 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Comparing Humans, GPT-4, and GPT-4V On Abstraction and Reasoning Tasks
Nov 26, 2023
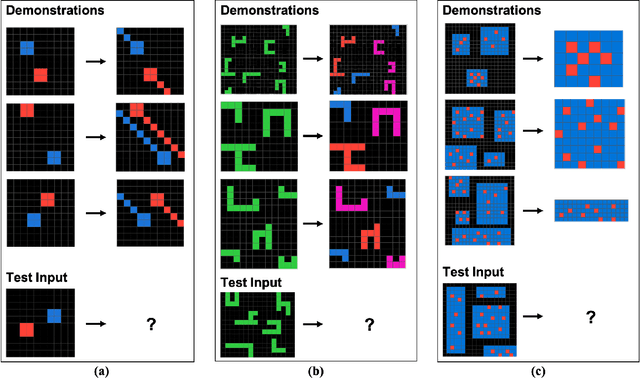
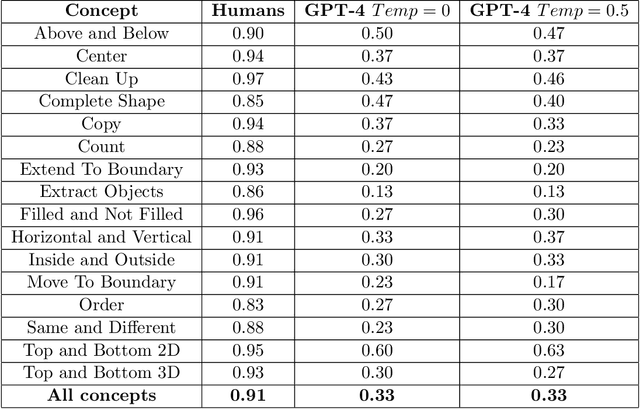

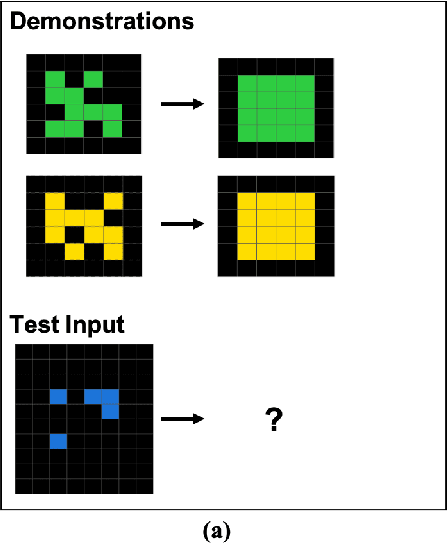
We explore the abstract reasoning abilities of text-only and multimodal versions of GPT-4, using the ConceptARC benchmark [10], which is designed to evaluate robust understanding and reasoning with core-knowledge concepts. We extend the work of Moskvichev et al. [10] by evaluating GPT-4 on more detailed, one-shot prompting (rather than simple, zero-shot prompts) with text versions of ConceptARC tasks, and by evaluating GPT-4V, the multimodal version of GPT-4, on zero- and one-shot prompts using image versions of the simplest tasks. Our experimental results support the conclusion that neither version of GPT-4 has developed robust abstraction abilities at humanlike levels.
UniHPE: Towards Unified Human Pose Estimation via Contrastive Learning
Nov 24, 2023In recent times, there has been a growing interest in developing effective perception techniques for combining information from multiple modalities. This involves aligning features obtained from diverse sources to enable more efficient training with larger datasets and constraints, as well as leveraging the wealth of information contained in each modality. 2D and 3D Human Pose Estimation (HPE) are two critical perceptual tasks in computer vision, which have numerous downstream applications, such as Action Recognition, Human-Computer Interaction, Object tracking, etc. Yet, there are limited instances where the correlation between Image and 2D/3D human pose has been clearly researched using a contrastive paradigm. In this paper, we propose UniHPE, a unified Human Pose Estimation pipeline, which aligns features from all three modalities, i.e., 2D human pose estimation, lifting-based and image-based 3D human pose estimation, in the same pipeline. To align more than two modalities at the same time, we propose a novel singular value based contrastive learning loss, which better aligns different modalities and further boosts the performance. In our evaluation, UniHPE achieves remarkable performance metrics: MPJPE $50.5$mm on the Human3.6M dataset and PAMPJPE $51.6$mm on the 3DPW dataset. Our proposed method holds immense potential to advance the field of computer vision and contribute to various applications.
