 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Can SAM recognize crops? Quantifying the zero-shot performance of a semantic segmentation foundation model on generating crop-type maps using satellite imagery for precision agriculture
Nov 25, 2023
Climate change is increasingly disrupting worldwide agriculture, making global food production less reliable.To tackle the growing challenges in feeding the planet, cutting-edge management strategies, such as precision agriculture, empower farmers and decision-makers with rich and actionable information to increase the efficiency and sustainability of their farming practices.Crop-type maps are key information for decision-support tools but are challenging and costly to generate.We investigate the capabilities of Meta AI's Segment Anything Model (SAM) for crop-map prediction task, acknowledging its recent successes at zero-shot image segmentation.However, SAM being limited to up-to 3 channel inputs and its zero-shot usage being class-agnostic in nature pose unique challenges in using it directly for crop-type mapping.We propose using clustering consensus metrics to assess SAM's zero-shot performance in segmenting satellite imagery and producing crop-type maps.Although direct crop-type mapping is challenging using SAM in zero-shot setting, experiments reveal SAM's potential for swiftly and accurately outlining fields in satellite images, serving as a foundation for subsequent crop classification.This paper attempts to highlight a use-case of state-of-the-art image segmentation models like SAM for crop-type mapping and related specific needs of the agriculture industry, offering a potential avenue for automatic, efficient, and cost-effective data products for precision agriculture practices.
X-Ray to CT Rigid Registration Using Scene Coordinate Regression
Nov 25, 2023Intraoperative fluoroscopy is a frequently used modality in minimally invasive orthopedic surgeries. Aligning the intraoperatively acquired X-ray image with the preoperatively acquired 3D model of a computed tomography (CT) scan reduces the mental burden on surgeons induced by the overlapping anatomical structures in the acquired images. This paper proposes a fully automatic registration method that is robust to extreme viewpoints and does not require manual annotation of landmark points during training. It is based on a fully convolutional neural network (CNN) that regresses the scene coordinates for a given X-ray image. The scene coordinates are defined as the intersection of the back-projected rays from a pixel toward the 