 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Three-dimensional Bone Image Synthesis with Generative Adversarial Networks
Oct 26, 2023
Medical image processing has been highlighted as an area where deep learning-based models have the greatest potential. However, in the medical field in particular, problems of data availability and privacy are hampering research progress and thus rapid implementation in clinical routine. The generation of synthetic data not only ensures privacy, but also allows to \textit{draw} new patients with specific characteristics, enabling the development of data-driven models on a much larger scale. This work demonstrates that three-dimensional generative adversarial networks (GANs) can be efficiently trained to generate high-resolution medical volumes with finely detailed voxel-based architectures. In addition, GAN inversion is successfully implemented for the three-dimensional setting and used for extensive research on model interpretability and applications such as image morphing, attribute editing and style mixing. The results are comprehensively validated on a database of three-dimensional HR-pQCT instances representing the bone micro-architecture of the distal radius.
Using Higher-Order Moments to Assess the Quality of GAN-generated Image Features
Oct 31, 2023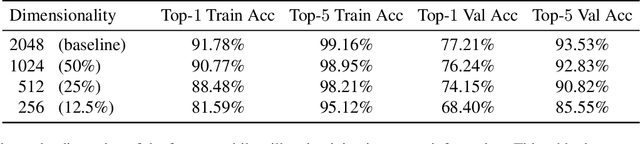
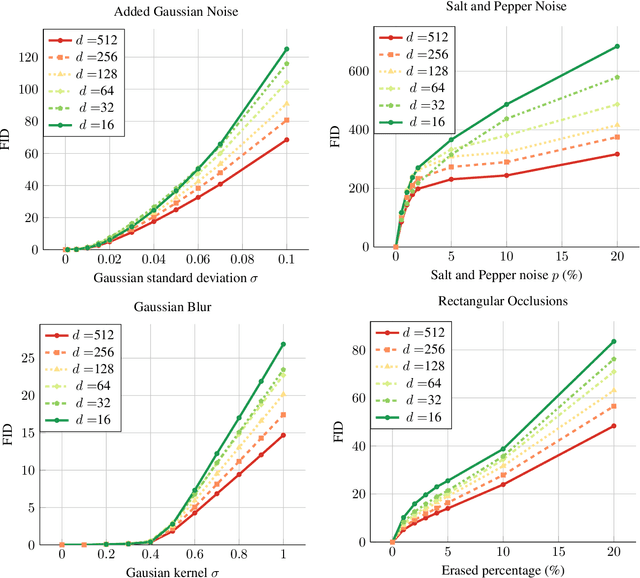
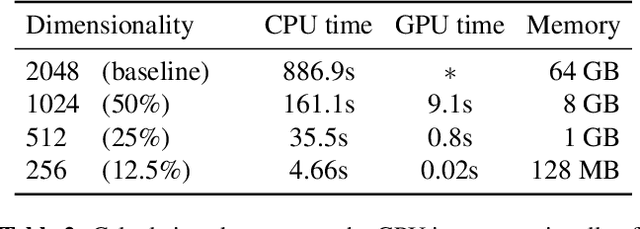
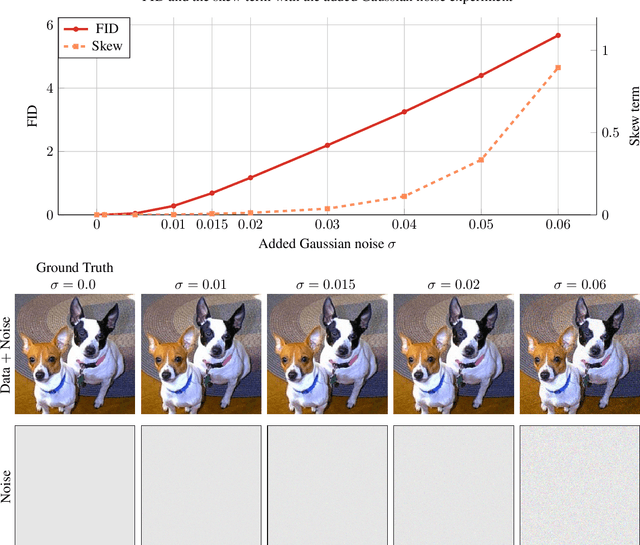
The rapid advancement of Generative Adversarial Networks (GANs) necessitates the need to robustly evaluate these models. Among the established evaluation criteria, the Fr\'{e}chet Inception Distance (FID) has been widely adopted due to its conceptual simplicity, fast computation time, and strong correlation with human perception. However, FID has inherent limitations, mainly stemming from its assumption that feature embeddings follow a Gaussian distribution, and therefore can be defined by their first two moments. As this does not hold in practice, in this paper we explore the importance of third-moments in image feature data and use this information to define a new measure, which we call the Skew Inception Distance (SID). We prove that SID is a pseudometric on probability distributions, show how it extends FID, and present a practical method for its computation. Our numerical experiments support that SID either tracks with FID or, in some cases, aligns more closely with human perception when evaluating image features of ImageNet data.
