 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VBench: Comprehensive Benchmark Suite for Video Generative Models
Nov 29, 2023
Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has three appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. We will open-source VBench, including all prompts, evaluation methods, generated videos, and human preference annotations, and also include more video generation models in VBench to drive forward the field of video generation.
Focus on Query: Adversarial Mining Transformer for Few-Shot Segmentation
Nov 29, 2023
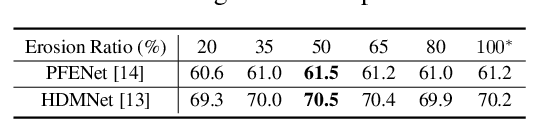

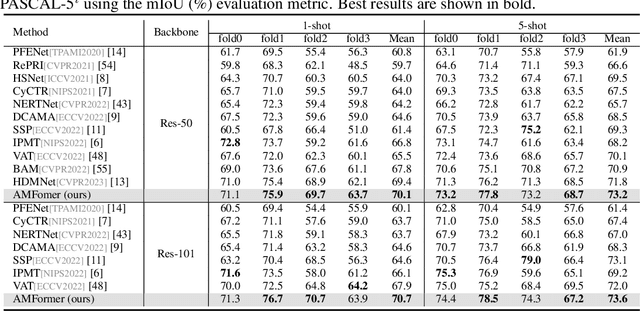
Few-shot segmentation (FSS) aims to segment objects of new categories given only a handful of annotated samples. Previous works focus their efforts on exploring the support information while paying less attention to the mining of the critical query branch. In this paper, we rethink the importance of support information and propose a new query-centric FSS model Adversarial Mining Transformer (AMFormer), which achieves accurate query image segmentation with only rough support guidance or even weak support labels. The proposed AMFormer enjoys several merits. First, we design an object mining transformer (G) that can achieve the expansion of incomplete region activated by support clue, and a detail mining transformer (D) to discriminate the detailed local difference between the expanded mask and the ground truth. Second, we propose to train G and D via an adversarial process, where G is optimized to generate more accurate masks approaching ground truth to fool D. We conduct extensive experiments on commonly used Pascal-5i and COCO-20i benchmarks and achieve state-of-the-art results across all settings. In addition, the decent performance with weak support labels in our query-centric paradigm may inspire the development of more general FSS models. Code will be available at https://github.com/Wyxdm/AMNet.
LanGWM: Language Grounded World Model
Nov 29, 2023Recent advances in deep reinforcement learning have showcased its potential in tackling complex tasks. However, experiments on visual control tasks have revealed that state-of-the-art reinforcement learning models struggle with out-of-distribution generalization. Conversely, expressing higher-level concepts and global contexts is relatively easy using language. Building upon recent success of the large language models, our main objective is to improve the state abstraction technique in reinforcement learning by leveraging language for robust action selection. Specifically, we focus on learning language-grounded visual features to enhance the world model learning, a model-based reinforcement learning technique. To enforce our hypothesis explicitly, we mask out the bounding boxes of a few objects in the image observation and provide the text prompt as descriptions for these masked objects. Subsequently, we predict the masked objects along with the surrounding regions as pixel reconstruction, similar to the transformer-based masked autoencoder approach. Our proposed LanGWM: Language Grounded World Model achieves state-of-the-art performance in out-of-distribution test at the 100K interaction steps benchmarks of iGibson point navigation tasks. Furthermore, our proposed technique of explicit language-grounded visual representation learning has the potential to improve models for human-robot interaction because our extracted visual features are language grounded.
Meta Co-Training: Two Views are Better than One
Nov 29, 2023In many practical computer vision scenarios unlabeled data is plentiful, but labels are scarce and difficult to obtain. As a result, semi-supervised learning which leverages unlabeled data to boost the performance of supervised classifiers have received significant attention in recent literature. One major class of semi-supervised algorithms is co-training. In co-training two different models leverage different independent and sufficient "views" of the data to jointly make better predictions. During co-training each model creates pseudo labels on unlabeled points which are used to improve the other model. We show that in the common case when independent views are not available we can construct such views inexpensively using pre-trained models. Co-training on the constructed views yields a performance improvement over any of the individual views we construct and performance comparable with recent approaches in semi-supervised learning, but has some undesirable properties. To alleviate the issues present with co-training we present Meta Co-Training which is an extension of the successful Meta Pseudo Labels approach to multiple views. Our method achieves new state-of-the-art performance on ImageNet-10% with very few training resources, as well as outperforming prior semi-supervised work on several other fine-grained image classification datasets.