Adaptability of Computer Vision at the Tactical Edge: Addressing Environmental Uncertainty
Dec 01, 2023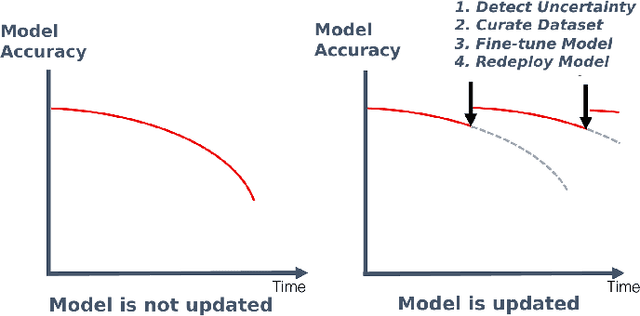
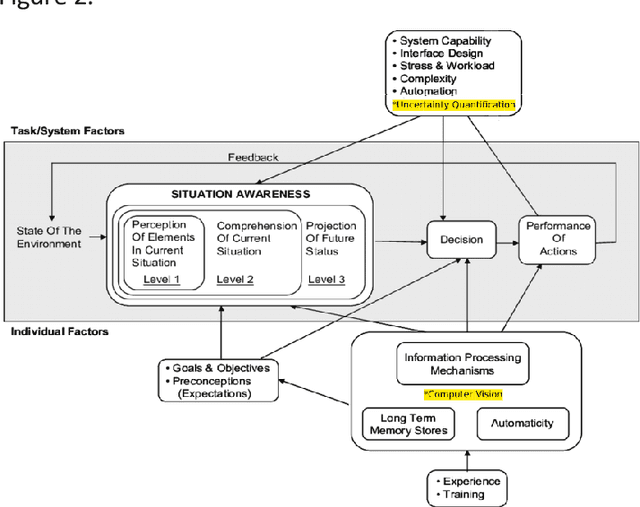
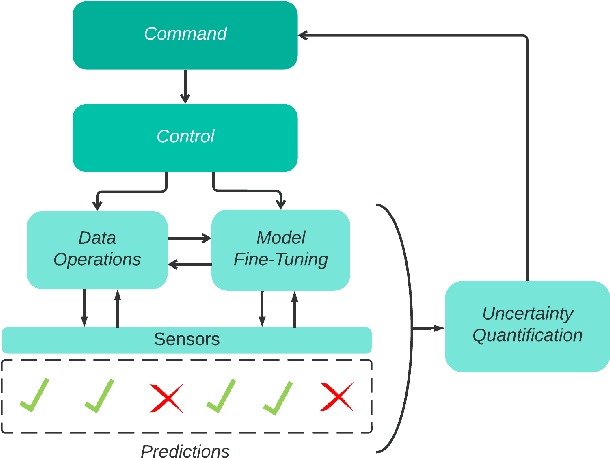
Computer Vision (CV) systems are increasingly being adopted into Command and Control (C2) systems to improve intelligence analysis on the battlefield, the tactical edge. CV systems leverage Artificial Intelligence (AI) algorithms to help visualize and interpret the environment, enhancing situational awareness. However, the adaptability of CV systems at the tactical edge remains challenging due to rapidly changing environments and objects which can confuse the deployed models. A CV model leveraged in this environment can become uncertain in its predictions, as the environment and the objects existing in the environment begin to change. Additionally, mission objectives can rapidly change leading to adjustments in technology, camera angles, and image resolutions. All of which can negatively affect the performance of and potentially introduce uncertainty into the system. When the training environment and/or technology differs from the deployment environment, CV models can perform unexpectedly. Unfortunately, most scenarios at the tactical edge do not incorporate Uncertainty Quantification (UQ) into their deployed C2 and CV systems. This concept paper explores the idea of synchronizing robust data operations and model fine-tuning driven by UQ all at the tactical edge. Specifically, curating datasets and training child models based on the residuals of predictions, using these child models to calculate prediction intervals (PI), and then using these PI to calibrate the deployed models. By incorporating UQ into the core operations surrounding C2 and CV systems at the tactical edge, we can help drive purposeful adaptability on the battlefield.