3D model. Training data for a patient-specific model were generated through a realistic simulation of a C-arm device using preoperative CT scans. In contrast, intraoperative registration was achieved by solving the perspective-n-point (PnP) problem with a random sample and consensus (RANSAC) algorithm. Experiments were conducted using a pelvic CT dataset that included several real fluoroscopic (X-ray) images with ground truth annotations. The proposed method achieved an average mean target registration error (mTRE) of 3.79 mm in the 50th percentile of the simulated test dataset and projected mTRE of 9.65 mm in the 50th percentile of real fluoroscopic images for pelvis registration.
Learning Site-specific Styles for Multi-institutional Unsupervised Cross-modality Domain Adaptation
Nov 21, 2023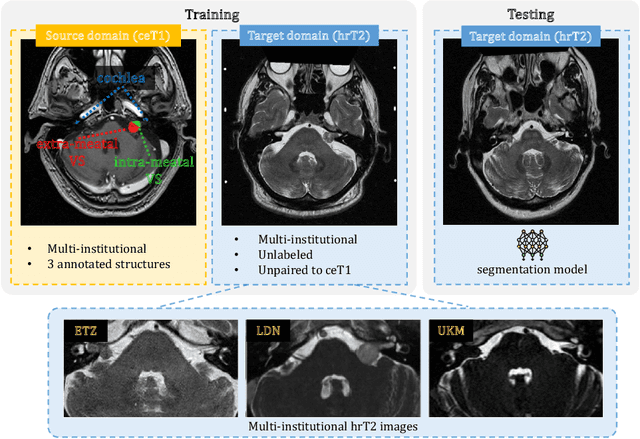
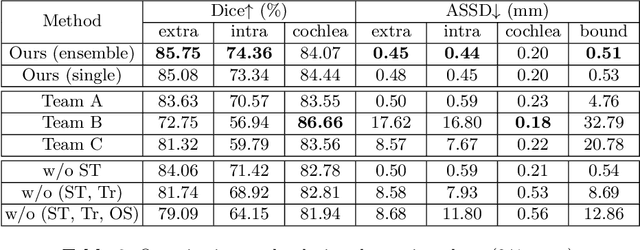
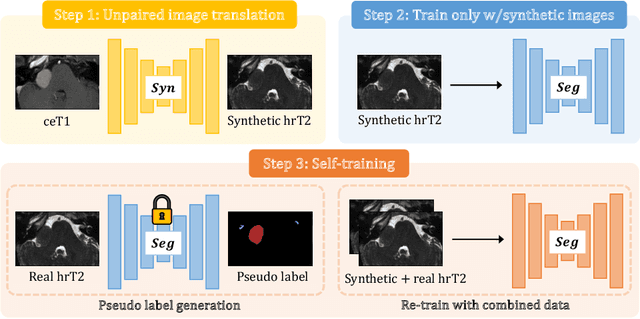
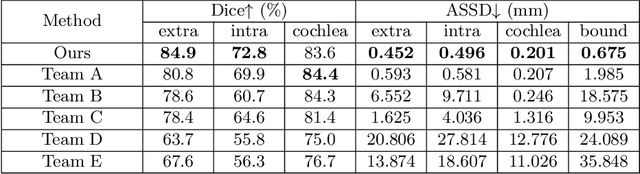
Unsupervised cross-modality domain adaptation is a challenging task in medical image analysis, and it becomes more challenging when source and target domain data are collected from multiple institutions. In this paper, we present our solution to tackle the multi-institutional unsupervised domain adaptation for the crossMoDA 2023 challenge. First, we perform unpaired image translation to translate the source domain images to the target domain, where we design a dynamic network to generate synthetic target domain images with controllable, site-specific styles. Afterwards, we train a segmentation model using the synthetic images and further reduce the domain gap by self-training. Our solution achieved the 1st place during both the validation and testing phases of the challenge.
DeepCache: Accelerating Diffusion Models for Free
Dec 01, 2023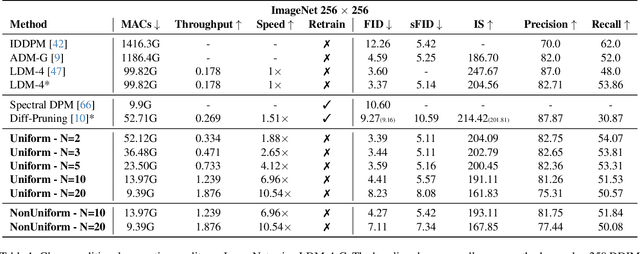
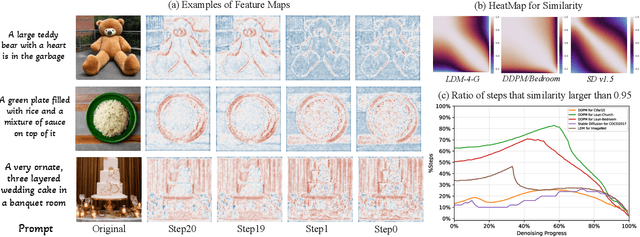
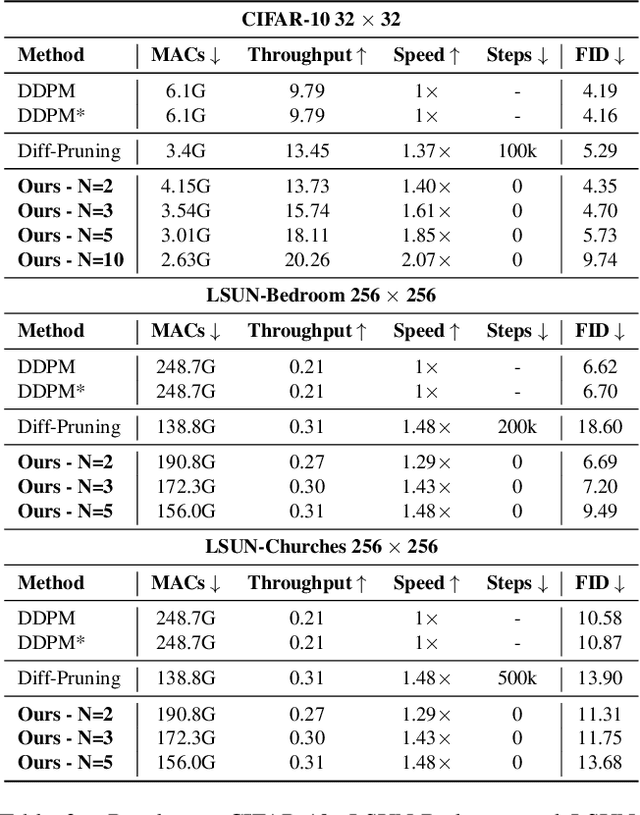
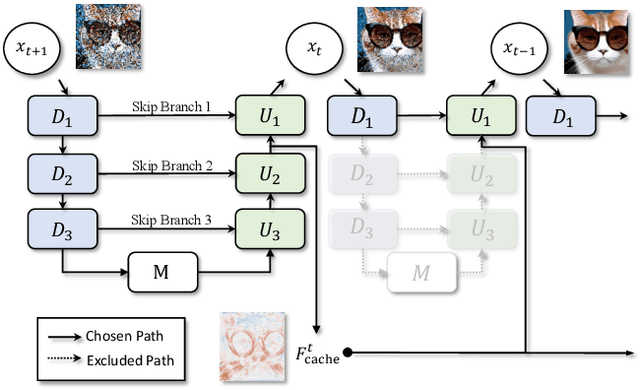
Diffusion models have recently gained unprecedented attention in the field of image synthesis due to their remarkable generative capabilities. Notwithstanding their prowess, these models often incur substantial computational costs, primarily attributed to the sequential denoising process and cumbersome model size. Traditional methods for compressing diffusion models typically involve extensive retraining, presenting cost and feasibility challenges. In this paper, we introduce DeepCache, a novel training-free paradigm that accelerates diffusion models from the perspective of model