 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
META4: Semantically-Aligned Generation of Metaphoric Gestures Using Self-Supervised Text and Speech Representation
Nov 21, 2023
Image Schemas are repetitive cognitive patterns that influence the way we conceptualize and reason about various concepts present in speech. These patterns are deeply embedded within our cognitive processes and are reflected in our bodily expressions including gestures. Particularly, metaphoric gestures possess essential characteristics and semantic meanings that align with Image Schemas, to visually represent abstract concepts. The shape and form of gestures can convey abstract concepts, such as extending the forearm and hand or tracing a line with hand movements to visually represent the image schema of PATH. Previous behavior generation models have primarily focused on utilizing speech (acoustic features and text) to drive the generation model of virtual agents. They have not considered key semantic information as those carried by Image Schemas to effectively generate metaphoric gestures. To address this limitation, we introduce META4, a deep learning approach that generates metaphoric gestures from both speech and Image Schemas. Our approach has two primary goals: computing Image Schemas from input text to capture the underlying semantic and metaphorical meaning, and generating metaphoric gestures driven by speech and the computed image schemas. Our approach is the first method for generating speech driven metaphoric gestures while leveraging the potential of Image Schemas. We demonstrate the effectiveness of our approach and highlight the importance of both speech and image schemas in modeling metaphoric gestures.
BiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys
Oct 21, 2023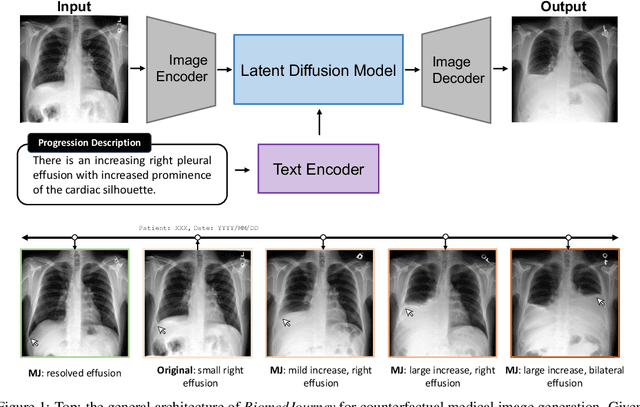
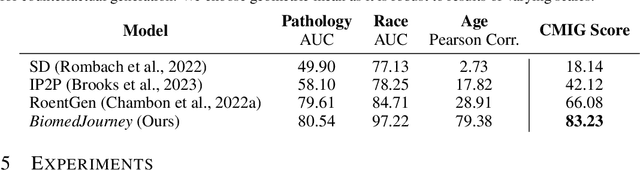
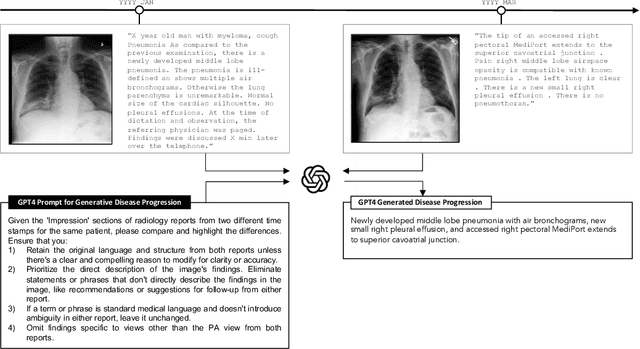
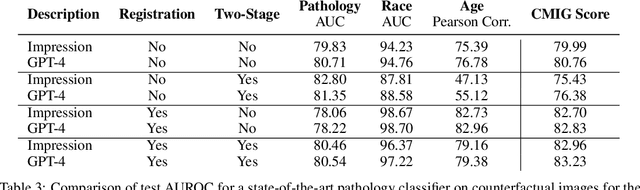
Rapid progress has been made in instruction-learning for image editing with natural-language instruction, as exemplified by InstructPix2Pix. In biomedicine, such methods can be applied to counterfactual image generation, which helps differentiate causal structure from spurious correlation and facilitate robust image interpretation for disease progression modeling. However, generic image-editing models are ill-suited for the biomedical domain, and counterfactual biomedical image generation is largely underexplored. In this paper, we present BiomedJourney, a novel method for counterfactual biomedical image generation by instruction-learning from multimodal patient journeys. Given a patient with two biomedical images taken at different time points, we use GPT-4 to process the corresponding imaging reports and generate a natural language description of disease progression. The resulting triples (prior image, progression description, new image) are then used to train a latent diffusion model for counterfactual biomedical image generation. Given the relative scarcity of image time series data, we introduce a two-stage curriculum that first pretrains the denoising network using the much more abundant single image-report pairs (with dummy prior image), and then continues training using the counterfactual triples. Experiments using the standard MIMIC-CXR dataset demonstrate the promise of our method. In a comprehensive battery of tests on counterfactual medical image generation, BiomedJourney substantially outperforms prior state-of-the-art methods in instruction image editing and medical image generation such as InstructPix2Pix and RoentGen. To facilitate future study in counterfactual medical generation, we plan to release our instruction-learning code and pretrained models.
