 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BS-Diff: Effective Bone Suppression Using Conditional Diffusion Models from Chest X-Ray Images
Nov 26, 2023
Chest X-rays (CXRs) are commonly utilized as a low-dose modality for lung screening. Nonetheless, the efficacy of CXRs is somewhat impeded, given that approximately 75% of the lung area overlaps with bone, which in turn hampers the detection and diagnosis of diseases. As a remedial measure, bone suppression techniques have been introduced. The current dual-energy subtraction imaging technique in the clinic requires costly equipment and subjects being exposed to high radiation. To circumvent these issues, deep learning-based image generation algorithms have been proposed. However, existing methods fall short in terms of producing high-quality images and capturing texture details, particularly with pulmonary vessels. To address these issues, this paper proposes a new bone suppression framework, termed BS-Diff, that comprises a conditional diffusion model equipped with a U-Net architecture and a simple enhancement module to incorporate an autoencoder. Our proposed network cannot only generate soft tissue images with a high bone suppression rate but also possesses the capability to capture fine image details. Additionally, we compiled the largest dataset since 2010, including data from 120 patients with high-definition, high-resolution paired CXRs and soft tissue images collected by our affiliated hospital. Extensive experiments, comparative analyses, ablation studies, and clinical evaluations indicate that the proposed BS-Diff outperforms several bone-suppression models across multiple metrics.
Consistency Prototype Module and Motion Compensation for Few-Shot Action Recognition (CLIP-CP$\mathbf{M^2}$C)
Dec 02, 2023Recently, few-shot action recognition has significantly progressed by learning the feature discriminability and designing suitable comparison methods. Still, there are the following restrictions. (a) Previous works are mainly based on visual mono-modal. Although some multi-modal works use labels as supplementary to construct prototypes of support videos, they can not use this information for query videos. The labels are not used efficiently. (b) Most of the works ignore the motion feature of video, although the motion features are essential for distinguishing. We proposed a Consistency Prototype and Motion Compensation Network(CLIP-CP$M^2$C) to address these issues. Firstly, we use the CLIP for multi-modal few-shot action recognition with the text-image comparison for domain adaption. Secondly, in order to make the amount of information between the prototype and the query more similar, we propose a novel method to compensate for the text(prompt) information of query videos when text(prompt) does not exist, which depends on a Consistency Loss. Thirdly, we use the differential features of the adjacent frames in two directions as the motion features, which explicitly embeds the network with motion dynamics. We also apply the Consistency Loss to the motion features. Extensive experiments on standard benchmark datasets demonstrate that the proposed method can compete with state-of-the-art results. Our code is available at the URL: https://github.com/xxx/xxx.git.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
A Probabilistic Method to Predict Classifier Accuracy on Larger Datasets given Small Pilot Data
Nov 29, 2023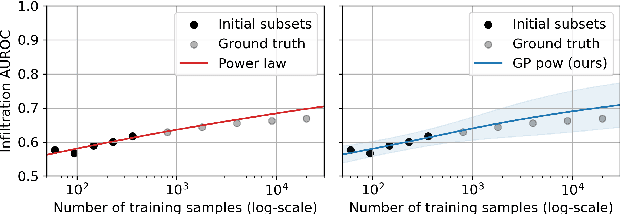

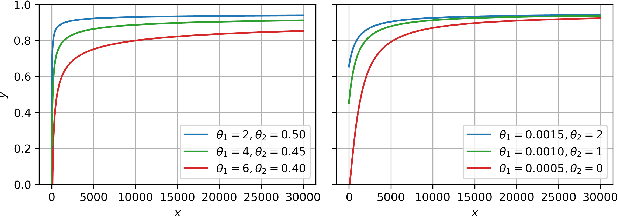
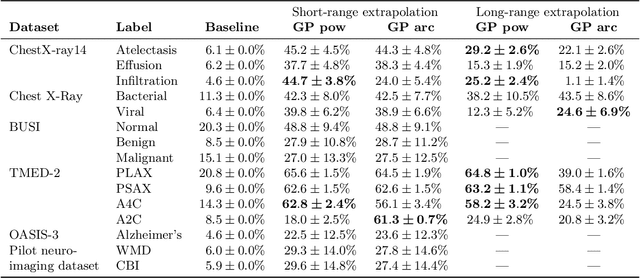
Practitioners building classifiers often start with a smaller pilot dataset and plan to grow to larger data in the near future. Such projects need a toolkit for extrapolating how much classifier accuracy may improve from a 2x, 10x, or 50x increase in data size. While existing work has focused on finding a single "best-fit" curve using various functional forms like power laws, we argue that modeling and assessing the uncertainty of predictions is critical yet has seen less attention. In this paper, we propose a Gaussian process model to obtain probabilistic extrapolations of accuracy or similar performance metrics as dataset size increases. We evaluate our approach in terms of error, likelihood, and coverage across six datasets. Though we focus on medical tasks and image modalities, our open source approach generalizes to any kind of classifier.
