 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Benchmarking Feature Extractors for Reinforcement Learning-Based Semiconductor Defect Localization
Nov 18, 2023

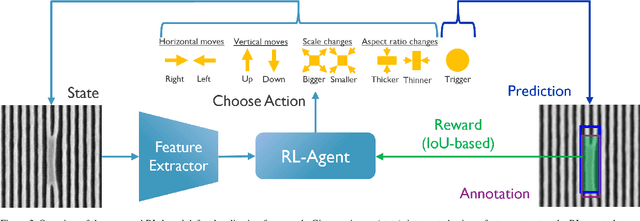
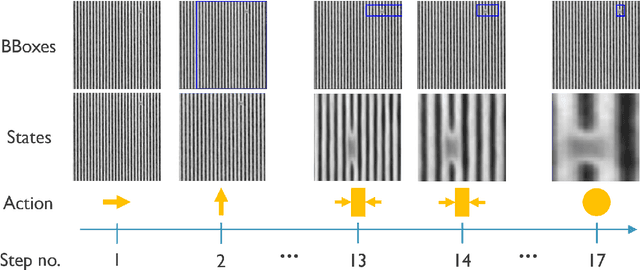

As semiconductor patterning dimensions shrink, more advanced Scanning Electron Microscopy (SEM) image-based defect inspection techniques are needed. Recently, many Machine Learning (ML)-based approaches have been proposed for defect localization and have shown impressive results. These methods often rely on feature extraction from a full SEM image and possibly a number of regions of interest. In this study, we propose a deep Reinforcement Learning (RL)-based approach to defect localization which iteratively extracts features from increasingly smaller regions of the input image. We compare the results of 18 agents trained with different feature extractors. We discuss the advantages and disadvantages of different feature extractors as well as the RL-based framework in general for semiconductor defect localization.
* 5 pages, 5 figures, 3 tables
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
TOSS:High-quality Text-guided Novel View Synthesis from a Single Image
Oct 16, 2023In this paper, we present TOSS, which introduces text to the task of novel view synthesis (NVS) from just a single RGB image. While Zero-1-to-3 has demonstrated impressive zero-shot open-set NVS capability, it treats NVS as a pure image-to-image translation problem. This approach suffers from the challengingly under-constrained nature of single-view NVS: the process lacks means of explicit user control and often results in implausible NVS generations. To address this limitation, TOSS uses text as high-level semantic information to constrain the NVS solution space. TOSS fine-tunes text-to-image Stable Diffusion pre-trained on large-scale text-image pairs and introduces modules specifically tailored to image and camera pose conditioning, as well as dedicated training for pose correctness and preservation of fine details. Comprehensive experiments are conducted with results showing that our proposed TOSS outperforms Zero-1-to-3 with more plausible, controllable and multiview-consistent NVS results. We further support these results with comprehensive ablations that underscore the effectiveness and potential of the introduced semantic guidance and architecture design.
Few-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.
ACT: Adversarial Consistency Models
Nov 23, 2023Though diffusion models excel in image generation, their step-by-step denoising leads to slow generation speeds. Consistency training addresses this issue with single-step sampling but often produces lower-quality generations and requires high training costs. In this paper, we show that optimizing consistency training loss minimizes the Wasserstein distance between target and generated distributions. As timestep increases, the upper bound accumulates previous consistency training losses. Therefore, larger batch sizes are needed to reduce both current and accumulated losses. We propose Adversarial Consistency Training (ACT), which directly minimizes the Jensen-Shannon (JS) divergence between distributions at each timestep using a discriminator. Theoretically, ACT enhances generation quality, and convergence. By incorporating a discriminator into the consistency training framework, our method achieves improved FID scores on CIFAR10 and ImageNet 64$\times$64, retains zero-shot image inpainting capabilities, and uses less than $1/6$ of the original batch size and fewer than $1/2$ of the model parameters and training steps compared to the baseline method, this leads to a substantial reduction in resource consumption.
HOMOE: A Memory-Based and Composition-Aware Framework for Zero-Shot Learning with Hopfield Network and Soft Mixture of Experts
Nov 23, 2023Compositional Zero-Shot Learning (CZSL) has emerged as an essential paradigm in machine learning, aiming to overcome the constraints of traditional zero-shot learning by incorporating compositional thinking into its methodology. Conventional zero-shot learning has difficulty managing unfamiliar combinations of seen and unseen classes because it depends on pre-defined class embeddings. In contrast, Compositional Zero-Shot Learning uses the inherent hierarchies and structural connections among classes, creating new class representations by combining attributes, components, or other semantic elements. In our paper, we propose a novel framework that for the first time combines the Modern Hopfield Network with a Mixture of Experts (HOMOE) to classify the compositions of previously unseen objects. Specifically, the Modern Hopfield Network creates a memory that stores label prototypes and identifies relevant labels for a given input image. Following this, the Mixture of Expert models integrates the image with the fitting prototype to produce the final composition classification. Our approach achieves SOTA performance on several benchmarks, including MIT-States and UT-Zappos. We also examine how each component contributes to improved generalization.