Augmentation is AUtO-Net: Augmentation-Driven Contrastive Multiview Learning for Medical Image Segmentation
Nov 02, 2023The utilisation of deep learning segmentation algorithms that learn complex organs and tissue patterns and extract essential regions of interest from the noisy background to improve the visual ability for medical image diagnosis has achieved impressive results in Medical Image Computing (MIC). This thesis focuses on retinal blood vessel segmentation tasks, providing an extensive literature review of deep learning-based medical image segmentation approaches while comparing the methodologies and empirical performances. The work also examines the limitations of current state-of-the-art methods by pointing out the two significant existing limitations: data size constraints and the dependency on high computational resources. To address such problems, this work proposes a novel efficient, simple multiview learning framework that contrastively learns invariant vessel feature representation by comparing with multiple augmented views by various transformations to overcome data shortage and improve generalisation ability. Moreover, the hybrid network architecture integrates the attention mechanism into a Convolutional Neural Network to further capture complex continuous curvilinear vessel structures. The result demonstrates the proposed method validated on the CHASE-DB1 dataset, attaining the highest F1 score of 83.46% and the highest Intersection over Union (IOU) score of 71.62% with UNet structure, surpassing existing benchmark UNet-based methods by 1.95% and 2.8%, respectively. The combination of the metrics indicates the model detects the vessel object accurately with a highly coincidental location with the ground truth. Moreover, the proposed approach could be trained within 30 minutes by consuming less than 3 GB GPU RAM, and such characteristics support the efficient implementation for real-world applications and deployments.
Frequency-Aware Transformer for Learned Image Compression
Oct 25, 2023Learned image compression (LIC) has gained traction as an effective solution for image storage and transmission in recent years. However, existing LIC methods are redundant in latent representation due to limitations in capturing anisotropic frequency components and preserving directional details. To overcome these challenges, we propose a novel frequency-aware transformer (FAT) block that for the first time achieves multiscale directional ananlysis for LIC. The FAT block comprises frequency-decomposition window attention (FDWA) modules to capture multiscale and directional frequency components of natural images. Additionally, we introduce frequency-modulation feed-forward network (FMFFN) to adaptively modulate different frequency components, improving rate-distortion performance. Furthermore, we present a transformer-based channel-wise autoregressive (T-CA) model that effectively exploits channel dependencies. Experiments show that our method achieves state-of-the-art rate-distortion performance compared to existing LIC methods, and evidently outperforms latest standardized codec VTM-12.1 by 14.5%, 15.1%, 13.0% in BD-rate on the Kodak, Tecnick, and CLIC datasets.
A 3D Conditional Diffusion Model for Image Quality Transfer -- An Application to Low-Field MRI
Nov 11, 2023Low-field (LF) MRI scanners (<1T) are still prevalent in settings with limited resources or unreliable power supply. However, they often yield images with lower spatial resolution and contrast than high-field (HF) scanners. This quality disparity can result in inaccurate clinician interpretations. Image Quality Transfer (IQT) has been developed to enhance the quality of images by learning a mapping function between low and high-quality images. Existing IQT models often fail to restore high-frequency features, leading to blurry output. In this paper, we propose a 3D conditional diffusion model to improve 3D volumetric data, specifically LF MR images. Additionally, we incorporate a cross-batch mechanism into the self-attention and padding of our network, ensuring broader contextual awareness even under small 3D patches. Experiments on the publicly available Human Connectome Project (HCP) dataset for IQT and brain parcellation demonstrate that our model outperforms existing methods both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/edshkim98/DiffusionIQT}.
