 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
As-Plausible-As-Possible: Plausibility-Aware Mesh Deformation Using 2D Diffusion Priors
Nov 28, 2023
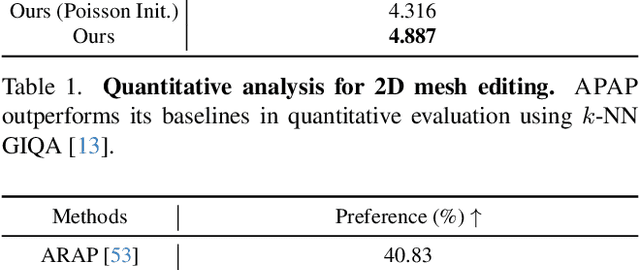
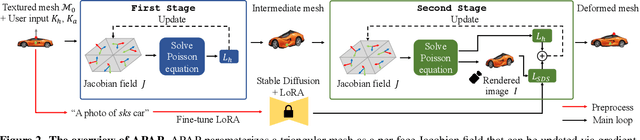


We present As-Plausible-as-Possible (APAP) mesh deformation technique that leverages 2D diffusion priors to preserve the plausibility of a mesh under user-controlled deformation. Our framework uses per-face Jacobians to represent mesh deformations, where mesh vertex coordinates are computed via a differentiable Poisson Solve. The deformed mesh is rendered, and the resulting 2D image is used in the Score Distillation Sampling (SDS) process, which enables extracting meaningful plausibility priors from a pretrained 2D diffusion model. To better preserve the identity of the edited mesh, we fine-tune our 2D diffusion model with LoRA. Gradients extracted by SDS and a user-prescribed handle displacement are then backpropagated to the per-face Jacobians, and we use iterative gradient descent to compute the final deformation that balances between the user edit and the output plausibility. We evaluate our method with 2D and 3D meshes and demonstrate qualitative and quantitative improvements when using plausibility priors over geometry-preservation or distortion-minimization priors used by previous techniques.
TopoSemiSeg: Enforcing Topological Consistency for Semi-Supervised Segmentation of Histopathology Images
Nov 28, 2023In computational pathology, segmenting densely distributed objects like glands and nuclei is crucial for downstream analysis. To alleviate the burden of obtaining pixel-wise annotations, semi-supervised learning methods learn from large amounts of unlabeled data. Nevertheless, existing semi-supervised methods overlook the topological information hidden in the unlabeled images and are thus prone to topological errors, e.g., missing or incorrectly merged/separated glands or nuclei. To address this issue, we propose TopoSemiSeg, the first semi-supervised method that learns the topological representation from unlabeled data. In particular, we propose a topology-aware teacher-student approach in which the teacher and student networks learn shared topological representations. To achieve this, we introduce topological consistency loss, which contains signal consistency and noise removal losses to ensure the learned representation is robust and focuses on true topological signals. Extensive experiments on public pathology image datasets show the superiority of our method, especially on topology-wise evaluation metrics. Code is available at https://github.com/Melon-Xu/TopoSemiSeg.
Manifold Preserving Guided Diffusion
Nov 28, 2023Despite the recent advancements, conditional image generation still faces challenges of cost, generalizability, and the need for task-specific training. In this paper, we propose Manifold Preserving Guided Diffusion (MPGD), a training-free conditional generation framework that leverages pretrained diffusion models and off-the-shelf neural networks with minimal additional inference cost for a broad range of tasks. Specifically, we leverage the manifold hypothesis to refine the guided diffusion steps and introduce a shortcut algorithm in the process. We then propose two methods for on-manifold training-free guidance using pre-trained autoencoders and demonstrate that our shortcut inherently preserves the manifolds when applied to latent diffusion models. Our experiments show that MPGD is efficient and effective for solving a variety of conditional generation applications in low-compute settings, and can consistently offer up to 3.8x speed-ups with the same number of diffusion steps while maintaining high sample quality compared to the baselines.
K-space Cold Diffusion: Learning to Reconstruct Accelerated MRI without Noise
Nov 16, 2023Deep learning-based MRI reconstruction models have achieved superior performance these days. Most recently, diffusion models have shown remarkable performance in image generation, in-painting, super-resolution, image editing and more. As a generalized diffusion model, cold diffusion further broadens the scope and considers models built around arbitrary image transformations such as blurring, down-sampling, etc. In this paper, we propose a k-space cold diffusion model that performs image degradation and restoration in k-space without the need for Gaussian noise. We provide comparisons with multiple deep learning-based MRI reconstruction models and perform tests on a well-known large open-source MRI dataset. Our results show that this novel way of performing degradation can generate high-quality reconstruction images for accelerated MRI.
Guided Flows for Generative Modeling and Decision Making
Nov 22, 2023Classifier-free guidance is a key component for improving the performance of conditional generative models for many downstream tasks. It drastically improves the quality of samples produced, but has so far only been used for diffusion models. Flow Matching (FM), an alternative simulation-free approach, trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. It remains an open question whether classifier-free guidance can be performed for Flow Matching models, and to what extent does it improve performance. In this paper, we explore the usage of Guided Flows for a variety of downstream applications involving conditional image generation, speech synthesis, and reinforcement learning. In particular, we are the first to apply flow models to the offline reinforcement learning setting. We also show that Guided Flows significantly improves the sample quality in image generation and zero-shot text-to-speech synthesis, and can make use of drastically low amounts of computation without affecting the agent's overall performance.