Towards an accurate and generalizable multiple sclerosis lesion segmentation model using self-ensembled lesion fusion
Dec 03, 2023Automatic multiple sclerosis (MS) lesion segmentation using multi-contrast magnetic resonance (MR) images provides improved efficiency and reproducibility compared to manual delineation. Current state-of-the-art automatic MS lesion segmentation methods utilize modified U-Net-like architectures. However, in the literature, dedicated architecture modifications were always required to maximize their performance. In addition, the best-performing methods have not proven to be generalizable to diverse test datasets with contrast variations and image artifacts. In this work, we developed an accurate and generalizable MS lesion segmentation model using the well-known U-Net architecture without further modification. A novel test-time self-ensembled lesion fusion strategy is proposed that not only achieved the best performance using the ISBI 2015 MS segmentation challenge data but also demonstrated robustness across various self-ensemble parameter choices. Moreover, equipped with instance normalization rather than batch normalization widely used in literature, the model trained on the ISBI challenge data generalized well on clinical test datasets from different scanners.
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
Dec 03, 2023Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.
DIAR: Deep Image Alignment and Reconstruction using Swin Transformers
Oct 17, 2023When taking images of some occluded content, one is often faced with the problem that every individual image frame contains unwanted artifacts, but a collection of images contains all relevant information if properly aligned and aggregated. In this paper, we attempt to build a deep learning pipeline that simultaneously aligns a sequence of distorted images and reconstructs them. We create a dataset that contains images with image distortions, such as lighting, specularities, shadows, and occlusion. We create perspective distortions with corresponding ground-truth homographies as labels. We use our dataset to train Swin transformer models to analyze sequential image data. The attention maps enable the model to detect relevant image content and differentiate it from outliers and artifacts. We further explore using neural feature maps as alternatives to classical key point detectors. The feature maps of trained convolutional layers provide dense image descriptors that can be used to find point correspondences between images. We utilize this to compute coarse image alignments and explore its limitations.
A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
Oct 25, 2023Text-to-image diffusion models achieved a remarkable leap in capabilities over the last few years, enabling high-quality and diverse synthesis of images from a textual prompt. However, even the most advanced models often struggle to precisely follow all of the directions in their prompts. The vast majority of these models are trained on datasets consisting of (image, caption) pairs where the images often come from the web, and the captions are their HTML alternate text. A notable example is the LAION dataset, used by Stable Diffusion and other models. In this work we observe that these captions are often of low quality, and argue that this significantly affects the model's capability to understand nuanced semantics in the textual prompts. We show that by relabeling the corpus with a specialized automatic captioning model and training a text-to-image model on the recaptioned dataset, the model benefits substantially across the board. First, in overall image quality: e.g. FID 14.84 vs. the baseline of 17.87, and 64.3% improvement in faithful image generation according to human evaluation. Second, in semantic alignment, e.g. semantic object accuracy 84.34 vs. 78.90, counting alignment errors 1.32 vs. 1.44 and positional alignment 62.42 vs. 57.60. We analyze various ways to relabel the corpus and provide evidence that this technique, which we call RECAP, both reduces the train-inference discrepancy and provides the model with more information per example, increasing sample efficiency and allowing the model to better understand the relations between captions and images.
IRAD: Implicit Representation-driven Image Resampling against Adversarial Attacks
Oct 18, 2023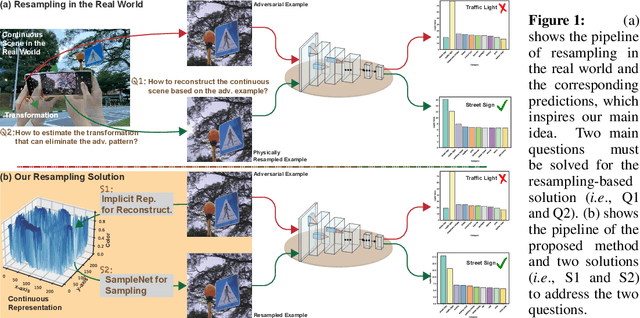
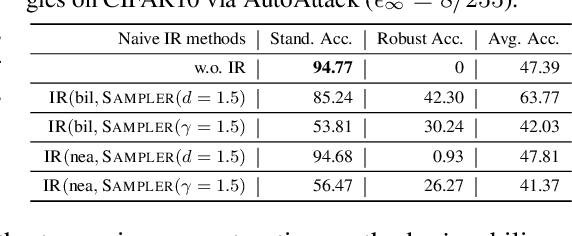