Seam-guided local alignment and stitching for large parallax images
Nov 30, 2023Seam-cutting methods have been proven effective in the composition step of image stitching, especially for images with parallax. However, the effectiveness of seam-cutting usually depends on that images can be roughly aligned such that there exists a local region where a plausible seam can be found. For images with large parallax, current alignment methods often fall short of expectations. In this paper, we propose a local alignment and stitching method guided by seam quality evaluation. First, we use existing image alignment and seam-cutting methods to calculate an initial seam and evaluate the quality of pixels along the seam. Then, for pixels with low qualities, we separate their enclosing patches in the aligned images and locally align them by extracting modified dense correspondences via SIFT flow. Finally, we composite the aligned patches via seam-cutting and merge them into the original aligned result to generate the final mosaic. Experiments show that compared with the state-of-the-art seam-cutting methods, our result is more plausible and with fewer artifacts. The code will be available at https://github.com/tlliao/Seam-guided-local-alignment.
Do text-free diffusion models learn discriminative visual representations?
Nov 30, 2023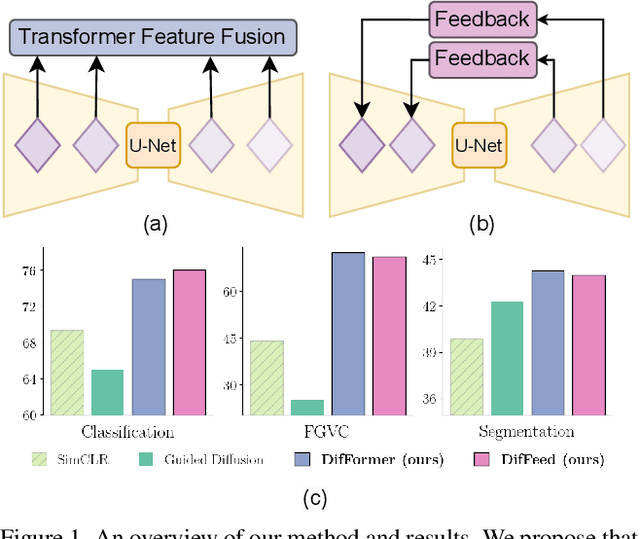
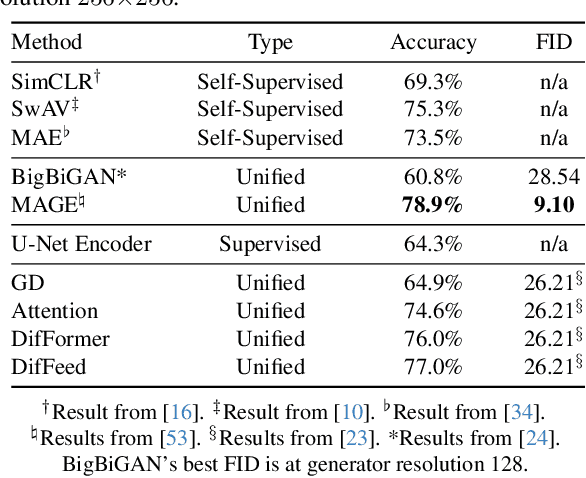
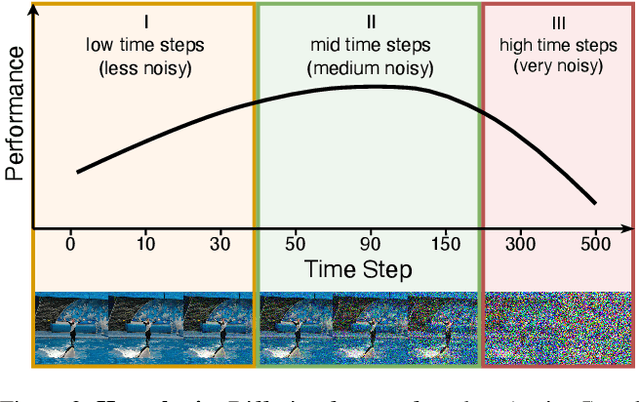
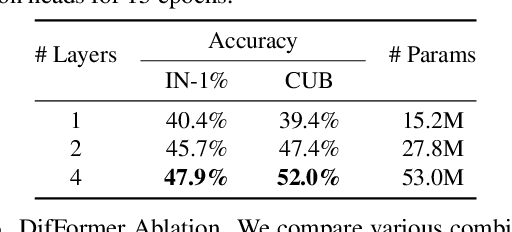
While many unsupervised learning models focus on one family of tasks, either generative or discriminative, we explore the possibility of a unified representation learner: a model which addresses both families of tasks simultaneously. We identify diffusion models, a state-of-the-art method for generative tasks, as a prime candidate. Such models involve training a U-Net to iteratively predict and remove noise, and the resulting model can synthesize high-fidelity, diverse, novel images. We find that the intermediate feature maps of the U-Net are diverse, discriminative feature representations. We propose a novel attention mechanism for pooling feature maps and further leverage this mechanism as DifFormer, a transformer feature fusion of features from different diffusion U-Net blocks and noise steps. We also develop DifFeed, a novel feedback mechanism tailored to diffusion. We find that diffusion models are better than GANs, and, with our fusion and feedback mechanisms, can compete with state-of-the-art unsupervised image representation learning methods for discriminative tasks - image classification with full and semi-supervision, transfer for fine-grained classification, object detection and segmentation, and semantic segmentation. Our project website (https://mgwillia.github.io/diffssl/) and code (https://github.com/soumik-kanad/diffssl) are available publicly.
