 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffusionMat: Alpha Matting as Sequential Refinement Learning
Nov 22, 2023
In this paper, we introduce DiffusionMat, a novel image matting framework that employs a diffusion model for the transition from coarse to refined alpha mattes. Diverging from conventional methods that utilize trimaps merely as loose guidance for alpha matte prediction, our approach treats image matting as a sequential refinement learning process. This process begins with the addition of noise to trimaps and iteratively denoises them using a pre-trained diffusion model, which incrementally guides the prediction towards a clean alpha matte. The key innovation of our framework is a correction module that adjusts the output at each denoising step, ensuring that the final result is consistent with the input image's structures. We also introduce the Alpha Reliability Propagation, a novel technique designed to maximize the utility of available guidance by selectively enhancing the trimap regions with confident alpha information, thus simplifying the correction task. To train the correction module, we devise specialized loss functions that target the accuracy of the alpha matte's edges and the consistency of its opaque and transparent regions. We evaluate our model across several image matting benchmarks, and the results indicate that DiffusionMat consistently outperforms existing methods. Project page at~\url{https://cnnlstm.github.io/DiffusionMat
Few-Shot Classification & Segmentation Using Large Language Models Agent
Nov 19, 2023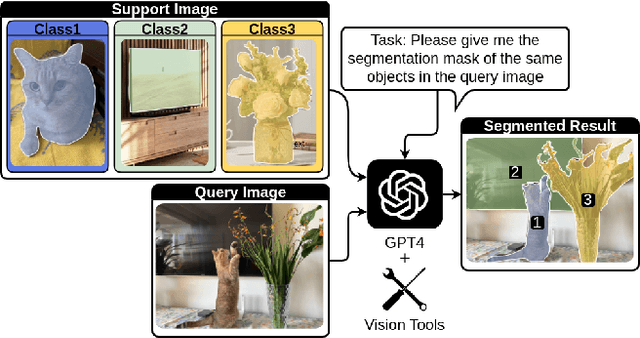
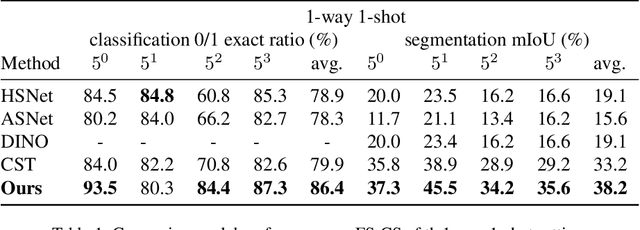
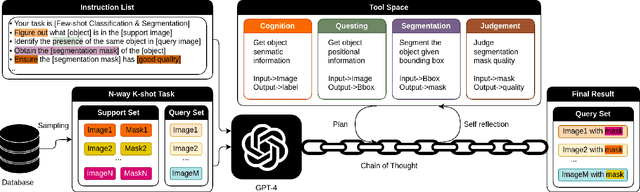

The task of few-shot image classification and segmentation (FS-CS) requires the classification and segmentation of target objects in a query image, given only a few examples of the target classes. We introduce a method that utilises large language models (LLM) as an agent to address the FS-CS problem in a training-free manner. By making the LLM the task planner and off-the-shelf vision models the tools, the proposed method is capable of classifying and segmenting target objects using only image-level labels. Specifically, chain-of-thought prompting and in-context learning guide the LLM to observe support images like human; vision models such as Segment Anything Model (SAM) and GPT-4Vision assist LLM understand spatial and semantic information at the same time. Ultimately, the LLM uses its summarizing and reasoning capabilities to classify and segment the query image. The proposed method's modular framework makes it easily extendable. Our approach achieves state-of-the-art performance on the Pascal-5i dataset.