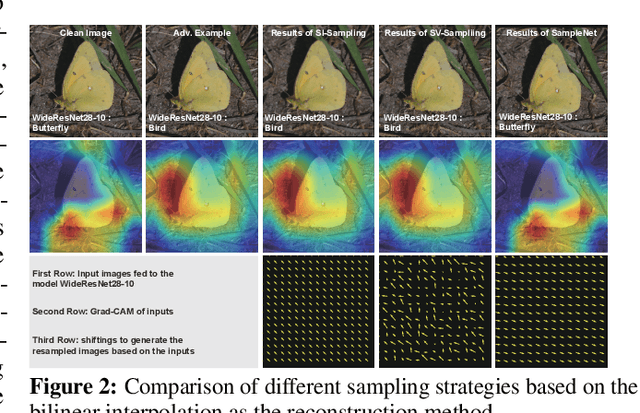
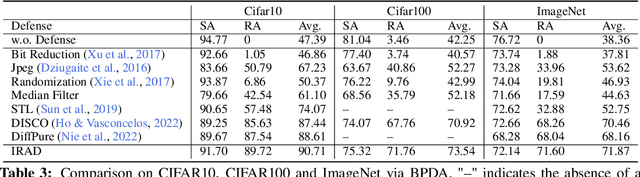
We introduce a novel approach to counter adversarial attacks, namely, image resampling. Image resampling transforms a discrete image into a new one, simulating the process of scene recapturing or rerendering as specified by a geometrical transformation. The underlying rationale behind our idea is that image resampling can alleviate the influence of adversarial perturbations while preserving essential semantic information, thereby conferring an inherent advantage in defending against adversarial attacks. To validate this concept, we present a comprehensive study on leveraging image resampling to defend against adversarial attacks. We have developed basic resampling methods that employ interpolation strategies and coordinate shifting magnitudes. Our analysis reveals that these basic methods can partially mitigate adversarial attacks. However, they come with apparent limitations: the accuracy of clean images noticeably decreases, while the improvement in accuracy on adversarial examples is not substantial. We propose implicit representation-driven image resampling (IRAD) to overcome these limitations. First, we construct an implicit continuous representation that enables us to represent any input image within a continuous coordinate space. Second, we introduce SampleNet, which automatically generates pixel-wise shifts for resampling in response to different inputs. Furthermore, we can extend our approach to the state-of-the-art diffusion-based method, accelerating it with fewer time steps while preserving its defense capability. Extensive experiments demonstrate that our method significantly enhances the adversarial robustness of diverse deep models against various attacks while maintaining high accuracy on clean images.
Towards Few-Annotation Learning in Computer Vision: Application to Image Classification and Object Detection tasks
Nov 08, 2023In this thesis, we develop theoretical, algorithmic and experimental contributions for Machine Learning with limited labels, and more specifically for the tasks of Image Classification and Object Detection in Computer Vision. In a first contribution, we are interested in bridging the gap between theory and practice for popular Meta-Learning algorithms used in Few-Shot Classification. We make connections to Multi-Task Representation Learning, which benefits from solid theoretical foundations, to verify the best conditions for a more efficient meta-learning. Then, to leverage unlabeled data when training object detectors based on the Transformer architecture, we propose both an unsupervised pretraining and a semi-supervised learning method in two other separate contributions. For pretraining, we improve Contrastive Learning for object detectors by introducing the localization information. Finally, our semi-supervised method is the first tailored to transformer-based detectors.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023
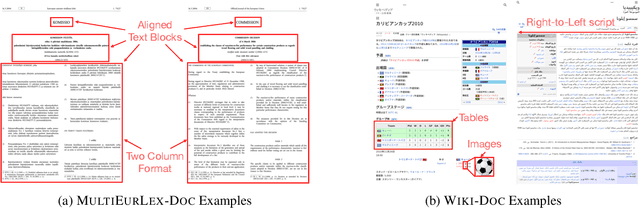

Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
Improving Denoising Diffusion Models via Simultaneous Estimation of Image and Noise
Oct 26, 2023This paper introduces two key contributions aimed at improving the speed and quality of images generated through inverse diffusion processes. The first contribution involves reparameterizing the diffusion process in terms of the angle on a quarter-circular arc between the image and noise, specifically setting the conventional $\displaystyle \sqrt{\bar{\alpha}}=\cos(\eta)$. This reparameterization eliminates two singularities and allows for the expression of diffusion evolution as a well-behaved ordinary differential equation (ODE). In turn, this allows higher order ODE solvers such as Runge-Kutta methods to be used effectively. The second contribution is to directly estimate both the image ($\mathbf{x}_0$) and noise ($\mathbf{\epsilon}$) using our network, which enables more stable calculations of the update step in the inverse diffusion steps, as accurate estimation of both the image and noise are crucial at different stages of the process. Together with these changes, our model achieves faster generation, with the ability to converge on high-quality images more quickly, and higher quality of the generated images, as measured by metrics such as Frechet Inception Distance (FID), spatial Frechet Inception Distance (sFID), precision, and recall.