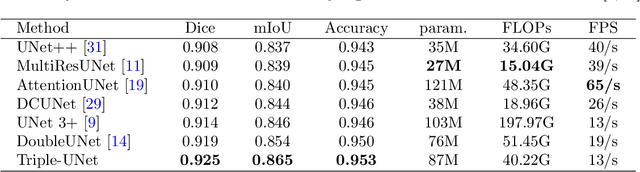
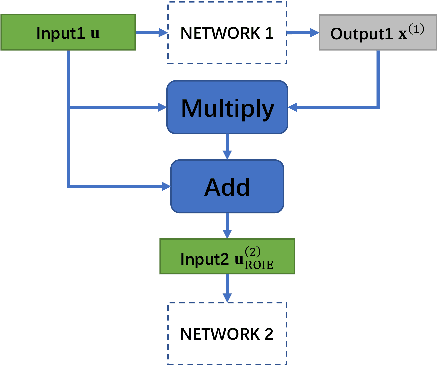
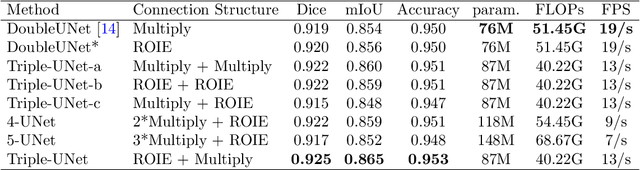
Skin lesion segmentation is of great significance for skin lesion analysis and subsequent treatment. It is still a challenging task due to the irregular and fuzzy lesion borders, and diversity of skin lesions. In this paper, we propose Triple-UNet to automatically segment skin lesions. It is an organic combination of three UNet architectures with suitable modules. In order to concatenate the first and second sub-networks more effectively, we design a region of interest enhancement module (ROIE). The ROIE enhances the target object region of the image by using the predicted score map of the first UNet. The features learned by the first UNet and the enhanced image help the second UNet obtain a better score map. Finally, the results are fine-tuned by the third UNet. We evaluate our algorithm on a publicly available dataset of skin lesion segmentation. Experiments show that Triple-UNet outperforms the state-of-the-art on skin lesion segmentation.
Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatially Relation Matching
Nov 21, 2023Drone navigation through natural language commands remains a significant challenge due to the lack of publicly available multi-modal datasets and the intricate demands of fine-grained visual-text alignment. In response to this pressing need, we present a new human-computer interaction annotation benchmark called GeoText-1652, meticulously curated through a robust Large Language Model (LLM)-based data generation framework and the expertise of pre-trained vision models. This new dataset seamlessly extends the existing image dataset, \ie, University-1652, with spatial-aware text annotations, encompassing intricate image-text-bounding box associations. Besides, we introduce a new optimization objective to leverage fine-grained spatial associations, called blending spatial matching, for region-level spatial relation matching. Extensive experiments reveal that our approach maintains an exceptional recall rate under varying description complexities. This underscores the promising potential of our approach in elevating drone control and navigation through the seamless integration of natural language commands in real-world scenarios.
Visually Guided Object Grasping
Nov 21, 2023In this paper we present a visual servoing approach to the problem of object grasping and more generally, to the problem of aligning an end-effector with an object. First we extend the method proposed by Espiau et al. [1] to the case of a camera which is not mounted onto the robot being controlled and we stress the importance of the real-time estimation of the image Jacobian. Second, we show how to represent a grasp or more generally, an alignment between two solids in 3-D projective space using an uncalibrated stereo rig. Such a 3-D projective representation is view-invariant in the sense that it can be easily mapped into an image set-point without any knowledge about the camera parameters. Third, we perform an analysis of the performances of the visual servoing algorithm and of the grasping precision that can be expected from this type of approach.
Histopathological Image Analysis with Style-Augmented Feature Domain Mixing for Improved Generalization
Oct 31, 2023Histopathological images are essential for medical diagnosis and treatment planning, but interpreting them accurately using machine learning can be challenging due to variations in tissue preparation, staining and imaging protocols. Domain generalization aims to address such limitations by enabling the learning models to generalize to new datasets or populations. Style transfer-based data augmentation is an emerging technique that can be used to improve the generalizability of machine learning models for histopathological images. However, existing style transfer-based methods can be computationally expensive, and they rely on artistic styles, which can negatively impact model accuracy. In this study, we propose a feature domain style mixing technique that uses adaptive instance normalization to generate style-augmented versions of images. We compare our proposed method with existing style transfer-based data augmentation methods and found that it performs similarly or better, despite requiring less computation and time. Our results demonstrate the potential of feature domain statistics mixing in the generalization of learning models for histopathological image analysis.
TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models
Oct 20, 2023We present TexFusion (Texture Diffusion), a new method to synthesize textures for given 3D geometries, using large-scale text-guided image diffusion models. In contrast to recent works that leverage 2D text-to-image diffusion models to distill 3D objects using a slow and fragile optimization process, TexFusion introduces a new 3D-consistent generation technique specifically designed for texture synthesis that employs regular diffusion model sampling on different 2D rendered views. Specifically, we leverage latent diffusion models, apply the diffusion model's denoiser on a set of 2D renders of the 3D object, and aggregate the different denoising predictions on a shared latent texture map. Final output RGB textures are produced by optimizing an intermediate neural color field on the decodings of 2D renders of the latent texture. We thoroughly validate TexFusion and show that we can efficiently generate diverse, high quality and globally coherent textures. We achieve state-of-the-art text-guided texture synthesis performance using only image diffusion models, while avoiding the pitfalls of previous distillation-based methods. The text-conditioning offers detailed control and we also do not rely on any ground truth 3D textures for training. This makes our method versatile and applicable to a broad range of geometry and texture types. We hope that TexFusion will advance AI-based texturing of 3D assets for applications in virtual reality, game design, simulation, and more.
* Videos and more results on https://research.nvidia.com/labs/toronto-ai/texfusion/
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .
SimulFlow: Simultaneously Extracting Feature and Identifying Target for Unsupervised Video Object Segmentation
Nov 30, 2023Unsupervised video object segmentation (UVOS) aims at detecting the primary objects in a given video sequence without any human interposing. Most existing methods rely on two-stream architectures that separately encode the appearance and motion information before fusing them to identify the target and generate object masks. However, this pipeline is computationally expensive and can lead to suboptimal performance due to the difficulty of fusing the two modalities properly. In this paper, we propose a novel UVOS model called SimulFlow that simultaneously performs feature extraction and target identification, enabling efficient and effective unsupervised video object segmentation. Concretely, we design a novel SimulFlow Attention mechanism to bridege the image and motion by utilizing the flexibility of attention operation, where coarse masks predicted from fused feature at each stage are used to constrain the attention operation within the mask area and exclude the impact of noise. Because of the bidirectional information flow between visual and optical flow features in SimulFlow Attention, no extra hand-designed fusing module is required and we only adopt a light decoder to obtain the final prediction. We evaluate our method on several benchmark datasets and achieve state-of-the-art results. Our proposed approach not only outperforms existing methods but also addresses the computational complexity and fusion difficulties caused by two-stream architectures. Our models achieve 87.4% J & F on DAVIS-16 with the highest speed (63.7 FPS on a 3090) and the lowest parameters (13.7 M). Our SimulFlow also obtains competitive results on video salient object detection datasets.
Lightweight High-Speed Photography Built on Coded Exposure and Implicit Neural Representation of Videos
Nov 22, 2023The compact cameras recording high-speed scenes with high resolution are highly demanded, but the required high bandwidth often leads to bulky, heavy systems, which limits their applications on low-capacity platforms. Adopting a coded exposure setup to encode a frame sequence into a blurry snapshot and retrieve the latent sharp video afterward can serve as a lightweight solution. However, restoring motion from blur is quite challenging due to the high ill-posedness of motion blur decomposition, intrinsic ambiguity in motion direction, and diverse motions in natural videos. In this work, by leveraging classical coded exposure imaging technique and emerging implicit neural representation for videos, we tactfully embed the motion direction cues into the blurry image during the imaging process and develop a novel self-recursive neural network to sequentially retrieve the latent video sequence from the blurry image utilizing the embedded motion direction cues. To validate the effectiveness and efficiency of the proposed framework, we conduct extensive experiments on benchmark datasets and real-captured blurry images. The results demonstrate that our proposed framework significantly outperforms existing methods in quality and flexibility. The code for our work is available at https://github.com/zhihongz/BDINR