Joint Diffusion: Mutual Consistency-Driven Diffusion Model for PET-MRI Co-Reconstruction
Nov 24, 2023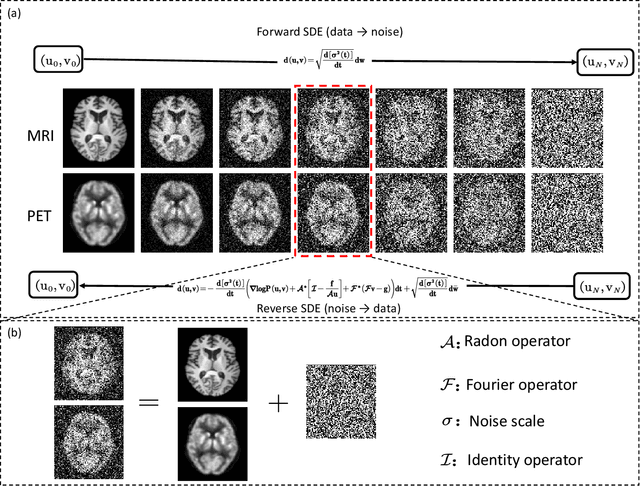
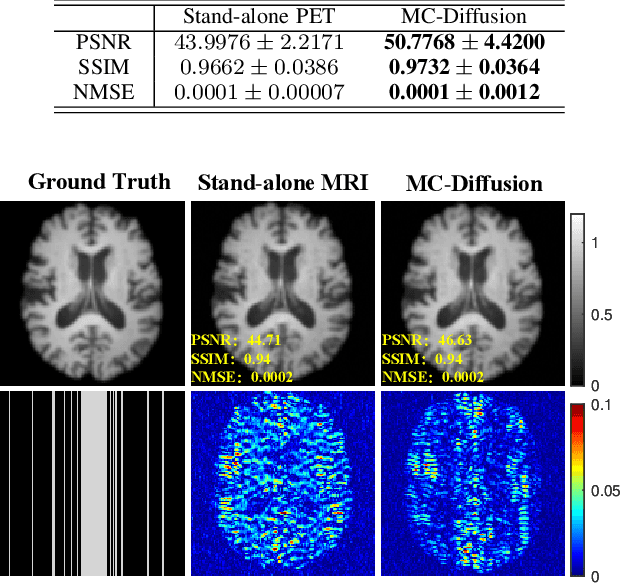
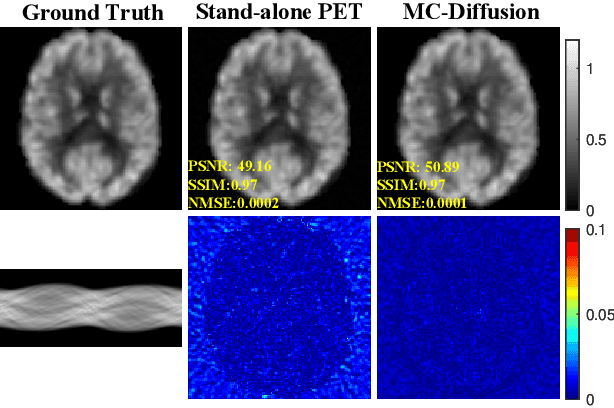
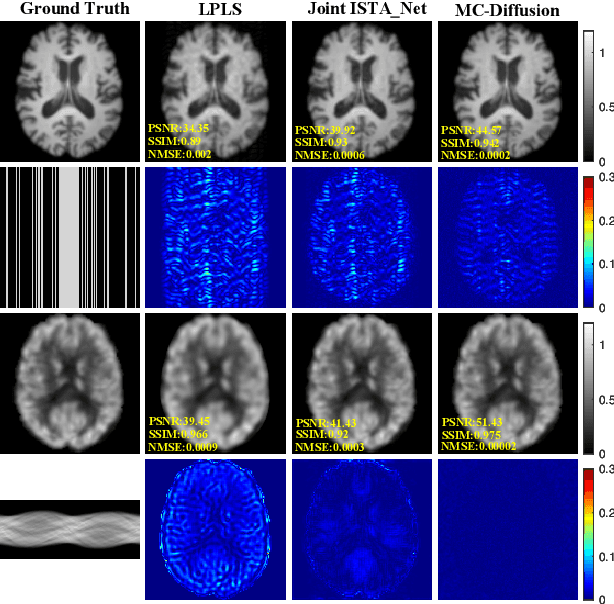
Positron Emission Tomography and Magnetic Resonance Imaging (PET-MRI) systems can obtain functional and anatomical scans. PET suffers from a low signal-to-noise ratio. Meanwhile, the k-space data acquisition process in MRI is time-consuming. The study aims to accelerate MRI and enhance PET image quality. Conventional approaches involve the separate reconstruction of each modality within PET-MRI systems. However, there exists complementary information among multi-modal images. The complementary information can contribute to image reconstruction. In this study, we propose a novel PET-MRI joint reconstruction model employing a mutual consistency-driven diffusion mode, namely MC-Diffusion. MC-Diffusion learns the joint probability distribution of PET and MRI for utilizing complementary information. We conducted a series of contrast experiments about LPLS, Joint ISAT-net and MC-Diffusion by the ADNI dataset. The results underscore the qualitative and quantitative improvements achieved by MC-Diffusion, surpassing the state-of-the-art method.
Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
Oct 16, 2023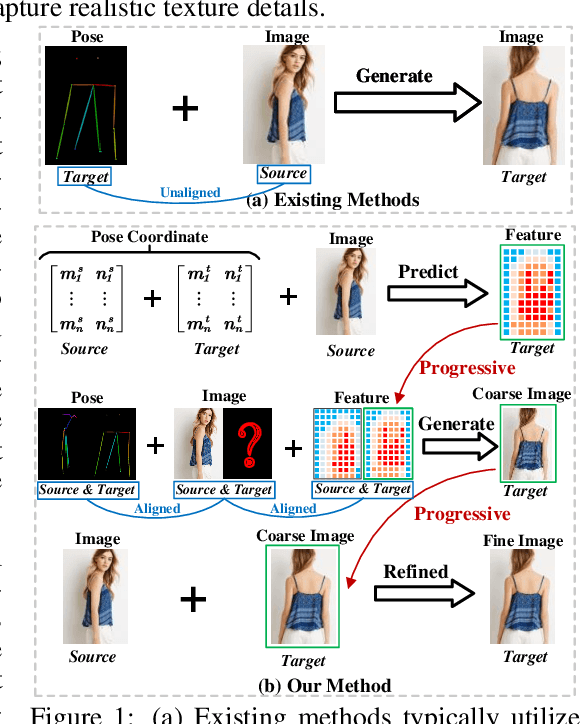
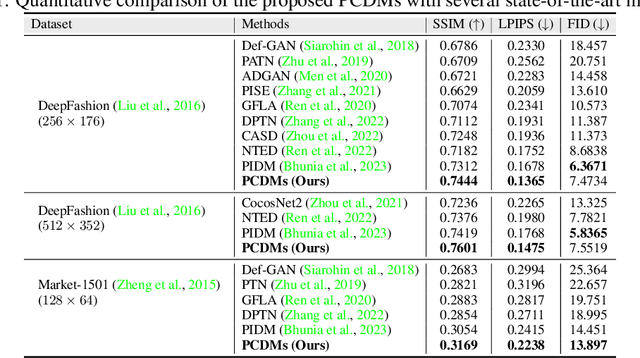
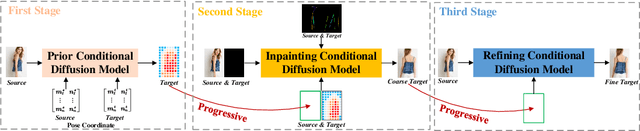
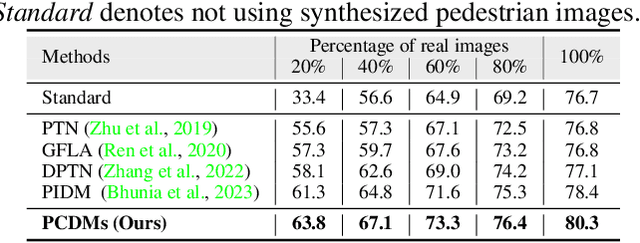
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/muzishen/PCDMs.