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Panda or not Panda? Understanding Adversarial Attacks with Interactive Visualization
Nov 22, 2023Adversarial machine learning (AML) studies attacks that can fool machine learning algorithms into generating incorrect outcomes as well as the defenses against worst-case attacks to strengthen model robustness. Specifically for image classification, it is challenging to understand adversarial attacks due to their use of subtle perturbations that are not human-interpretable, as well as the variability of attack impacts influenced by diverse methodologies, instance differences, and model architectures. Through a design study with AML learners and teachers, we introduce AdvEx, a multi-level interactive visualization system that comprehensively presents the properties and impacts of evasion attacks on different image classifiers for novice AML learners. We quantitatively and qualitatively assessed AdvEx in a two-part evaluation including user studies and expert interviews. Our results show that AdvEx is not only highly effective as a visualization tool for understanding AML mechanisms, but also provides an engaging and enjoyable learning experience, thus demonstrating its overall benefits for AML learners.
Image Augmentation with Controlled Diffusion for Weakly-Supervised Semantic Segmentation
Oct 15, 2023Weakly-supervised semantic segmentation (WSSS), which aims to train segmentation models solely using image-level labels, has achieved significant attention. Existing methods primarily focus on generating high-quality pseudo labels using available images and their image-level labels. However, the quality of pseudo labels degrades significantly when the size of available dataset is limited. Thus, in this paper, we tackle this problem from a different view by introducing a novel approach called Image Augmentation with Controlled Diffusion (IACD). This framework effectively augments existing labeled datasets by generating diverse images through controlled diffusion, where the available images and image-level labels are served as the controlling information. Moreover, we also propose a high-quality image selection strategy to mitigate the potential noise introduced by the randomness of diffusion models. In the experiments, our proposed IACD approach clearly surpasses existing state-of-the-art methods. This effect is more obvious when the amount of available data is small, demonstrating the effectiveness of our method.
EMIT-Diff: Enhancing Medical Image Segmentation via Text-Guided Diffusion Model
Oct 19, 2023Large-scale, big-variant, and high-quality data are crucial for developing robust and successful deep-learning models for medical applications since they potentially enable better generalization performance and avoid overfitting. However, the scarcity of high-quality labeled data always presents significant challenges. This paper proposes a novel approach to address this challenge by developing controllable diffusion models for medical image synthesis, called EMIT-Diff. We leverage recent diffusion probabilistic models to generate realistic and diverse synthetic medical image data that preserve the essential characteristics of the original medical images by incorporating edge information of objects to guide the synthesis process. In our approach, we ensure that the synthesized samples adhere to medically relevant constraints and preserve the underlying structure of imaging data. Due to the random sampling process by the diffusion model, we can generate an arbitrary number of synthetic images with diverse appearances. To validate the effectiveness of our proposed method, we conduct an extensive set of medical image segmentation experiments on multiple datasets, including Ultrasound breast (+13.87%), CT spleen (+0.38%), and MRI prostate (+7.78%), achieving significant improvements over the baseline segmentation methods. For the first time, to our best knowledge, the promising results demonstrate the effectiveness of our EMIT-Diff for medical image segmentation tasks and show the feasibility of introducing a first-ever text-guided diffusion model for general medical image segmentation tasks. With carefully designed ablation experiments, we investigate the influence of various data augmentation ratios, hyper-parameter settings, patch size for generating random merging mask settings, and combined influence with different network architectures.
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model
Dec 01, 2023Identity-consistent video generation seeks to synthesize videos that are guided by both textual prompts and reference images of entities. Current approaches typically utilize cross-attention layers to integrate the appearance of the entity, which predominantly captures semantic attributes, resulting in compromised fidelity of entities. Moreover, these methods necessitate iterative fine-tuning for each new entity encountered, thereby limiting their applicability. To address these challenges, we introduce VideoAssembler, a novel end-to-end framework for identity-consistent video generation that can conduct inference directly when encountering new entities. VideoAssembler is adept at producing videos that are not only flexible with respect to the input reference entities but also responsive to textual conditions. Additionally, by modulating the quantity of input images for the entity, VideoAssembler enables the execution of tasks ranging from image-to-video generation to sophisticated video editing. VideoAssembler comprises two principal components: the Reference Entity Pyramid (REP) encoder and the Entity-Prompt Attention Fusion (EPAF) module. The REP encoder is designed to infuse comprehensive appearance details into the denoising stages of the stable diffusion model. Concurrently, the EPAF module is utilized to integrate text-aligned features effectively. Furthermore, to mitigate the challenge of scarce data, we present a methodology for the preprocessing of training data. Our evaluation of the VideoAssembler framework on the UCF-101, MSR-VTT, and DAVIS datasets indicates that it achieves good performances in both quantitative and qualitative analyses (346.84 in FVD and 48.01 in IS on UCF-101). Our project page is at https://gulucaptain.github.io/videoassembler/.