 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mark My Words: Analyzing and Evaluating Language Model Watermarks
Dec 01, 2023
The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques - as opposed to image watermarks - and proposes a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. can watermark Llama2-7B-chat with no perceivable loss in quality in under 100 tokens, and with good tamper-resistance to simple attacks, regardless of temperature. We argue that watermark indistinguishability is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark.
On the Adversarial Robustness of Graph Contrastive Learning Methods
Nov 30, 2023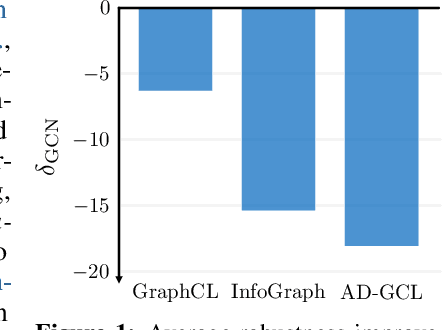
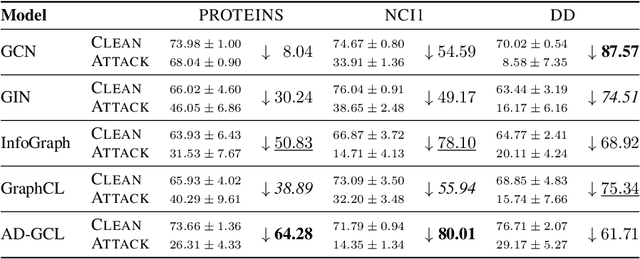
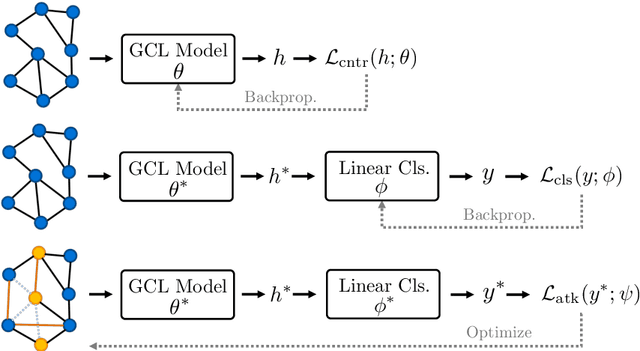
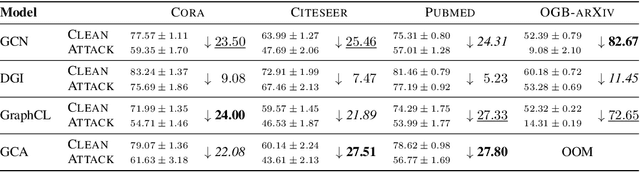
Contrastive learning (CL) has emerged as a powerful framework for learning representations of images and text in a self-supervised manner while enhancing model robustness against adversarial attacks. More recently, researchers have extended the principles of contrastive learning to graph-structured data, giving birth to the field of graph contrastive learning (GCL). However, whether GCL methods can deliver the same advantages in adversarial robustness as their counterparts in the image and text domains remains an open question. In this paper, we introduce a comprehensive robustness evaluation protocol tailored to assess the robustness of GCL models. We subject these models to adaptive adversarial attacks targeting the graph structure, specifically in the evasion scenario. We evaluate node and graph classification tasks using diverse real-world datasets and attack strategies. With our work, we aim to offer insights into the robustness of GCL methods and hope to open avenues for potential future research directions.
VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
Nov 30, 2023Diffusion models have achieved significant success in image and video generation. This motivates a growing interest in video editing tasks, where videos are edited according to provided text descriptions. However, most existing approaches only focus on video editing for short clips and rely on time-consuming tuning or inference. We are the first to propose Video Instruction Diffusion (VIDiff), a unified foundation model designed for a wide range of video tasks. These tasks encompass both understanding tasks (such as language-guided video object segmentation) and generative tasks (video editing and enhancement). Our model can edit and translate the desired results within seconds based on user instructions. Moreover, we design an iterative auto-regressive method to ensure consistency in editing and enhancing long videos. We provide convincing generative results for diverse input videos and written instructions, both qualitatively and quantitatively. More examples can be found at our website https://ChenHsing.github.io/VIDiff.
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Dec 03, 2023