Can Protective Perturbation Safeguard Personal Data from Being Exploited by Stable Diffusion?
Nov 30, 2023Stable Diffusion has established itself as a foundation model in generative AI artistic applications, receiving widespread research and application. Some recent fine-tuning methods have made it feasible for individuals to implant personalized concepts onto the basic Stable Diffusion model with minimal computational costs on small datasets. However, these innovations have also given rise to issues like facial privacy forgery and artistic copyright infringement. In recent studies, researchers have explored the addition of imperceptible adversarial perturbations to images to prevent potential unauthorized exploitation and infringements when personal data is used for fine-tuning Stable Diffusion. Although these studies have demonstrated the ability to protect images, it is essential to consider that these methods may not be entirely applicable in real-world scenarios. In this paper, we systematically evaluate the use of perturbations to protect images within a practical threat model. The results suggest that these approaches may not be sufficient to safeguard image privacy and copyright effectively. Furthermore, we introduce a purification method capable of removing protected perturbations while preserving the original image structure to the greatest extent possible. Experiments reveal that Stable Diffusion can effectively learn from purified images over all protective methods.
PCDP-SGD: Improving the Convergence of Differentially Private SGD via Projection in Advance
Dec 06, 2023The paradigm of Differentially Private SGD~(DP-SGD) can provide a theoretical guarantee for training data in both centralized and federated settings. However, the utility degradation caused by DP-SGD limits its wide application in high-stakes tasks, such as medical image diagnosis. In addition to the necessary perturbation, the convergence issue is attributed to the information loss on the gradient clipping. In this work, we propose a general framework PCDP-SGD, which aims to compress redundant gradient norms and preserve more crucial top gradient components via projection operation before gradient clipping. Additionally, we extend PCDP-SGD as a fundamental component in differential privacy federated learning~(DPFL) for mitigating the data heterogeneous challenge and achieving efficient communication. We prove that pre-projection enhances the convergence of DP-SGD by reducing the dependence of clipping error and bias to a fraction of the top gradient eigenspace, and in theory, limits cross-client variance to improve the convergence under heterogeneous federation. Experimental results demonstrate that PCDP-SGD achieves higher accuracy compared with state-of-the-art DP-SGD variants in computer vision tasks. Moreover, PCDP-SGD outperforms current federated learning frameworks when DP is guaranteed on local training sets.
AttriHuman-3D: Editable 3D Human Avatar Generation with Attribute Decomposition and Indexing
Dec 06, 2023Editable 3D-aware generation, which supports user-interacted editing, has witnessed rapid development recently. However, existing editable 3D GANs either fail to achieve high-accuracy local editing or suffer from huge computational costs. We propose AttriHuman-3D, an editable 3D human generation model, which address the aforementioned problems with attribute decomposition and indexing. The core idea of the proposed model is to generate all attributes (e.g. human body, hair, clothes and so on) in an overall attribute space with six feature planes, which are then decomposed and manipulated with different attribute indexes. To precisely extract features of different attributes from the generated feature planes, we propose a novel attribute indexing method as well as an orthogonal projection regularization to enhance the disentanglement. We also introduce a hyper-latent training strategy and an attribute-specific sampling strategy to avoid style entanglement and misleading punishment from the discriminator. Our method allows users to interactively edit selected attributes in the generated 3D human avatars while keeping others fixed. Both qualitative and quantitative experiments demonstrate that our model provides a strong disentanglement between different attributes, allows fine-grained image editing and generates high-quality 3D human avatars.