 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TLMCM Network for Medical Image Hierarchical Multi-Label Classification
Nov 01, 2023
Medical Image Hierarchical Multi-Label Classification (MI-HMC) is of paramount importance in modern healthcare, presenting two significant challenges: data imbalance and \textit{hierarchy constraint}. Existing solutions involve complex model architecture design or domain-specific preprocessing, demanding considerable expertise or effort in implementation. To address these limitations, this paper proposes Transfer Learning with Maximum Constraint Module (TLMCM) network for the MI-HMC task. The TLMCM network offers a novel approach to overcome the aforementioned challenges, outperforming existing methods based on the Area Under the Average Precision and Recall Curve($AU\overline{(PRC)}$) metric. In addition, this research proposes two novel accuracy metrics, $EMR$ and $HammingAccuracy$, which have not been extensively explored in the context of the MI-HMC task. Experimental results demonstrate that the TLMCM network achieves high multi-label prediction accuracy($80\%$-$90\%$) for MI-HMC tasks, making it a valuable contribution to healthcare domain applications.
Domain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
Optimal Transport Aggregation for Visual Place Recognition
Nov 27, 2023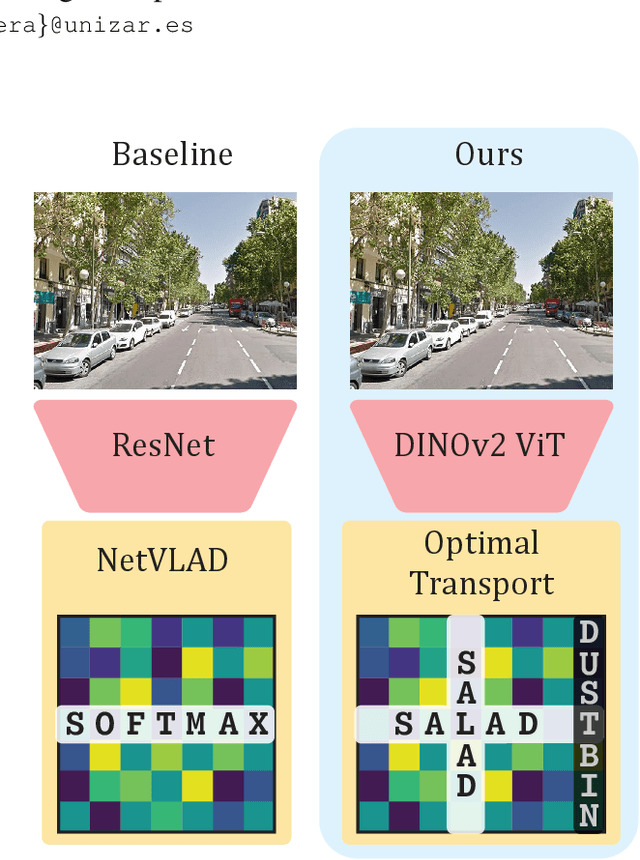

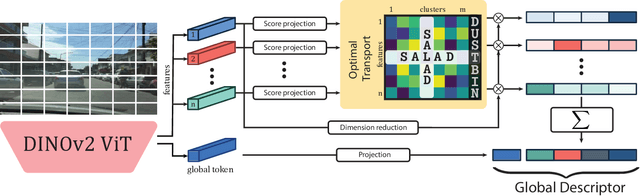

The task of Visual Place Recognition (VPR) aims to match a query image against references from an extensive database of images from different places, relying solely on visual cues. State-of-the-art pipelines focus on the aggregation of features extracted from a deep backbone, in order to form a global descriptor for each image. In this context, we introduce SALAD (Sinkhorn Algorithm for Locally Aggregated Descriptors), which reformulates NetVLAD's soft-assignment of local features to clusters as an optimal transport problem. In SALAD, we consider both feature-to-cluster and cluster-to-feature relations and we also introduce a 'dustbin' cluster, designed to selectively discard features deemed non-informative, enhancing the overall descriptor quality. Additionally, we leverage and fine-tune DINOv2 as a backbone, which provides enhanced description power for the local features, and dramatically reduces the required training time. As a result, our single-stage method not only surpasses single-stage baselines in public VPR datasets, but also surpasses two-stage methods that add a re-ranking with significantly higher cost. Code and models are available at https://github.com/serizba/salad.
FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax
Nov 27, 2023Text-to-video (T2V) generation is a rapidly growing research area that aims to translate the scenes, objects, and actions within complex video text into a sequence of coherent visual frames. We present FlowZero, a novel framework that combines Large Language Models (LLMs) with image diffusion models to generate temporally-coherent videos. FlowZero uses LLMs to understand complex spatio-temporal dynamics from text, where LLMs can generate a comprehensive dynamic scene syntax (DSS) containing scene descriptions, object layouts, and background motion patterns. These elements in DSS are then used to guide the image diffusion model for video generation with smooth object motions and frame-to-frame coherence. Moreover, FlowZero incorporates an iterative self-refinement process, enhancing the alignment between the spatio-temporal layouts and the textual prompts for the videos. To enhance global coherence, we propose enriching the initial noise of each frame with motion dynamics to control the background movement and camera motion adaptively. By using spatio-temporal syntaxes to guide the diffusion process, FlowZero achieves improvement in zero-shot video synthesis, generating coherent videos with vivid motion.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Nov 27, 2023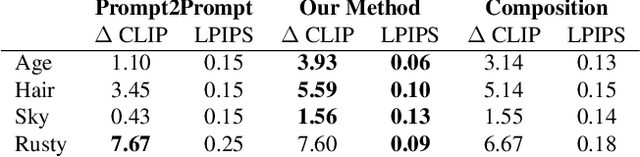
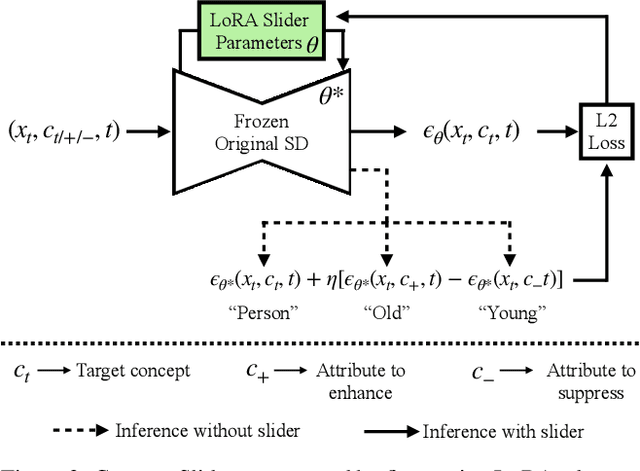


We present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. Our approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes. A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments comparing to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference. We showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at https://sliders.baulab.info/
Hyp-UML: Hyperbolic Image Retrieval with Uncertainty-aware Metric Learning
Oct 22, 2023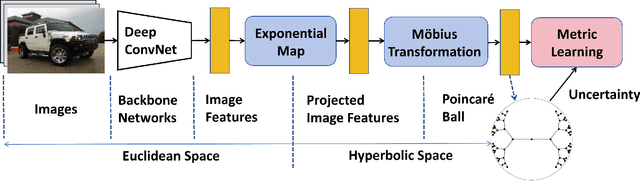
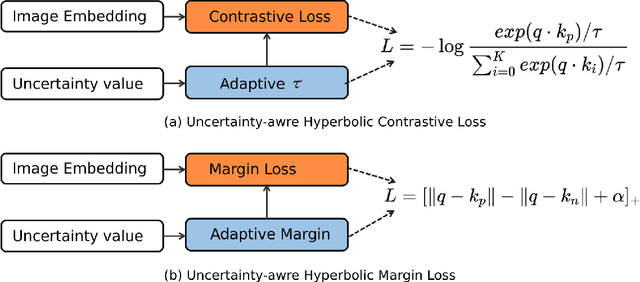

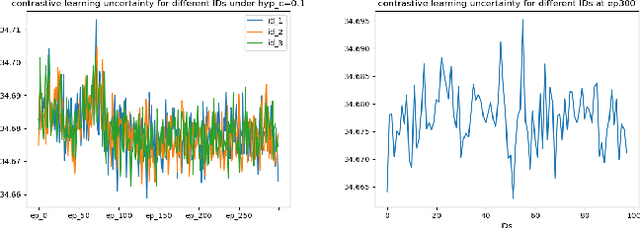
Metric learning plays a critical role in training image retrieval and classification. It is also a key algorithm in representation learning, e.g., for feature learning and its alignment in metric space. Hyperbolic embedding has been recently developed. Compared to the conventional Euclidean embedding in most of the previously developed models, Hyperbolic embedding can be more effective in representing the hierarchical data structure. Second, uncertainty estimation/measurement is a long-lasting challenge in artificial intelligence. Successful uncertainty estimation can improve a machine learning model's performance, robustness, and security. In Hyperbolic space, uncertainty measurement is at least with equivalent, if not more, critical importance. In this paper, we develop a Hyperbolic image embedding with uncertainty-aware metric learning for image retrieval. We call our method Hyp-UML: Hyperbolic Uncertainty-aware Metric Learning. Our contribution are threefold: we propose an image embedding algorithm based on Hyperbolic space, with their corresponding uncertainty value; we propose two types of uncertainty-aware metric learning, for the popular Contrastive learning and conventional margin-based metric learning, respectively. We perform extensive experimental validations to prove that the proposed algorithm can achieve state-of-the-art results among related methods. The comprehensive ablation study validates the effectiveness of each component of the proposed algorithm.