The curse of language biases in remote sensing VQA: the role of spatial attributes, language diversity, and the need for clear evaluation
Nov 28, 2023Remote sensing visual question answering (RSVQA) opens new opportunities for the use of overhead imagery by the general public, by enabling human-machine interaction with natural language. Building on the recent advances in natural language processing and computer vision, the goal of RSVQA is to answer a question formulated in natural language about a remote sensing image. Language understanding is essential to the success of the task, but has not yet been thoroughly examined in RSVQA. In particular, the problem of language biases is often overlooked in the remote sensing community, which can impact model robustness and lead to wrong conclusions about the performances of the model. Thus, the present work aims at highlighting the problem of language biases in RSVQA with a threefold analysis strategy: visual blind models, adversarial testing and dataset analysis. This analysis focuses both on model and data. Moreover, we motivate the use of more informative and complementary evaluation metrics sensitive to the issue. The gravity of language biases in RSVQA is then exposed for all of these methods with the training of models discarding the image data and the manipulation of the visual input during inference. Finally, a detailed analysis of question-answer distribution demonstrates the root of the problem in the data itself. Thanks to this analytical study, we observed that biases in remote sensing are more severe than in standard VQA, likely due to the specifics of existing remote sensing datasets for the task, e.g. geographical similarities and sparsity, as well as a simpler vocabulary and question generation strategies. While new, improved and less-biased datasets appear as a necessity for the development of the promising field of RSVQA, we demonstrate that more informed, relative evaluation metrics remain much needed to transparently communicate results of future RSVQA methods.
Leveraging healthy population variability in deep learning unsupervised anomaly detection in brain FDG PET
Nov 20, 2023Unsupervised anomaly detection is a popular approach for the analysis of neuroimaging data as it allows to identify a wide variety of anomalies from unlabelled data. It relies on building a subject-specific model of healthy appearance to which a subject's image can be compared to detect anomalies. In the literature, it is common for anomaly detection to rely on analysing the residual image between the subject's image and its pseudo-healthy reconstruction. This approach however has limitations partly due to the pseudo-healthy reconstructions being imperfect and to the lack of natural thresholding mechanism. Our proposed method, inspired by Z-scores, leverages the healthy population variability to overcome these limitations. Our experiments conducted on FDG PET scans from the ADNI database demonstrate the effectiveness of our approach in accurately identifying Alzheimer's disease related anomalies.
CustomNet: Zero-shot Object Customization with Variable-Viewpoints in Text-to-Image Diffusion Models
Oct 30, 2023Incorporating a customized object into image generation presents an attractive feature in text-to-image generation. However, existing optimization-based and encoder-based methods are hindered by drawbacks such as time-consuming optimization, insufficient identity preservation, and a prevalent copy-pasting effect. To overcome these limitations, we introduce CustomNet, a novel object customization approach that explicitly incorporates 3D novel view synthesis capabilities into the object customization process. This integration facilitates the adjustment of spatial position relationships and viewpoints, yielding diverse outputs while effectively preserving object identity. Moreover, we introduce delicate designs to enable location control and flexible background control through textual descriptions or specific user-defined images, overcoming the limitations of existing 3D novel view synthesis methods. We further leverage a dataset construction pipeline that can better handle real-world objects and complex backgrounds. Equipped with these designs, our method facilitates zero-shot object customization without test-time optimization, offering simultaneous control over the viewpoints, location, and background. As a result, our CustomNet ensures enhanced identity preservation and generates diverse, harmonious outputs.