* Accepted paper for the 28th annual International Command and Control Research and Technology Symposium (ICCRTS), Johns Hopkins Applied Physics Laboratory. Baltimore, MD. (2023)
Image Augmentation with Controlled Diffusion for Weakly-Supervised Semantic Segmentation
Oct 15, 2023Weakly-supervised semantic segmentation (WSSS), which aims to train segmentation models solely using image-level labels, has achieved significant attention. Existing methods primarily focus on generating high-quality pseudo labels using available images and their image-level labels. However, the quality of pseudo labels degrades significantly when the size of available dataset is limited. Thus, in this paper, we tackle this problem from a different view by introducing a novel approach called Image Augmentation with Controlled Diffusion (IACD). This framework effectively augments existing labeled datasets by generating diverse images through controlled diffusion, where the available images and image-level labels are served as the controlling information. Moreover, we also propose a high-quality image selection strategy to mitigate the potential noise introduced by the randomness of diffusion models. In the experiments, our proposed IACD approach clearly surpasses existing state-of-the-art methods. This effect is more obvious when the amount of available data is small, demonstrating the effectiveness of our method.
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Nov 30, 2023Geographic location is essential for modeling tasks in fields ranging from ecology to epidemiology to the Earth system sciences. However, extracting relevant and meaningful characteristics of a location can be challenging, often entailing expensive data fusion or data distillation from global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP), a global, general-purpose geographic location encoder that learns an implicit representation of locations from openly available satellite imagery. Trained location encoders provide vector embeddings summarizing the characteristics of any given location for convenient usage in diverse downstream tasks. We show that SatCLIP embeddings, pretrained on globally sampled multi-spectral Sentinel-2 satellite data, can be used in various predictive tasks that depend on location information but not necessarily satellite imagery, including temperature prediction, animal recognition in imagery, and population density estimation. Across tasks, SatCLIP embeddings consistently outperform embeddings from existing pretrained location encoders, ranging from models trained on natural images to models trained on semantic context. SatCLIP embeddings also help to improve geographic generalization. This demonstrates the potential of general-purpose location encoders and opens the door to learning meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
AV-RIR: Audio-Visual Room Impulse Response Estimation
Nov 30, 2023Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
SPiC-E : Structural Priors in 3D Diffusion Models using Cross-Entity Attention
Nov 30, 2023We are witnessing rapid progress in automatically generating and manipulating 3D assets due to the availability of pretrained text-image diffusion models. However, time-consuming optimization procedures are required for synthesizing each sample, hindering their potential for democratizing 3D content creation. Conversely, 3D diffusion models now train on million-scale 3D datasets, yielding high-quality text-conditional 3D samples within seconds. In this work, we present SPiC-E - a neural network that adds structural guidance to 3D diffusion models, extending their usage beyond text-conditional generation. At its core, our framework introduces a cross-entity attention mechanism that allows for multiple entities (in particular, paired input and guidance 3D shapes) to interact via their internal representations within the denoising network. We utilize this mechanism for learning task-specific structural priors in 3D diffusion models from auxiliary guidance shapes. We show that our approach supports a variety of applications, including 3D stylization, semantic shape editing and text-conditional abstraction-to-3D, which transforms primitive-based abstractions into highly-expressive shapes. Extensive experiments demonstrate that SPiC-E achieves SOTA performance over these tasks while often being considerably faster than alternative methods. Importantly, this is accomplished without tailoring our approach for any specific task.
