 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Volumetric Cloud Field Reconstruction
Nov 29, 2023
Volumetric phenomena, such as clouds and fog, present a significant challenge for 3D reconstruction systems due to their translucent nature and their complex interactions with light. Conventional techniques for reconstructing scattering volumes rely on controlled setups, limiting practical applications. This paper introduces an approach to reconstructing volumes from a few input stereo pairs. We propose a novel deep learning framework that integrates a deep stereo model with a 3D Convolutional Neural Network (3D CNN) and an advection module, capable of capturing the shape and dynamics of volumes. The stereo depths are used to carve empty space around volumes, providing the 3D CNN with a prior for coping with the lack of input views. Refining our output, the advection module leverages the temporal evolution of the medium, providing a mechanism to infer motion and improve temporal consistency. The efficacy of our system is demonstrated through its ability to estimate density and velocity fields of large-scale volumes, in this case, clouds, from a sparse set of stereo image pairs.
Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning
Nov 29, 2023Recent one-shot video tuning methods, which fine-tune the network on a specific video based on pre-trained text-to-image models (e.g., Stable Diffusion), are popular in the community because of the flexibility. However, these methods often produce videos marred by incoherence and inconsistency. To address these limitations, this paper introduces a simple yet effective noise constraint across video frames. This constraint aims to regulate noise predictions across their temporal neighbors, resulting in smooth latents. It can be simply included as a loss term during the training phase. By applying the loss to existing one-shot video tuning methods, we significantly improve the overall consistency and smoothness of the generated videos. Furthermore, we argue that current video evaluation metrics inadequately capture smoothness. To address this, we introduce a novel metric that considers detailed features and their temporal dynamics. Experimental results validate the effectiveness of our approach in producing smoother videos on various one-shot video tuning baselines. The source codes and video demos are available at \href{https://github.com/SPengLiang/SmoothVideo}{https://github.com/SPengLiang/SmoothVideo}.
Federated Fine-Tuning of Foundation Models via Probabilistic Masking
Nov 29, 2023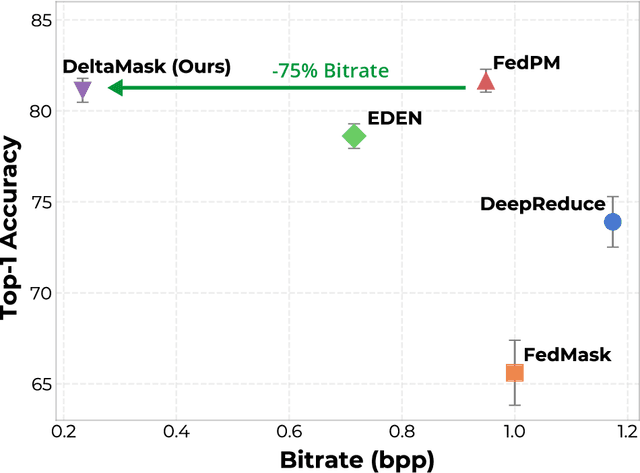

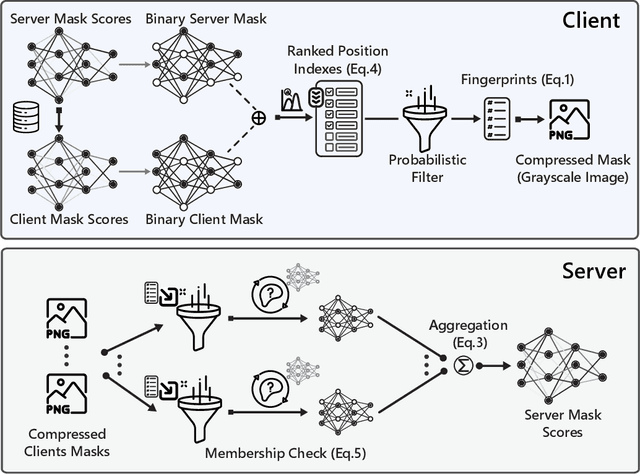
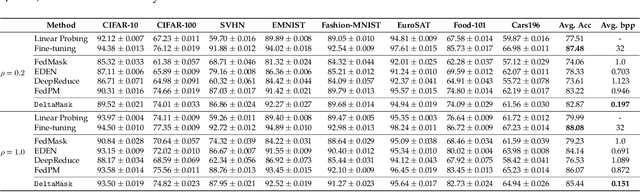
Foundation Models (FMs) have revolutionized machine learning with their adaptability and high performance across tasks; yet, their integration into Federated Learning (FL) is challenging due to substantial communication overhead from their extensive parameterization. Current communication-efficient FL strategies, such as gradient compression, reduce bitrates to around $1$ bit-per-parameter (bpp). However, these approaches fail to harness the characteristics of FMs, with their large number of parameters still posing a challenge to communication efficiency, even at these bitrate regimes. In this work, we present DeltaMask, a novel method that efficiently fine-tunes FMs in FL at an ultra-low bitrate, well below 1 bpp. DeltaMask employs stochastic masking to detect highly effective subnetworks within FMs and leverage stochasticity and sparsity in client masks to compress updates into a compact grayscale image using probabilistic filters, deviating from traditional weight training approaches. Our comprehensive evaluations across various datasets and architectures demonstrate DeltaMask efficiently achieves bitrates as low as 0.09 bpp, enhancing communication efficiency while maintaining FMs performance, as measured on 8 datasets and 5 pre-trained models of various network architectures.