LICO: Explainable Models with Language-Image Consistency
Oct 15, 2023Interpreting the decisions of deep learning models has been actively studied since the explosion of deep neural networks. One of the most convincing interpretation approaches is salience-based visual interpretation, such as Grad-CAM, where the generation of attention maps depends merely on categorical labels. Although existing interpretation methods can provide explainable decision clues, they often yield partial correspondence between image and saliency maps due to the limited discriminative information from one-hot labels. This paper develops a Language-Image COnsistency model for explainable image classification, termed LICO, by correlating learnable linguistic prompts with corresponding visual features in a coarse-to-fine manner. Specifically, we first establish a coarse global manifold structure alignment by minimizing the distance between the distributions of image and language features. We then achieve fine-grained saliency maps by applying optimal transport (OT) theory to assign local feature maps with class-specific prompts. Extensive experimental results on eight benchmark datasets demonstrate that the proposed LICO achieves a significant improvement in generating more explainable attention maps in conjunction with existing interpretation methods such as Grad-CAM. Remarkably, LICO improves the classification performance of existing models without introducing any computational overhead during inference. Source code is made available at https://github.com/ymLeiFDU/LICO.
Importance of Feature Extraction in the Calculation of Fréchet Distance for Medical Imaging
Nov 22, 2023Fr\'echet Inception Distance is a widely used metric for evaluating synthetic image quality that utilizes an ImageNet-trained InceptionV3 network as a feature extractor. However, its application in medical imaging lacks a standard feature extractor, leading to biased and inconsistent comparisons. This study aimed to compare state-of-the-art feature extractors for computing Fr\'echet Distances (FDs) in medical imaging. A StyleGAN2 network was trained with data augmentation techniques tailored for limited data domains on datasets comprising three medical imaging modalities and four anatomical locations. Human evaluation of generative quality (via a visual Turing test) was compared to FDs calculated using ImageNet-trained InceptionV3, ResNet50, SwAV, DINO, and Swin Transformer architectures, in addition to an InceptionV3 network trained on a large medical dataset, RadImageNet. All ImageNet-based extractors were consistent with each other, but only SwAV was significantly correlated with medical expert judgment. The RadImageNet-based FD showed volatility and lacked correlation with human judgment. Caution is advised when using medical image-trained extraction networks in the FD calculation. These networks should be rigorously evaluated on the imaging modality under consideration and publicly released. ImageNet-based extractors, while imperfect, are consistent and widely understood. Training extraction networks with SwAV is a promising approach for synthetic medical image evaluation.
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
Nov 22, 2023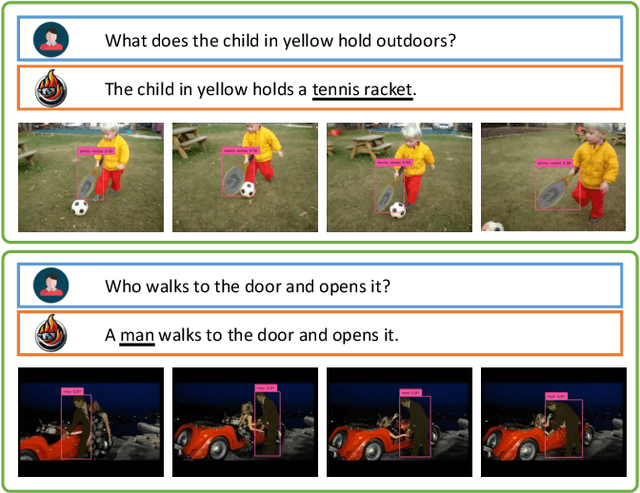
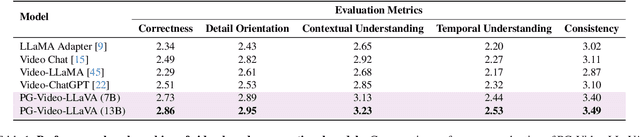
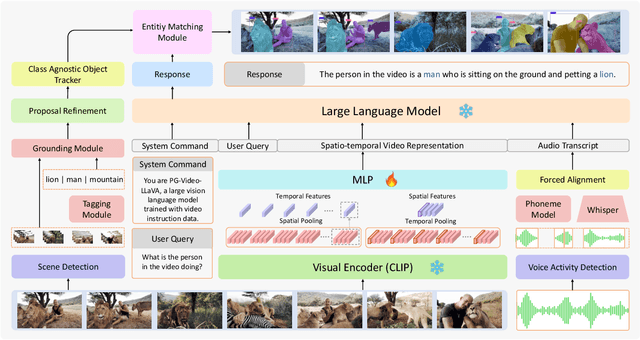

Extending image-based Large Multimodal Models (LMM) to videos is challenging due to the inherent complexity of video data. The recent approaches extending image-based LMM to videos either lack the grounding capabilities (e.g., VideoChat, Video-ChatGPT, Video-LLaMA) or do not utilize the audio-signals for better video understanding (e.g., Video-ChatGPT). Addressing these gaps, we propose Video-LLaVA, the first LMM with pixel-level grounding capability, integrating audio cues by transcribing them into text to enrich video-context understanding. Our framework uses an off-the-shelf tracker and a novel grounding module, enabling it to spatially and temporally localize objects