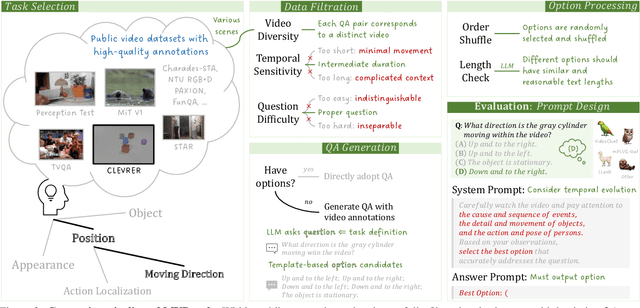

With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
Image Prior and Posterior Conditional Probability Representation for Efficient Damage Assessment
Oct 26, 2023It is important to quantify Damage Assessment (DA) for Human Assistance and Disaster Response (HADR) applications. In this paper, to achieve efficient and scalable DA in HADR, an image prior and posterior conditional probability (IP2CP) is developed as an effective computational imaging representation. Equipped with the IP2CP representation, the matching pre- and post-disaster images are effectively encoded into one image that is then processed using deep learning approaches to determine the damage levels. Two scenarios of crucial importance for the practical use of DA in HADR applications are examined: pixel-wise semantic segmentation and patch-based contrastive learning-based global damage classification. Results achieved by IP2CP in both scenarios demonstrate promising performances, showing that our IP2CP-based methods within the deep learning framework can effectively achieve data and computational efficiency, which is of utmost importance for the DA in HADR applications.
Cut-and-Paste: Subject-Driven Video Editing with Attention Control
Nov 20, 2023
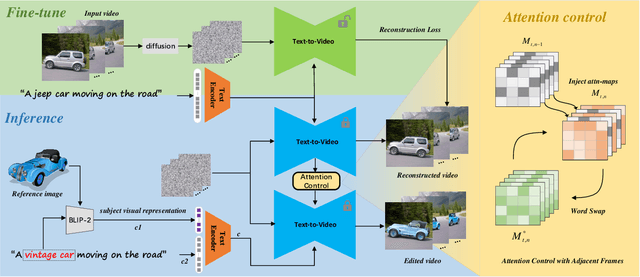


This paper presents a novel framework termed Cut-and-Paste for real-word semantic video editing under the guidance of text prompt and additional reference image. While the text-driven video editing has demonstrated remarkable ability to generate highly diverse videos following given text prompts, the fine-grained semantic edits are hard to control by plain textual prompt only in terms of object details and edited region, and cumbersome long text descriptions are usually needed for the task. We therefore investigate subject-driven video editing for more precise control of both edited regions and background preservation, and fine-grained semantic generation. We achieve this goal by introducing an reference image as supplementary input to the text-driven video editing, which avoids racking your brain to come up with a cumbersome text prompt describing the detailed appearance of the object. To limit the editing area, we refer to a method of cross attention control in image editing and successfully extend it to video editing by fusing the attention map of adjacent frames, which strikes a balance between maintaining video background and spatio-temporal consistency. Compared with current methods, the whole process of our method is like ``cut" the source object to be edited and then ``paste" the target object provided by reference image. We demonstrate that our method performs favorably over prior arts for video editing under the guidance of text prompt and extra reference image, as measured by both quantitative and subjective evaluations.
Set Features for Anomaly Detection
Nov 24, 2023This paper proposes set features for detecting anomalies in samples that consist of unusual combinations of normal elements. Many leading methods discover anomalies by detecting an unusual part of a sample. For example, state-of-the-art segmentation-based approaches, first classify each element of the sample (e.g., image patch) as normal or anomalous and then classify the entire sample as anomalous if it contains anomalous elements. However, such approaches do not extend well to scenarios where the anomalies are expressed by an unusual combination of normal elements. In this paper, we overcome this limitation by proposing set features that model each sample by the distribution of its elements. We compute the anomaly score of each sample using a simple density estimation method, using fixed features. Our approach outperforms the previous state-of-the-art in image-level logical anomaly detection and sequence-level time series anomaly detection.
Image Compression using only Attention based Neural Networks
Oct 17, 2023In recent research, Learned Image Compression has gained prominence for its capacity to outperform traditional handcrafted pipelines, especially at low bit-rates. While existing methods incorporate convolutional priors with occasional attention blocks to address long-range dependencies, recent advances in computer vision advocate for a transformative shift towards fully transformer-based architectures grounded in the attention mechanism. This paper investigates the feasibility of image compression exclusively using attention layers within our novel model, QPressFormer. We introduce the concept of learned image queries to aggregate patch information via cross-attention, followed by quantization and coding techniques. Through extensive evaluations, our work demonstrates competitive performance achieved by convolution-free architectures across the popular Kodak, DIV2K, and CLIC datasets.
Align before Adapt: Leveraging Entity-to-Region Alignments for Generalizable Video Action Recognition
Nov 27, 2023Large-scale visual-language pre-trained models have achieved significant success in various video tasks. However, most existing methods follow an "adapt then align" paradigm, which adapts pre-trained image encoders to model video-level representations and utilizes one-hot or text embedding of the action labels for supervision. This paradigm overlooks the challenge of mapping from static images to complicated activity concepts. In this paper, we propose a novel "Align before Adapt" (ALT) paradigm. Prior to adapting to video representation learning, we exploit the entity-to-region alignments for each frame. The alignments are fulfilled by matching the region-aware image embeddings to an offline-constructed text corpus. With the aligned entities, we feed their text embeddings to a transformer-based video adapter as the queries, which can help extract the semantics of the most important entities from a video to a vector. This paradigm reuses the visual-language alignment of VLP during adaptation and tries to explain an action by the underlying entities. This helps understand actions by bridging the gap with complex activity semantics, particularly when facing unfamiliar or unseen categories. ALT achieves competitive performance and superior generalizability while requiring significantly low computational costs. In fully supervised scenarios, it achieves 88.1% top-1 accuracy on Kinetics-400 with only 4947 GFLOPs. In 2-shot experiments, ALT outperforms the previous state-of-the-art by 7.1% and 9.2% on HMDB-51 and UCF-101, respectively.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.