Compressing the Backward Pass of Large-Scale Neural Architectures by Structured Activation Pruning
Nov 29, 2023The rise of Deep Neural Networks (DNNs) has led to an increase in model size and complexity, straining the memory capacity of GPUs. Sparsity in DNNs, characterized as structural or ephemeral, has gained attention as a solution. This work focuses on ephemeral sparsity, aiming to reduce memory consumption during training. It emphasizes the significance of activations, an often overlooked component, and their role in memory usage. This work employs structured pruning in Block Sparse Compressed Row (BSR) format in combination with a magnitude-based criterion to efficiently prune activations. We furthermore introduce efficient block-sparse operators for GPUs and showcase their effectiveness, as well as the superior compression offered by block sparsity. We report the effectiveness of activation pruning by evaluating training speed, accuracy, and memory usage of large-scale neural architectures on the example of ResMLP on image classification tasks. As a result, we observe a memory reduction of up to 32% while maintaining accuracy. Ultimately, our approach aims to democratize large-scale model training, reduce GPU requirements, and address ecological concerns.
NeRFTAP: Enhancing Transferability of Adversarial Patches on Face Recognition using Neural Radiance Fields
Nov 29, 2023Face recognition (FR) technology plays a crucial role in various applications, but its vulnerability to adversarial attacks poses significant security concerns. Existing research primarily focuses on transferability to different FR models, overlooking the direct transferability to victim's face images, which is a practical threat in real-world scenarios. In this study, we propose a novel adversarial attack method that considers both the transferability to the FR model and the victim's face image, called NeRFTAP. Leveraging NeRF-based 3D-GAN, we generate new view face images for the source and target subjects to enhance transferability of adversarial patches. We introduce a style consistency loss to ensure the visual similarity between the adversarial UV map and the target UV map under a 0-1 mask, enhancing the effectiveness and naturalness of the generated adversarial face images. Extensive experiments and evaluations on various FR models demonstrate the superiority of our approach over existing attack techniques. Our work provides valuable insights for enhancing the robustness of FR systems in practical adversarial settings.
Using Stochastic Gradient Descent to Smooth Nonconvex Functions: Analysis of Implicit Graduated Optimization with Optimal Noise Scheduling
Nov 29, 2023The graduated optimization approach is a heuristic method for finding globally optimal solutions for nonconvex functions and has been theoretically analyzed in several studies. This paper defines a new family of nonconvex functions for graduated optimization, discusses their sufficient conditions, and provides a convergence analysis of the graduated optimization algorithm for them. It shows that stochastic gradient descent (SGD) with mini-batch stochastic gradients has the effect of smoothing the function, the degree of which is determined by the learning rate and batch size. This finding provides theoretical insights on why large batch sizes fall into sharp local minima, why decaying learning rates and increasing batch sizes are superior to fixed learning rates and batch sizes, and what the optimal learning rate scheduling is. To the best of our knowledge, this is the first paper to provide a theoretical explanation for these aspects. Moreover, a new graduated optimization framework that uses a decaying learning rate and increasing batch size is analyzed and experimental results of image classification that support our theoretical findings are reported.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 29, 2023Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.
Enhancing Rock Image Segmentation in Digital Rock Physics: A Fusion of Generative AI and State-of-the-Art Neural Networks
Nov 10, 2023In digital rock physics, analysing microstructures from CT and SEM scans is crucial for estimating properties like porosity and pore connectivity. Traditional segmentation methods like thresholding and CNNs often fall short in accurately detailing rock microstructures and are prone to noise. U-Net improved segmentation accuracy but required many expert-annotated samples, a laborious and error-prone process due to complex pore shapes. Our study employed an advanced generative AI model, the diffusion model, to overcome these limitations. This model generated a vast dataset of CT/SEM and binary segmentation pairs from a small initial dataset. We assessed the efficacy of three neural networks: U-Net, Attention-U-net, and TransUNet, for segmenting these enhanced images. The diffusion model proved to be an effective data augmentation technique, improving the generalization and robustness of deep learning models. TransU-Net, incorporating Transformer structures, demonstrated superior segmentation accuracy and IoU metrics, outperforming both U-Net and Attention-U-net. Our research advances rock image segmentation by combining the diffusion model with cutting-edge neural networks, reducing dependency on extensive expert data and boosting segmentation accuracy and robustness. TransU-Net sets a new standard in digital rock physics, paving the way for future geoscience and engineering breakthroughs.