Towards Machine Learning-based Quantitative Hyperspectral Image Guidance for Brain Tumor Resection
Nov 24, 2023Complete resection of malignant gliomas is hampered by the difficulty in distinguishing tumor cells at the infiltration zone. Fluorescence guidance with 5-ALA assists in reaching this goal. Using hyperspectral imaging, previous work characterized five fluorophores' emission spectra in most human brain tumors. In this paper, the effectiveness of these five spectra was explored for different tumor and tissue classification tasks in 184 patients (891 hyperspectral measurements) harboring low- (n=30) and high-grade gliomas (n=115), non-glial primary brain tumors (n=19), radiation necrosis (n=2), miscellaneous (n=10) and metastases (n=8). Four machine learning models were trained to classify tumor type, grade, glioma margins and IDH mutation. Using random forests and multi-layer perceptrons, the classifiers achieved average test accuracies of 84-87%, 96%, 86%, and 93% respectively. All five fluorophore abundances varied between tumor margin types and tumor grades (p < 0.01). For tissue type, at least four of the five fluorophore abundances were found to be significantly different (p < 0.01) between all classes. These results demonstrate the fluorophores' differing abundances in different tissue classes, as well as the value of the five fluorophores as potential optical biomarkers, opening new opportunities for intraoperative classification systems in fluorescence-guided neurosurgery.
DragVideo: Interactive Drag-style Video Editing
Dec 03, 2023Editing visual content on videos remains a formidable challenge with two main issues: 1) direct and easy user control to produce 2) natural editing results without unsightly distortion and artifacts after changing shape, expression and layout. Inspired by DragGAN, a recent image-based drag-style editing technique, we address above issues by proposing DragVideo, where a similar drag-style user interaction is adopted to edit video content while maintaining temporal consistency. Empowered by recent diffusion models as in DragDiffusion, DragVideo contains the novel Drag-on-Video U-Net (DoVe) editing method, which optimizes diffused video latents generated by video U-Net to achieve the desired control. Specifically, we use Sample-specific LoRA fine-tuning and Mutual Self-Attention control to ensure faithful reconstruction of video from the DoVe method. We also present a series of testing examples for drag-style video editing and conduct extensive experiments across a wide array of challenging editing tasks, such as motion editing, skeleton editing, etc, underscoring DragVideo's versatility and generality. Our codes including the DragVideo web user interface will be released.
MABViT -- Modified Attention Block Enhances Vision Transformers
Dec 03, 2023Recent studies have demonstrated the effectiveness of Gated Linear Units (GLU) in enhancing transformer models, particularly in Large Language Models (LLMs). Additionally, utilizing a parallel configuration within each Transformer block rather than the conventional serialized method has been revealed to accelerate the training of LLMs without significantly impacting performance. However, when the MLP and attention block were run in parallel for the image classification task, we observed a noticeable decline in performance. We propose a novel transformer variant that integrates non-linearity within the attention block to tackle this problem. We implemented the GLU-based activation function on the Value tensor, and this new technique surpasses the current state-of-the-art S/16 variant of Vision Transformers by 0.6% on the ImageNet-1K dataset while utilizing fewer parameters. It also supersedes the B/16 variant while using only half the parameters. Furthermore, we provide results with the GELU activation function variant to confirm our assertions. Lastly, we showcase that the MABViT variants exhibit greater potential when utilized in deep transformers compared to the standard architecture.
Acoustic Signal Analysis with Deep Neural Network for Detecting Fault Diagnosis in Industrial Machines
Dec 02, 2023Detecting machine malfunctions at an early stage is crucial for reducing interruptions in operational processes within industrial settings. Recently, the deep learning approach has started to be preferred for the detection of failures in machines. Deep learning provides an effective solution in fault detection processes thanks to automatic feature extraction. In this study, a deep learning-based system was designed to analyze the sound signals produced by industrial machines. Acoustic sound signals were converted into Mel spectrograms. For the purpose of classifying spectrogram images, the DenseNet-169 model, a deep learning architecture recognized for its effectiveness in image classification tasks, was used. The model was trained using the transfer learning method on the MIMII dataset including sounds from four types of industrial machines. The results showed that the proposed method reached an accuracy rate varying between 97.17% and 99.87% at different Sound Noise Rate levels.