3D-GOI: 3D GAN Omni-Inversion for Multifaceted and Multi-object Editing
Nov 23, 2023The current GAN inversion methods typically can only edit the appearance and shape of a single object and background while overlooking spatial information. In this work, we propose a 3D editing framework, 3D-GOI, to enable multifaceted editing of affine information (scale, translation, and rotation) on multiple objects. 3D-GOI realizes the complex editing function by inverting the abundance of attribute codes (object shape/appearance/scale/rotation/translation, background shape/appearance, and camera pose) controlled by GIRAFFE, a renowned 3D GAN. Accurately inverting all the codes is challenging, 3D-GOI solves this challenge following three main steps. First, we segment the objects and the background in a multi-object image. Second, we use a custom Neural Inversion Encoder to obtain coarse codes of each object. Finally, we use a round-robin optimization algorithm to get precise codes to reconstruct the image. To the best of our knowledge, 3D-GOI is the first framework to enable multifaceted editing on multiple objects. Both qualitative and quantitative experiments demonstrate that 3D-GOI holds immense potential for flexible, multifaceted editing in complex multi-object scenes.
Perceptual Assessment and Optimization of High Dynamic Range Image Rendering
Oct 19, 2023High dynamic range (HDR) imaging has gained increasing popularity for its ability to faithfully reproduce the luminance levels in natural scenes. Accordingly, HDR image quality assessment (IQA) is crucial but has been superficially treated. The majority of existing IQA models are developed for and calibrated against low dynamic range (LDR) images, which have been shown to be poorly correlated with human perception of HDR image quality. In this work, we propose a family of HDR IQA models by transferring the recent advances in LDR IQA. The key step in our approach is to specify a simple inverse display model that decomposes an HDR image to a set of LDR images with different exposures, which will be assessed by existing LDR quality models. The local quality scores of each exposure are then aggregated with the help of a simple well-exposedness measure into a global quality score for each exposure, which will be further weighted across exposures to obtain the overall quality score. When assessing LDR images, the proposed HDR quality models reduce gracefully to the original LDR ones with the same performance. Experiments on four human-rated HDR image datasets demonstrate that our HDR quality models are consistently better than existing IQA methods, including the HDR-VDP family. Moreover, we demonstrate their strengths in perceptual optimization of HDR novel view synthesis.
Leveraging Unlabeled Data for 3D Medical Image Segmentation through Self-Supervised Contrastive Learning
Nov 21, 2023Current 3D semi-supervised segmentation methods face significant challenges such as limited consideration of contextual information and the inability to generate reliable pseudo-labels for effective unsupervised data use. To address these challenges, we introduce two distinct subnetworks designed to explore and exploit the discrepancies between them, ultimately correcting the erroneous prediction results. More specifically, we identify regions of inconsistent predictions and initiate a targeted verification training process. This procedure strategically fine-tunes and harmonizes the predictions of the subnetworks, leading to enhanced utilization of contextual information. Furthermore, to adaptively fine-tune the network's representational capacity and reduce prediction uncertainty, we employ a self-supervised contrastive learning paradigm. For this, we use the network's confidence to distinguish between reliable and unreliable predictions. The model is then trained to effectively minimize unreliable predictions. Our experimental results for organ segmentation, obtained from clinical MRI and CT scans, demonstrate the effectiveness of our approach when compared to state-of-the-art methods. The codebase is accessible on \href{https://github.com/xmindflow/SSL-contrastive}{GitHub}.
Compressing the Backward Pass of Large-Scale Neural Architectures by Structured Activation Pruning
Nov 29, 2023The rise of Deep Neural Networks (DNNs) has led to an increase in model size and complexity, straining the memory capacity of GPUs. Sparsity in DNNs, characterized as structural or ephemeral, has gained attention as a solution. This work focuses on ephemeral sparsity, aiming to reduce memory consumption during training. It emphasizes the significance of activations, an often overlooked component, and their role in memory usage. This work employs structured pruning in Block Sparse Compressed Row (BSR) format in combination with a magnitude-based criterion to efficiently prune activations. We furthermore introduce efficient block-sparse operators for GPUs and showcase their effectiveness, as well as the superior compression offered by block sparsity. We report the effectiveness of activation pruning by evaluating training speed, accuracy, and memory usage of large-scale neural architectures on the example of ResMLP on image classification tasks. As a result, we observe a memory reduction of up to 32% while maintaining accuracy. Ultimately, our approach aims to democratize large-scale model training, reduce GPU requirements, and address ecological concerns.