Hy-Tracker: A Novel Framework for Enhancing Efficiency and Accuracy of Object Tracking in Hyperspectral Videos
Nov 30, 2023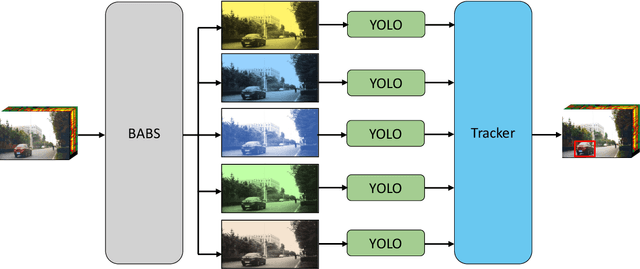
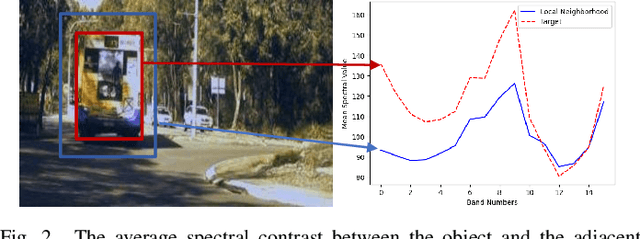
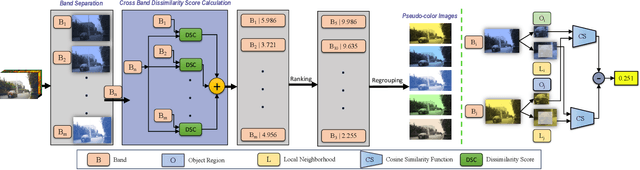
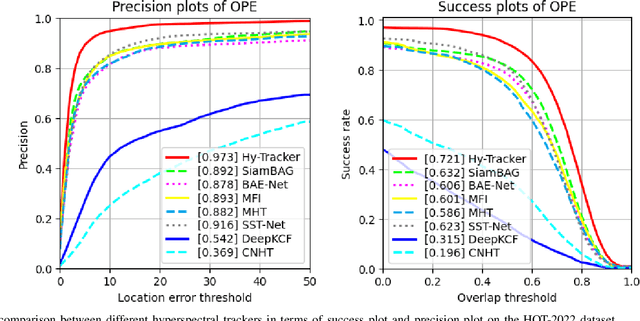
Hyperspectral object tracking has recently emerged as a topic of great interest in the remote sensing community. The hyperspectral image, with its many bands, provides a rich source of material information of an object that can be effectively used for object tracking. While most hyperspectral trackers are based on detection-based techniques, no one has yet attempted to employ YOLO for detecting and tracking the object. This is due to the presence of multiple spectral bands, the scarcity of annotated hyperspectral videos, and YOLO's performance limitation in managing occlusions, and distinguishing object in cluttered backgrounds. Therefore, in this paper, we propose a novel framework called Hy-Tracker, which aims to bridge the gap between hyperspectral data and state-of-the-art object detection methods to leverage the strengths of YOLOv7 for object tracking in hyperspectral videos. Hy-Tracker not only introduces YOLOv7 but also innovatively incorporates a refined tracking module on top of YOLOv7. The tracker refines the initial detections produced by YOLOv7, leading to improved object-tracking performance. Furthermore, we incorporate Kalman-Filter into the tracker, which addresses the challenges posed by scale variation and occlusion. The experimental results on hyperspectral benchmark datasets demonstrate the effectiveness of Hy-Tracker in accurately tracking objects across frames.
EMIT-Diff: Enhancing Medical Image Segmentation via Text-Guided Diffusion Model
Oct 19, 2023Large-scale, big-variant, and high-quality data are crucial for developing robust and successful deep-learning models for medical applications since they potentially enable better generalization performance and avoid overfitting. However, the scarcity of high-quality labeled data always presents significant challenges. This paper proposes a novel approach to address this challenge by developing controllable diffusion models for medical image synthesis, called EMIT-Diff. We leverage recent diffusion probabilistic models to generate realistic and diverse synthetic medical image data that preserve the essential characteristics of the original medical images by incorporating edge information of objects to guide the synthesis process. In our approach, we ensure that the synthesized samples adhere to medically relevant constraints and preserve the underlying structure of imaging data. Due to the random sampling process by the diffusion model, we can generate an arbitrary number of synthetic images with diverse appearances. To validate the effectiveness of our proposed method, we conduct an extensive set of medical image segmentation experiments on multiple datasets, including Ultrasound breast (+13.87%), CT spleen (+0.38%), and MRI prostate (+7.78%), achieving significant improvements over the baseline segmentation methods. For the first time, to our best knowledge, the promising results demonstrate the effectiveness of our EMIT-Diff for medical image segmentation tasks and show the feasibility of introducing a first-ever text-guided diffusion model for general medical image segmentation tasks. With carefully designed ablation experiments, we investigate the influence of various data augmentation ratios, hyper-parameter settings, patch size for generating random merging mask settings, and combined influence with different network architectures.