in videos following user instructions. We evaluate Video-LLaVA using video-based generative and question-answering benchmarks and introduce new benchmarks specifically designed to measure prompt-based object grounding performance in videos. Further, we propose the use of Vicuna over GPT-3.5, as utilized in Video-ChatGPT, for video-based conversation benchmarking, ensuring reproducibility of results which is a concern with the proprietary nature of GPT-3.5. Our framework builds on SoTA image-based LLaVA model and extends its advantages to the video domain, delivering promising gains on video-based conversation and grounding tasks. Project Page: https://github.com/mbzuai-oryx/Video-LLaVA
AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort
Nov 19, 2023
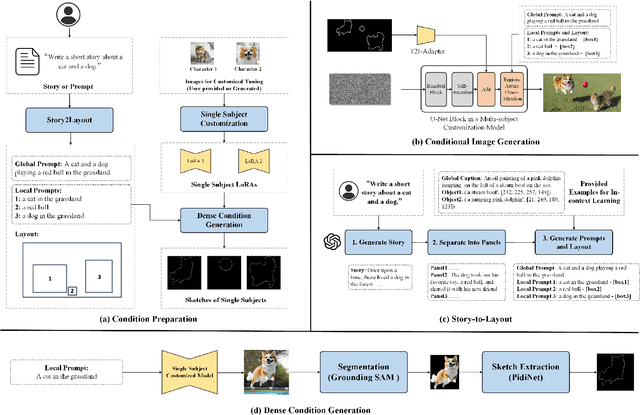

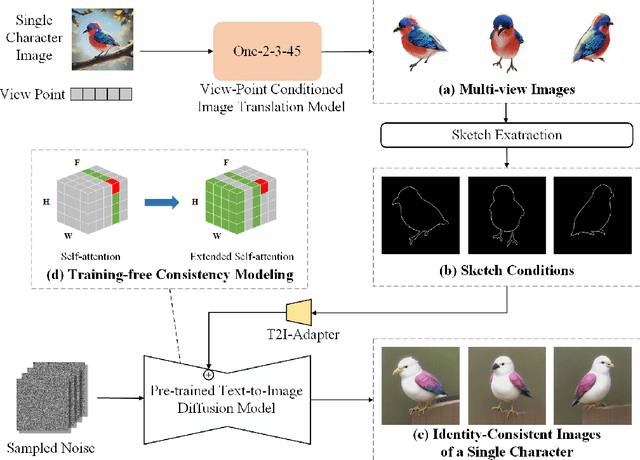
Story visualization aims to generate a series of images that match the story described in texts, and it requires the generated images to satisfy high quality, alignment with the text description, and consistency in character identities. Given the complexity of story visualization, existing methods drastically simplify the problem by considering only a few specific characters and scenarios, or requiring the users to provide per-image control conditions such as sketches. However, these simplifications render these methods incompetent for real applications. To this end, we propose an automated story visualization system that can effectively generate diverse, high-quality, and consistent sets of story images, with minimal human interactions. Specifically, we utilize the comprehension and planning capabilities of large language models for layout planning, and then leverage large-scale text-to-image models to generate sophisticated story images based on the layout. We empirically find that sparse control conditions, such as bounding boxes, are suitable for layout planning, while dense control conditions, e.g., sketches and keypoints, are suitable for generating high-quality image content. To obtain the best of both worlds, we devise a dense condition generation module to transform simple bounding box layouts into sketch or keypoint control conditions for final image generation, which not only improves the image quality but also allows easy and intuitive user interactions. In addition, we propose a simple yet effective method to generate multi-view consistent character images, eliminating the reliance on human labor to collect or draw character images.
RePoseDM: Recurrent Pose Alignment and Gradient Guidance for Pose Guided Image Synthesis
Oct 24, 2023Pose-guided person image synthesis task requires re-rendering a reference image, which should have a photorealistic appearance and flawless pose transfer. Since person images are highly structured, existing approaches require dense connections for complex deformations and occlusions because these are generally handled through multi-level warping and masking in latent space. But the feature maps generated by convolutional neural networks do not have equivariance, and hence even the multi-level warping does not have a perfect pose alignment. Inspired by the ability of the diffusion model to generate photorealistic images from the given conditional guidance, we propose recurrent pose alignment to provide pose-aligned texture features as conditional guidance. Moreover, we propose gradient guidance from pose interaction fields, which output the distance from the valid pose manifold given a target pose as input. This helps in learning plausible pose transfer trajectories that result in photorealism and undistorted texture details. Extensive results on two large-scale benchmarks and a user study demonstrate the ability of our proposed approach to generate photorealistic pose transfer under challenging scenarios. Additionally, we prove the efficiency of gradient guidance in pose-guided image generation on the HumanArt dataset with fine-tuned stable diffusion.
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.