CycleNet: Rethinking Cycle Consistency in Text-Guided Diffusion for Image Manipulation
Oct 19, 2023Diffusion models (DMs) have enabled breakthroughs in image synthesis tasks but lack an intuitive interface for consistent image-to-image (I2I) translation. Various methods have been explored to address this issue, including mask-based methods, attention-based methods, and image-conditioning. However, it remains a critical challenge to enable unpaired I2I translation with pre-trained DMs while maintaining satisfying consistency. This paper introduces Cyclenet, a novel but simple method that incorporates cycle consistency into DMs to regularize image manipulation. We validate Cyclenet on unpaired I2I tasks of different granularities. Besides the scene and object level translation, we additionally contribute a multi-domain I2I translation dataset to study the physical state changes of objects. Our empirical studies show that Cyclenet is superior in translation consistency and quality, and can generate high-quality images for out-of-domain distributions with a simple change of the textual prompt. Cyclenet is a practical framework, which is robust even with very limited training data (around 2k) and requires minimal computational resources (1 GPU) to train. Project homepage: https://cyclenetweb.github.io/
SingleInsert: Inserting New Concepts from a Single Image into Text-to-Image Models for Flexible Editing
Oct 12, 2023
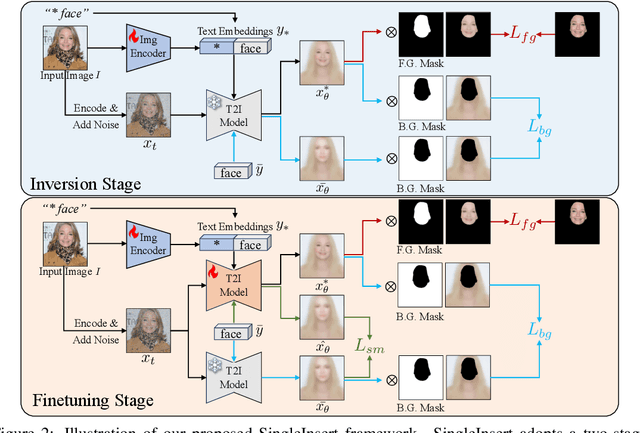


Recent progress in text-to-image (T2I) models enables high-quality image generation with flexible textual control. To utilize the abundant visual priors in the off-the-shelf T2I models, a series of methods try to invert an image to proper embedding that aligns with the semantic space of the T2I model. However, these image-to-text (I2T) inversion methods typically need multiple source images containing the same concept or struggle with the imbalance between editing flexibility and visual fidelity. In this work, we point out that the critical problem lies in the foreground-background entanglement when learning an intended concept, and propose a simple and effective baseline for single-image I2T inversion, named SingleInsert. SingleInsert adopts a two-stage scheme. In the first stage, we regulate the learned embedding to concentrate on the foreground area without being associated with the irrelevant background. In the second stage, we finetune the T2I model for better visual resemblance and devise a semantic loss to prevent the language drift problem. With the proposed techniques, SingleInsert excels in single concept generation with high visual fidelity while allowing flexible editing. Additionally, SingleInsert can perform single-image novel view synthesis and multiple concepts composition without requiring joint training. To facilitate evaluation, we design an editing prompt list and introduce a metric named Editing Success Rate (ESR) for quantitative assessment of editing flexibility. Our project page is: https://jarrentwu1031.github.io/SingleInsert-web/
Computer Vision for Increased Operative Efficiency via Identification of Instruments in the Neurosurgical Operating Room: A Proof-of-Concept Study
Dec 03, 2023Objectives Computer vision (CV) is a field of artificial intelligence that enables machines to interpret and understand images and videos. CV has the potential to be of assistance in the operating room (OR) to track surgical instruments. We built a CV algorithm for identifying surgical instruments in the neurosurgical operating room as a potential solution for surgical instrument tracking and management to decrease surgical waste and opening of unnecessary tools. Methods We collected 1660 images of 27 commonly used neurosurgical instruments. Images were labeled using the VGG Image Annotator and split into 80% training and 20% testing sets in order to train a U-Net Convolutional Neural Network using 5-fold cross validation. Results Our U-Net achieved a tool identification accuracy of 80-100% when distinguishing 25 classes of instruments, with 19/25 classes having accuracy over 90%. The model performance was not adequate for sub classifying Adson, Gerald, and Debakey forceps, which had accuracies of 60-80%. Conclusions We demonstrated the viability of using machine learning to accurately identify surgical instruments. Instrument identification could help optimize surgical tray packing, decrease tool usage and waste, decrease incidence of instrument misplacement events, and assist in timing of routine instrument maintenance. More training data will be needed to increase accuracy across all surgical instruments that would appear in a neurosurgical operating room. Such technology has the potential to be used as a method to be used for proving what tools are truly needed in each type of operation allowing surgeons across the world to do more with less.