architecture. DeepCache capitalizes on the inherent temporal redundancy observed in the sequential denoising steps of diffusion models, which caches and retrieves features across adjacent denoising stages, thereby curtailing redundant computations. Utilizing the property of the U-Net, we reuse the high-level features while updating the low-level features in a very cheap way. This innovative strategy, in turn, enables a speedup factor of 2.3$\times$ for Stable Diffusion v1.5 with only a 0.05 decline in CLIP Score, and 4.1$\times$ for LDM-4-G with a slight decrease of 0.22 in FID on ImageNet. Our experiments also demonstrate DeepCache's superiority over existing pruning and distillation methods that necessitate retraining and its compatibility with current sampling techniques. Furthermore, we find that under the same throughput, DeepCache effectively achieves comparable or even marginally improved results with DDIM or PLMS. The code is available at https://github.com/horseee/DeepCache
Large-scale Vision-Language Models Learn Super Images for Efficient and High-Performance Partially Relevant Video Retrieval
Dec 01, 2023In this paper, we propose an efficient and high-performance method for partially relevant video retrieval (PRVR), which aims to retrieve untrimmed long videos that contain at least one relevant moment to the input text query. In terms of both efficiency and performance, the overlooked bottleneck of previous studies is the visual encoding of dense frames. This guides researchers to choose lightweight visual backbones, yielding sub-optimal retrieval performance due to their limited capabilities of learned visual representations. However, it is undesirable to simply replace them with high-performance large-scale vision-and-language models (VLMs) due to their low efficiency. To address these issues, instead of dense frames, we focus on super images, which are created by rearranging the video frames in a $N \times N$ grid layout. This reduces the number of visual encodings to $\frac{1}{N^2}$ and compensates for the low efficiency of large-scale VLMs, allowing us to adopt them as powerful encoders. Surprisingly, we discover that with a simple query-image attention trick, VLMs generalize well to super images effectively and demonstrate promising zero-shot performance against SOTA methods efficiently. In addition, we propose a fine-tuning approach by incorporating a few trainable modules into the VLM backbones. The experimental results demonstrate that our approaches efficiently achieve the best performance on ActivityNet Captions and TVR.