Slot-Mixup with Subsampling: A Simple Regularization for WSI Classification
Nov 29, 2023Whole slide image (WSI) classification requires repetitive zoom-in and out for pathologists, as only small portions of the slide may be relevant to detecting cancer. Due to the lack of patch-level labels, multiple instance learning (MIL) is a common practice for training a WSI classifier. One of the challenges in MIL for WSIs is the weak supervision coming only from the slide-level labels, often resulting in severe overfitting. In response, researchers have considered adopting patch-level augmentation or applying mixup augmentation, but their applicability remains unverified. Our approach augments the training dataset by sampling a subset of patches in the WSI without significantly altering the underlying semantics of the original slides. Additionally, we introduce an efficient model (Slot-MIL) that organizes patches into a fixed number of slots, the abstract representation of patches, using an attention mechanism. We empirically demonstrate that the subsampling augmentation helps to make more informative slots by restricting the over-concentration of attention and to improve interpretability. Finally, we illustrate that combining our attention-based aggregation model with subsampling and mixup, which has shown limited compatibility in existing MIL methods, can enhance both generalization and calibration. Our proposed methods achieve the state-of-the-art performance across various benchmark datasets including class imbalance and distribution shifts.
Symbol-LLM: Leverage Language Models for Symbolic System in Visual Human Activity Reasoning
Nov 29, 2023Human reasoning can be understood as a cooperation between the intuitive, associative "System-1" and the deliberative, logical "System-2". For existing System-1-like methods in visual activity understanding, it is crucial to integrate System-2 processing to improve explainability, generalization, and data efficiency. One possible path of activity reasoning is building a symbolic system composed of symbols and rules, where one rule connects multiple symbols, implying human knowledge and reasoning abilities. Previous methods have made progress, but are defective with limited symbols from handcraft and limited rules from visual-based annotations, failing to cover the complex patterns of activities and lacking compositional generalization. To overcome the defects, we propose a new symbolic system with two ideal important properties: broad-coverage symbols and rational rules. Collecting massive human knowledge via manual annotations is expensive to instantiate this symbolic system. Instead, we leverage the recent advancement of LLMs (Large Language Models) as an approximation of the two ideal properties, i.e., Symbols from Large Language Models (Symbol-LLM). Then, given an image, visual contents from the images are extracted and checked as symbols and activity semantics are reasoned out based on rules via fuzzy logic calculation. Our method shows superiority in extensive activity understanding tasks. Code and data are available at https://mvig-rhos.com/symbol_llm.
Lesion Search with Self-supervised Learning
Nov 18, 2023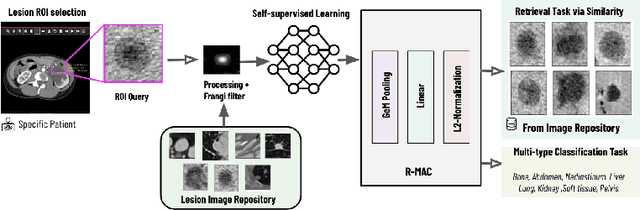
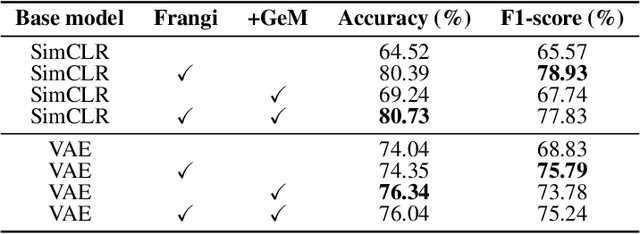
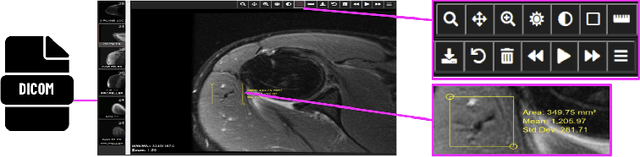
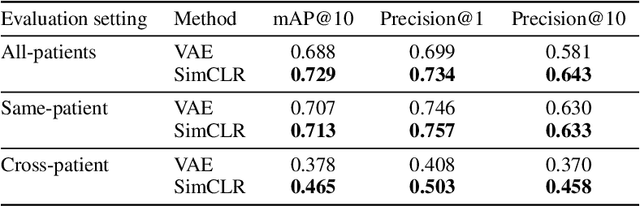
Content-based image retrieval (CBIR) with self-supervised learning (SSL) accelerates clinicians' interpretation of similar images without manual annotations. We develop a CBIR from the contrastive learning SimCLR and incorporate a generalized-mean (GeM) pooling followed by L2 normalization to classify lesion types and retrieve similar images before clinicians' analysis. Results have shown improved performance. We additionally build an open-source application for image analysis and retrieval. The application is easy to integrate, relieving manual efforts and suggesting the potential to support clinicians' everyday activities.
Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatially Relation Matching
Nov 21, 2023Drone navigation through natural language commands remains a significant challenge due to the lack of publicly available multi-modal datasets and the intricate demands of fine-grained visual-text alignment. In response to this pressing need, we present a new human-computer interaction annotation benchmark called GeoText-1652, meticulously curated through a robust Large Language Model (LLM)-based data generation framework and the expertise of pre-trained vision models. This new dataset seamlessly extends the existing image dataset, \ie, University-1652, with spatial-aware text annotations, encompassing intricate image-text-bounding box associations. Besides, we introduce a new optimization objective to leverage fine-grained spatial associations, called blending spatial matching, for region-level spatial relation matching. Extensive experiments reveal that our approach maintains an exceptional recall rate under varying description complexities. This underscores the promising potential of our approach in elevating drone control and navigation through the seamless integration of natural language commands in real-world scenarios.
A Region of Interest Focused Triple UNet Architecture for Skin Lesion Segmentation
Nov 21, 2023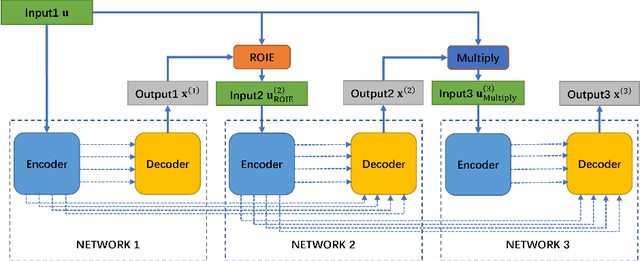
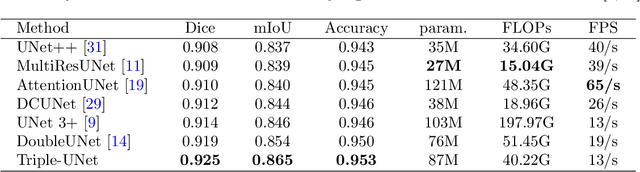
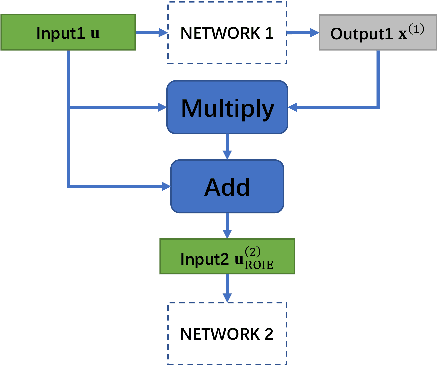
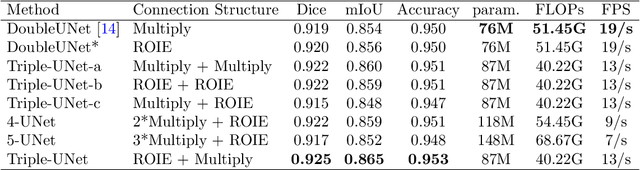
Skin lesion segmentation is of great significance for skin lesion analysis and subsequent treatment. It is still a challenging task due to the irregular and fuzzy lesion borders, and diversity of skin lesions. In this paper, we propose Triple-UNet to automatically segment skin lesions. It is an organic combination of three UNet architectures with suitable modules. In order to concatenate the first and second sub-networks more effectively, we design a region of interest enhancement module (ROIE). The ROIE enhances the target object region of the image by using the predicted score map of the first UNet. The features learned by the first UNet and the enhanced image help the second UNet obtain a better score map. Finally, the results are fine-tuned by the third UNet. We evaluate our algorithm on a publicly available dataset of skin lesion segmentation. Experiments show that Triple-UNet outperforms the state-of-the-art on skin lesion segmentation.
Visually Guided Object Grasping
Nov 21, 2023In this paper we present a visual servoing approach to the problem of object grasping and more generally, to the problem of aligning an end-effector with an object. First we extend the method proposed by Espiau et al. [1] to the case of a camera which is not mounted onto the robot being controlled and we stress the importance of the real-time estimation of the image Jacobian. Second, we show how to represent a grasp or more generally, an alignment between two solids in 3-D projective space using an uncalibrated stereo rig. Such a 3-D projective representation is view-invariant in the sense that it can be easily mapped into an image set-point without any knowledge about the camera parameters. Third, we perform an analysis of the performances of the visual servoing algorithm and of the grasping precision that can be expected from this type of approach.