Towards Accurate Loop Closure Detection in Semantic SLAM with 3D Semantic Covisibility Graphs
Nov 21, 2023Loop closure is necessary for correcting errors accumulated in simultaneous localization and mapping (SLAM) in unknown environments. However, conventional loop closure methods based on low-level geometric or image features may cause high ambiguity by not distinguishing similar scenarios. Thus, incorrect loop closures can occur. Though semantic 2D image information is considered in some literature to detect loop closures, there is little work that compares 3D scenes as an integral part of a semantic SLAM system. This paper introduces an approach, called SmSLAM+LCD, integrated into a semantic SLAM system to combine high-level 3D semantic information and low-level feature information to conduct accurate loop closure detection and effective drift reduction. The effectiveness of our approach is demonstrated in testing results.
Sentence-level Prompts Benefit Composed Image Retrieval
Oct 09, 2023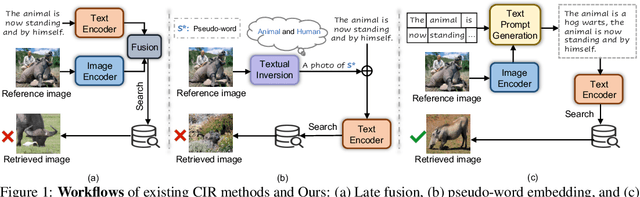
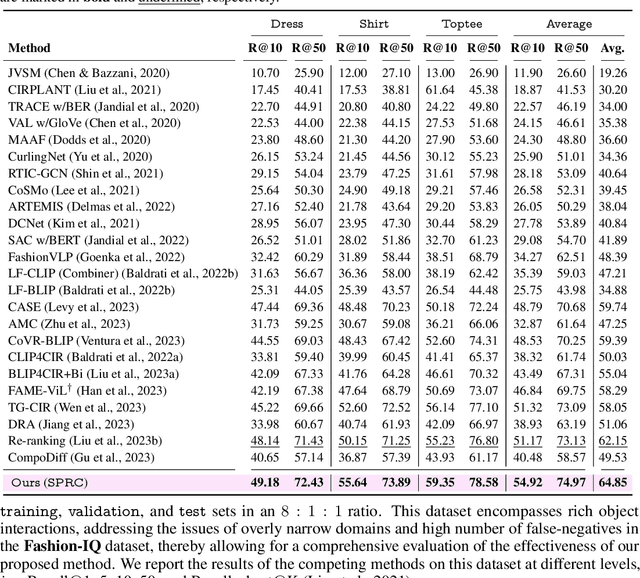
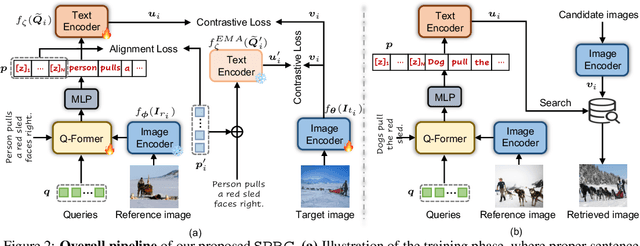
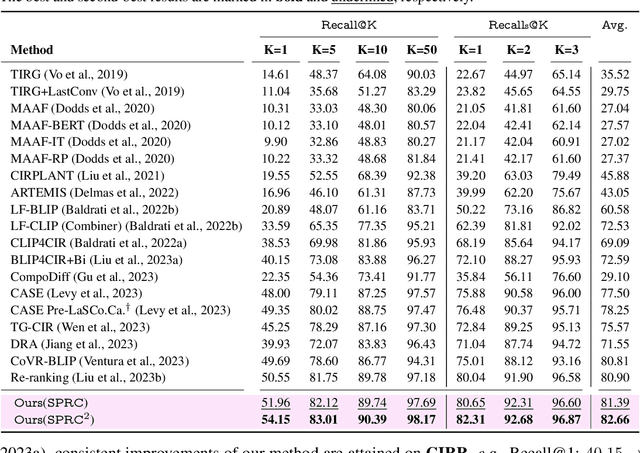
Composed image retrieval (CIR) is the task of retrieving specific images by using a query that involves both a reference image and a relative caption. Most existing CIR models adopt the late-fusion strategy to combine visual and language features. Besides, several approaches have also been suggested to generate a pseudo-word token from the reference image, which is further integrated into the relative caption for CIR. However, these pseudo-word-based prompting methods have limitations when target image encompasses complex changes on reference image, e.g., object removal and attribute modification. In this work, we demonstrate that learning an appropriate sentence-level prompt for the relative caption (SPRC) is sufficient for achieving effective composed image retrieval. Instead of relying on pseudo-word-based prompts, we propose to leverage pretrained V-L models, e.g., BLIP-2, to generate sentence-level prompts. By concatenating the learned sentence-level prompt with the relative caption, one can readily use existing text-based image retrieval models to enhance CIR performance. Furthermore, we introduce both image-text contrastive loss and text prompt alignment loss to enforce the learning of suitable sentence-level prompts. Experiments show that our proposed method performs favorably against the state-of-the-art CIR methods on the Fashion-IQ and CIRR datasets. The source code and pretrained model are publicly available at https://github.com/chunmeifeng/SPRC