Robust Diffusion GAN using Semi-Unbalanced Optimal Transport
Nov 28, 2023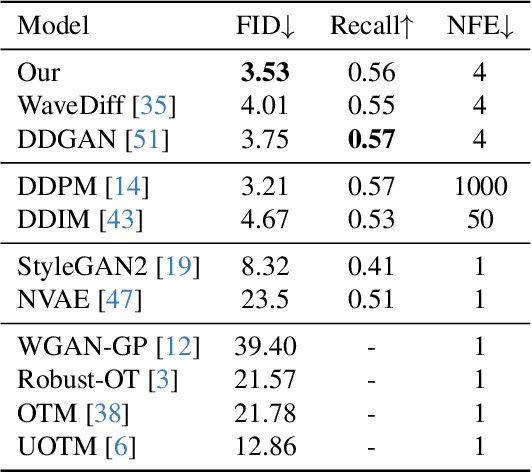

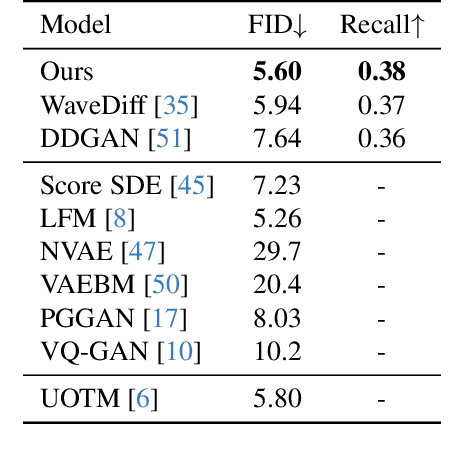
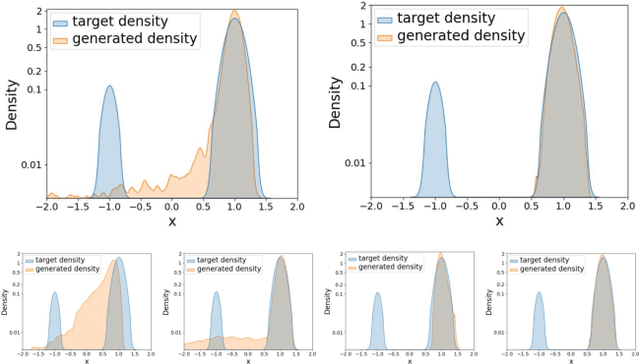
Diffusion models, a type of generative model, have demonstrated great potential for synthesizing highly detailed images. By integrating with GAN, advanced diffusion models like DDGAN \citep{xiao2022DDGAN} could approach real-time performance for expansive practical applications. While DDGAN has effectively addressed the challenges of generative modeling, namely producing high-quality samples, covering different data modes, and achieving faster sampling, it remains susceptible to performance drops caused by datasets that are corrupted with outlier samples. This work introduces a robust training technique based on semi-unbalanced optimal transport to mitigate the impact of outliers effectively. Through comprehensive evaluations, we demonstrate that our robust diffusion GAN (RDGAN) outperforms vanilla DDGAN in terms of the aforementioned generative modeling criteria, i.e., image quality, mode coverage of distribution, and inference speed, and exhibits improved robustness when dealing with both clean and corrupted datasets.
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
PanBench: Towards High-Resolution and High-Performance Pansharpening
Nov 20, 2023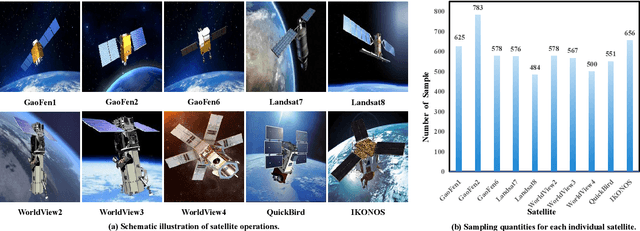
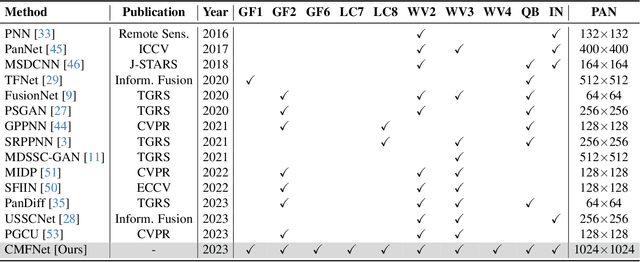
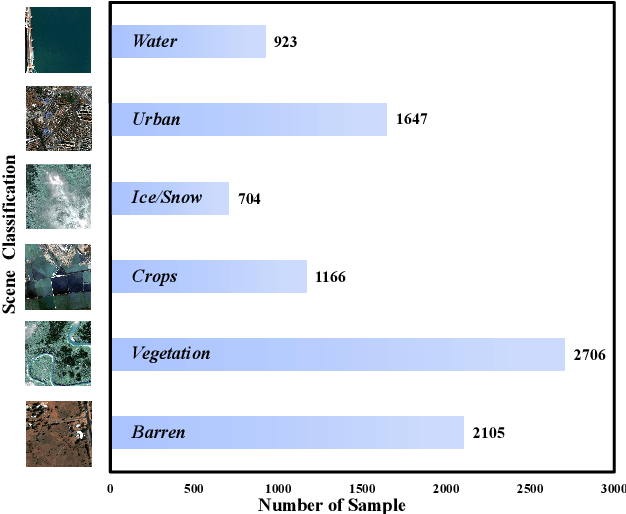
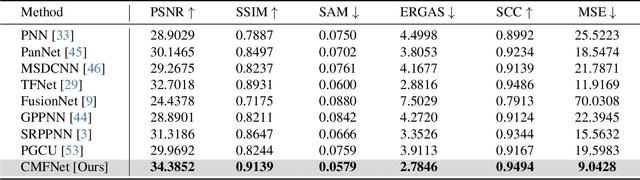
Pansharpening, a pivotal task in remote sensing, involves integrating low-resolution multispectral images with high-resolution panchromatic images to synthesize an image that is both high-resolution and retains multispectral information. These pansharpened images enhance precision in land cover classification, change detection, and environmental monitoring within remote sensing data analysis. While deep learning techniques have shown significant success in pansharpening, existing methods often face limitations in their evaluation, focusing on restricted satellite data sources, single scene types, and low-resolution images. This paper addresses this gap by introducing PanBench, a high-resolution multi-scene dataset containing all mainstream satellites and comprising 5,898 pairs of samples. Each pair includes a four-channel (RGB + near-infrared) multispectral image of 256x256 pixels and a mono-channel panchromatic image of 1,024x1,024 pixels. To achieve high-fidelity synthesis, we propose a Cascaded Multiscale Fusion Network (CMFNet) for Pansharpening. Extensive experiments validate the effectiveness of CMFNet. We have released the dataset, source code, and pre-trained models in the supplementary, fostering further research in remote sensing.
Practical cross-sensor color constancy using a dual-mapping strategy
Nov 20, 2023Deep Neural Networks (DNNs) have been widely used for illumination estimation, which is time-consuming and requires sensor-specific data collection. Our proposed method uses a dual-mapping strategy and only requires a simple white point from a test sensor under a D65 condition. This allows us to derive a mapping matrix, enabling the reconstructions of image data and illuminants. In the second mapping phase, we transform the re-constructed image data into sparse features, which are then optimized with a lightweight multi-layer perceptron (MLP) model using the re-constructed illuminants as ground truths. This approach effectively reduces sensor discrepancies and delivers performance on par with leading cross-sensor methods. It only requires a small amount of memory (~0.003 MB), and takes ~1 hour training on an RTX3070Ti GPU. More importantly, the method can be implemented very fast, with ~0.3 ms and ~1 ms on a GPU or CPU respectively, and is not sensitive to the input image resolution. Therefore, it offers a practical solution to the great challenges of data recollection that is faced by the industry.
Benchmarking Feature Extractors for Reinforcement Learning-Based Semiconductor Defect Localization
Nov 18, 2023
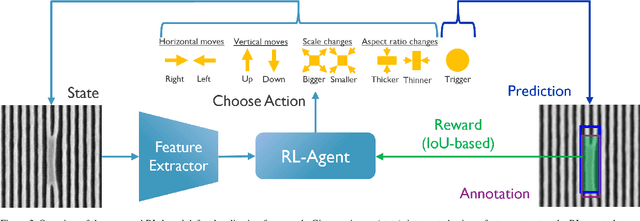
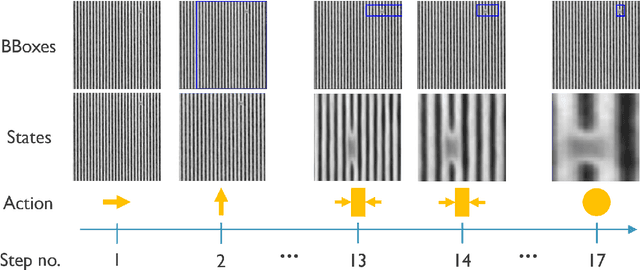

As semiconductor patterning dimensions shrink, more advanced Scanning Electron Microscopy (SEM) image-based defect inspection techniques are needed. Recently, many Machine Learning (ML)-based approaches have been proposed for defect localization and have shown impressive results. These methods often rely on feature extraction from a full SEM image and possibly a number of regions of interest. In this study, we propose a deep Reinforcement Learning (RL)-based approach to defect localization which iteratively extracts features from increasingly smaller regions of the input image. We compare the results of 18 agents trained with different feature extractors. We discuss the advantages and disadvantages of different feature extractors as well as the RL-based framework in general for semiconductor defect localization.
* 5 pages, 5 figures, 3 tables